AmiVoice APIアップデート解説 End-to-End対応の「単語強調」機能
AmiVoiceAPIがEnd-to-End音声認識1でもユーザー辞書登録2に対応しました。
この記事ではその概要と使い方を解説します。
ご好評いただいているユーザー辞書登録ですが、今まではハイブリッド型音声認識のみで利用可能となっていました。End-to-End音声認識におけるユーザー辞書登録には技術的ハードルがあり、一般的にはハイブリッド型音声認識のユーザー辞書登録よりも効果が出にくいものとなっています。その点を改善するためのAmiVoiceの技術的工夫についても解説します。
汎用的な語彙を扱うシーンにおいてEnd-to-End音声認識は強力な選択肢の一つです。ぜひご活用ください。
TL;DR
- End-to-End音声認識で認識結果に出したい単語を登録する機能を「単語強調」と呼ぶ
- 動作原理と細かい挙動が異なるが、ハイブリッド型音声認識の「単語登録」と同じ用途に使える
- 表記だけの登録で使える
- クラスの概念がない
- 効き方の強さを単語単位で調整できる
目次
- TL;DR
- 目次
- なにそれ
- ハイブリッド型の単語登録と何が違うのか
- 使い方
- 表記
- 代替表記
- 単語強調度
- TIPS
- 代替表記に読み仮名を指定する
- 単語強調度を設定する
- 繰り返す誤認識を代替表記に設定する
- 出てほしい単語を代替表記に設定しない
- 同じ代替表記に対して異なる表記を指定しない
- 同じ表記に対して異なる単語強調度を設定しない
- クラスが使えないがどうしたらいいか?
- 短すぎる単語や同音異義語のある単語を登録しない
- たくさん登録しすぎない
- 結局ハイブリッド型とどちらがいいのか?
- 参考
なにそれ
従来のハイブリッド型音声認識で用いられるような手法の単語登録機能は、End-to-End音声認識では仕組み上不可能です。
そこで、異なる手法を用いた代替機能が盛んに研究開発されています。
アドバンスト・メディアでもこの開発を行い提供中です。当社ではこれを「単語強調」と呼んでハイブリッド型音声認識の単語登録と区別しています。
ハイブリッド型の単語登録と何が違うのか
「単語を登録して出やすくする」という用途だけ見れば全く同じと言えます。マイページ上も、ユーザー辞書登録として単語登録と同列にまとめています。しかし仕組みが異なるので使い方が異なります。
めちゃくちゃ雑に言うと、E2E型の音声認識はブラックボックス的ゆえスコア計算への介入に使える情報の種類が少ない、ということになります。
詳細
どういうことなのかもう少し詳しくみてみましょう(やや専門的な話になります)。

