ハイブリッド型音声認識とEnd-to-End音声認識の違いと特徴

 柴田駿人
柴田駿人
深層学習の発展により音声認識の精度は飛躍的に向上し、更にはすべてニューラルネットワークで構成された新たな音声認識システムが登場しました。本記事では新しい方式と従来の方式のメリットやデメリットについて解説します。
- 従来の「ハイブリッド型」と近年台頭してきた「End-to-End」
- End-to-Endはシンプルな音声認識システム
- End-to-Endの弱点(アダプテーションが難しい)
- ハイブリッド型とEnd-to-Endの作り方の違い
- AmiVoiceはハイブリッド型?End-to-End?
従来の「ハイブリッド型」と近年台頭してきた「End-to-End」
音声認識では長らく音響モデル、言語モデル、発音辞書を使って音声認識を行う方法が主流でした。音響モデルにはDNN(Deep Neural Network)とHMM(Hidden Markov Model; 隠れマルコフモデル)を組み合わせるハイブリッド型が用いられるのでこの音声認識システムをハイブリッド型音声認識と呼ぶことにします。音響モデルは各時刻の音声について音響スコアを計算し、発音辞書が音素と単語を結びつけ、言語モデルが単語列に対して言語スコアを計算します。音響スコアと言語スコアを重みつきで足し合わせたスコアが最も高いものを認識結果として出力します。
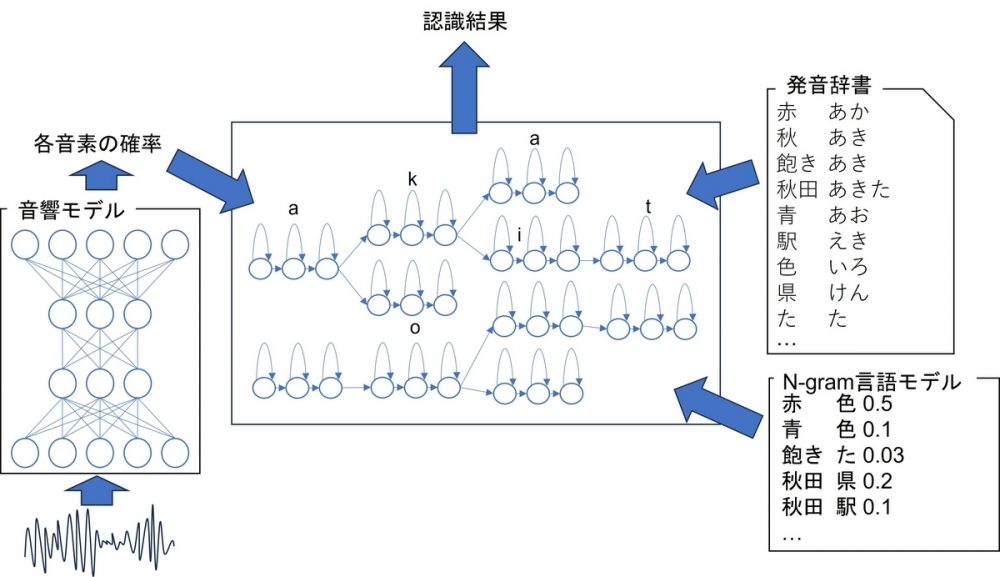
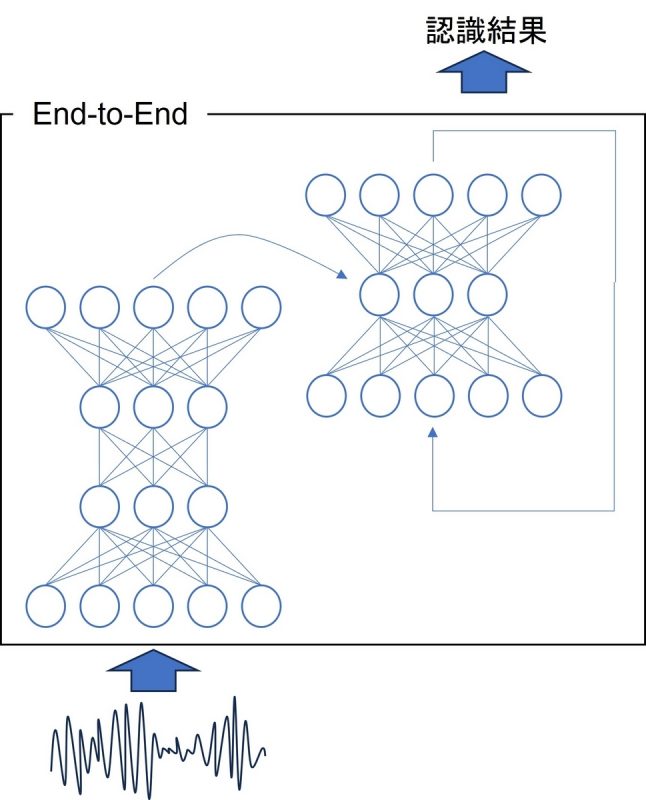
これに対して近年、単一のニューラルネットワークで音声認識をするEnd-to-End音声認識が台頭してきています。End-to-Endでは音声を入力として文字あるいはサブワードのスコアを出力し、最もスコアの高い文字列(サブワード列)を認識結果として出力します。
音声認識システムのより具体的な内容については以前の記事をご参照ください。
AmiVoice Cloud Platform-Tech Blog
End-to-Endはシンプルな音声認識システム
ハイブリッド型は個別のモジュールを組み合わせながらデコードするためとても複雑な仕組みになっています。学習においては音響モデルだけでも音素のクラスタリング、音素アライメントの作成、ニューラルネットワークの学習などたくさんのステップがあります。一方でEnd-to-Endは単一のニューラルネットワークなのでとてもシンプルです。学習も発音辞書を必要とせず、音声とその書き起こしを使ってニューラルネットワークの学習をするだけで音声認識システムができます。このためEnd-to-Endは開発がしやすいというメリットがあります。
End-to-Endの弱点(アダプテーションが難しい)
ハイブリッド型とEnd-to-Endはどちらも音声をテキストに変換することに変わりはないため、汎用な認識をする場合どちらを使っても問題ありません。しかし特定のタスクで使いたい場合、固有名詞や専門用語などが認識できなかったり意図した認識結果になりづらいことも多いため、アダプテーションをして認識できるようにする必要があります。実際に世の中の多くの音声認識サービスでアダプテーションや単語登録の機能が備わっており、必須の機能となっています。
ハイブリッド型の場合、認識結果には発音辞書に含まれている単語しか出てこないので、認識したい単語が発音辞書にない場合は追加することが必須です。単語追加は発音辞書に単語とその読みを登録するだけで簡単に行えます。単語追加に加えて、ハイブリッド型音声認識ではタスクにあった言語モデルを使うことが重要になるため、テキストデータを集めて言語モデルをアダプテーションすることで認識精度の向上が見込めます。テキストデータは集めやすく、言語モデルのアダプテーションは比較的短時間で行えるためハイブリッド型はアダプテーションしやすい方式となっています。