音声認識では複数の候補の蓋然性をスコアリングして比較し最終的な出力を決定するわけですが、ハイブリッド型でもE2E型でも登録した単語を含む候補のスコアに介入して上方修正する点は同様です。
しかし、ハイブリッド型はE2E型と異なりいくつかのモジュールが協働する形でスコアリングをしています。たとえば、音声から言葉の読みと表記を推定する音響モデル+発音辞書と、その言葉の並びの妥当性を推定する言語モデルは別のモジュールです。このため処理過程で明示的に読みの情報が扱われるフェーズがあり、ユーザーが登録した読みを使ってスコア計算に介入できるわけです。また、AmiVoiceのように言語モデルにクラス3を学習させておけば、ユーザーが登録したクラスを加味したスコア計算ができます。
一方のE2E型は、音声入力から直接文字列を返す一体型家電みたいなものです。明示的に読みやクラスといった情報を扱う設計になっていません。よってそうした情報を使ってスコア計算に介入することはできません。
この介入するチャンスの少なさはハードルになり得ます。
E2E型では指定した文字列を含む候補のスコアに直接的に下駄を履かせるようなシンプルな実装が一般的で、AmiVoiceでもその点は同様です。そのため、せっかく登録した単語がそもそも候補として検討されず効かないというケースが発生しやすくなっています。特にクラスによる抽象化がない分、ピンポイントにその単語が候補に上がってくれる必要があります。後述するように、この対策として新たな設定値が用意されています。
また、こうした弱点を補った改良版の研究開発が進んでおり、近日提供予定となっています。
かなり省略的な説明となりましたが、
単語登録の仕組みやハイブリッド型とE2E型の仕組みの違いについては別の記事で解説されていますので興味のある方は覗いてみてください。
使い方
「表記」、「代替表記」、「単語強調度」の三つを設定可能です。
必須パラメータは表記のみで、ただ単に出て欲しい単語を表記に設定して登録するだけで使うことができます。日本語の場合は読み仮名をカタカナで代替表記に登録することを推奨します。
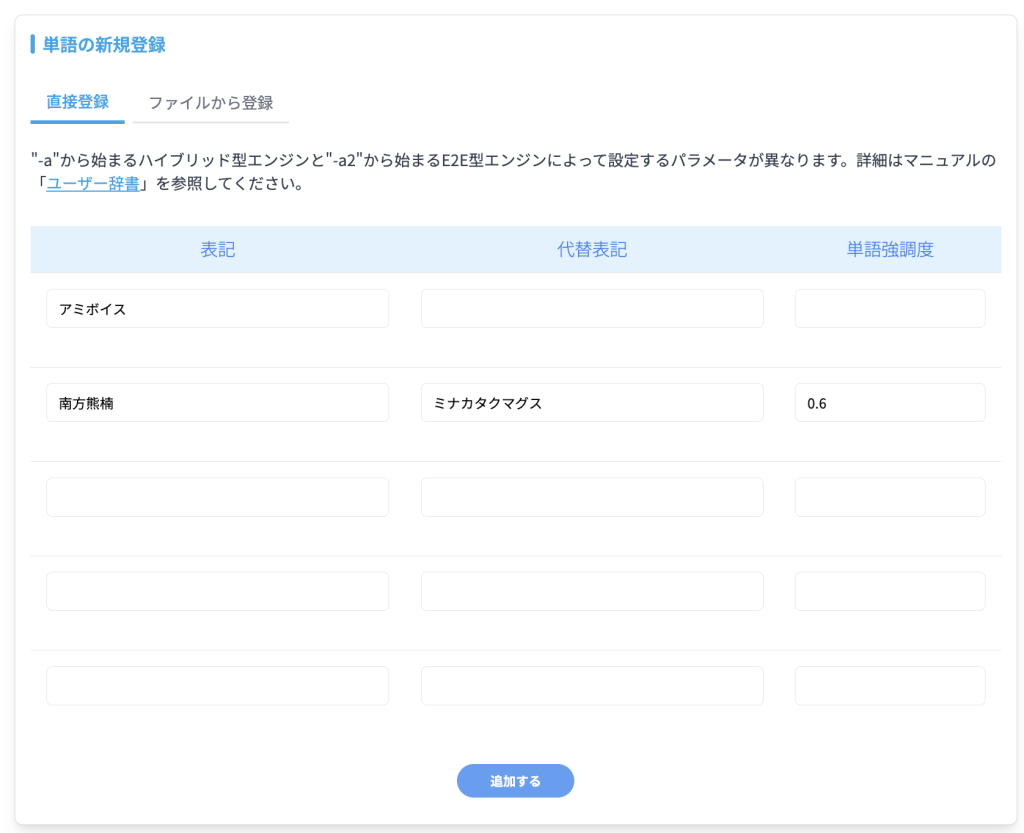
表記
認識結果に出てほしい単語の表記を設定します。ハイブリッド型音声認識の単語登録と同様です。
代替表記
認識させたい文字列と発音が近い文字列をここに指定し、本来出てほしい表記に置き換えて出させることができます。省略可能な項目です。
外来語や固有名詞に対して特に有効です。日本語の場合は後述の通り読み仮名を指定すると効果的です。
注意点として、下記補足の通り代替表記に設定した文字列も強調されます。意図しない作用が出てしまう場合は単語強調度による調整を検討してください。
補足
疑問が生じやすいのはこのパラメータかと思います。
ここに指定した文字列が認識結果の候補に含まれる場合以下の二つが起こります。これによって上記のような働きをしています。
- 表記と同じようにこの文字列を含む候補のスコアを上げる
- この文字列が表記で置換される
仕組み説明の部分で触れたように、単語強調はその単語がもともと認識結果候補として検討されなかった場合には効いてくれません。その救済のための機能と考えると理解しやすいです。
表記に登録した文字列が候補になくとも似た他の文字列が出てくれていれば、そちらを拾った上で表記の値で置換して出力することで補えます。表記だけだと一点張りしかできないところ、待つ出目を増やせるわけです。
単語強調度
どのくらい強く音声認識スコアを底上げするか数値で設定します。0から1までの数値を設定可能で、数値が大きいほどその単語が認識結果に出やすくなります。表記一つ一つに対する設定で、紐づいている代替表記も対象です。省略可能な項目です。
迷う場合は無指定でOKです。無指定の場合0.5として扱われます。
0は強調なしを意味します。
1は最大値ですが100%出るというようなものではなく、おかしな結果にならない範囲で程々に強めの強調がかかります。
TIPS
代替表記に読み仮名を設定する
日本語の場合、ここに読み仮名を指定することで一般的ではない言葉や造語なども認識しやすくすることができます。カタカナの方が効きやすいので、カタカナ推奨です。
(本来は読み仮名ではなく「認識させたい文字列と発音が近い文字列」を設定する項目ですが、カタカナ表記もそれに該当するため、このような使い方が可能です)
例:

単語強調度を設定する
意図しないところで登録した単語が出てしまう場合は下げ、登録した単語が出にくい場合は上げてみてください。
繰り返す誤認識を代替表記に設定する
読み仮名を代替表記に登録し単語強調度を調整しても認識結果に出てくれない場合は、その表記も読み仮名も認識結果候補として検討されず強調が効いていない可能性があります。特に同じ誤認識が何度も発生する場合、代わりにその文字列を代替表記として設定すれば強調が働くことを期待できます。
この使い方をする場合、単語強調度を低めに設定すると副作用を抑えることができます。
例:
例えば、アミボイスという単語を登録しても認識されず、「亜魅母威酢」のような誤認識をしていると仮定します。このとき、代替表記に「亜魅母威酢」を登録するイメージです。

↓

出てほしい単語を代替表記に設定しない
代替表記は表記に置き換わるため、代替表記に指定した文字列は基本的に認識結果に出ることがなくなります(単語強調度に関係なく置換が発生します)。よって、文脈次第で出てほしいような文字列を指定しないようにしましょう。
NG例:
たとえば「モース硬度」が「マウスコード」と誤認識されるときに、マウスコードを代替表記に設定してしまった場合を考えてみましょう。この時、実際にマウスコードと発話してもモース硬度という認識結果になってしまいます。

逆にこれを利用して出したくない単語を抑制することも考えられます。この場合は置換だけを行わせたいので、出したくない単語に余計な強調がかからないよう単語強調度を低い値に設定すると良いでしょう。なお、100%出なくなるわけではありません。
例:

同じ代替表記に対して異なる表記を指定しない
そのような登録があると、代替表記をどの表記に変換したらいいかわからない状態になります。実際の動作としてはどれか一つだけが有効になりますが、挙動を予想しにくくなってしまいますので避けた方がよいです。
NG例:

同じ表記に対して異なる単語強調度を設定しない
データ構造としては表記が登録の基本単位となっており、それに対して一つの単語強調度と複数の代替表記が対応する形です。APIやUIの都合上、表記が同じであっても代替表記ごとに一つずつ登録する形ですが、それぞれ異なる単語強調度を指定した場合はどれか一つの値だけが採用されます。
NG例:

OK例:

クラスが使えないがどうしたらいいか?
対応する機能はありません。言い換えれば、文脈などの判断は全て音声認識デコーダに任せて何もしなくて良いという考え方になります。
短すぎる単語や同音異義語のある単語を登録しない
これはハイブリッド型の場合と同じです。
例えば「はし」という代替表記および「橋」という表記を指定してしまうと、「端」や「箸」、「走る」などの場合も「橋」が出てしまいます。
たくさん登録しすぎない
これもハイブリッド型の場合と同様です。まずは1,000語以内を目安に、多くとも数千単語程度に抑えるようにするとよいです。
結局ハイブリッド型とどちらがいいのか?
多数の専門用語や固有名詞が発話されるユースケースやクラスを使いたい場合はハイブリッド型のエンジンモードをご検討ください。
参考
- ハイブリッド型とEnd-to-End型の仕様の差異などについてはこちら。
https://docs.amivoice.com/amivoice-api/manual/engines/#difference-between-end-to-end-and-hybrid ↩︎ - 今回のリリースに伴い、このような機能の総称をユーザー辞書登録と改めました。ハイブリッド型の「単語登録」とE2E型の「単語強調」をまとめてユーザー辞書登録と呼称します。 ↩︎
- 単語の種類による抽象化のことです。例えば人名や地名など。
https://acp.amivoice.com/blog/2022-01-13-101135/#%E5%8D%98%E8%AA%9E%E7%99%BB%E9%8C%B2%E3%81%AE%E3%82%AF%E3%83%A9%E3%82%B9%E3%81%A8%E3%81%AF ↩︎
この記事を書いた人
-

小林 幹康
アプリケーション開発をしています。
動物の音声コミュニケーションへの興味がきっかけで音声認識の会社を選びました。
自然観察と旅行、パズル、ゲームなどが好きです。ChatGPTが人生最多の雑談相手になった気がしています。
よく見られている記事



新着記事
-
AmiVoice API アップデート解説 ボイスボット向け新パラメータで応答待ち時間を短縮

-
AmiVoice APIアップデート解説 End-to-End対応の「単語強調」機能

-
動画に字幕を簡単合成!音声認識APIで作る字幕ワークフロー

カテゴリ一覧
アーカイブ
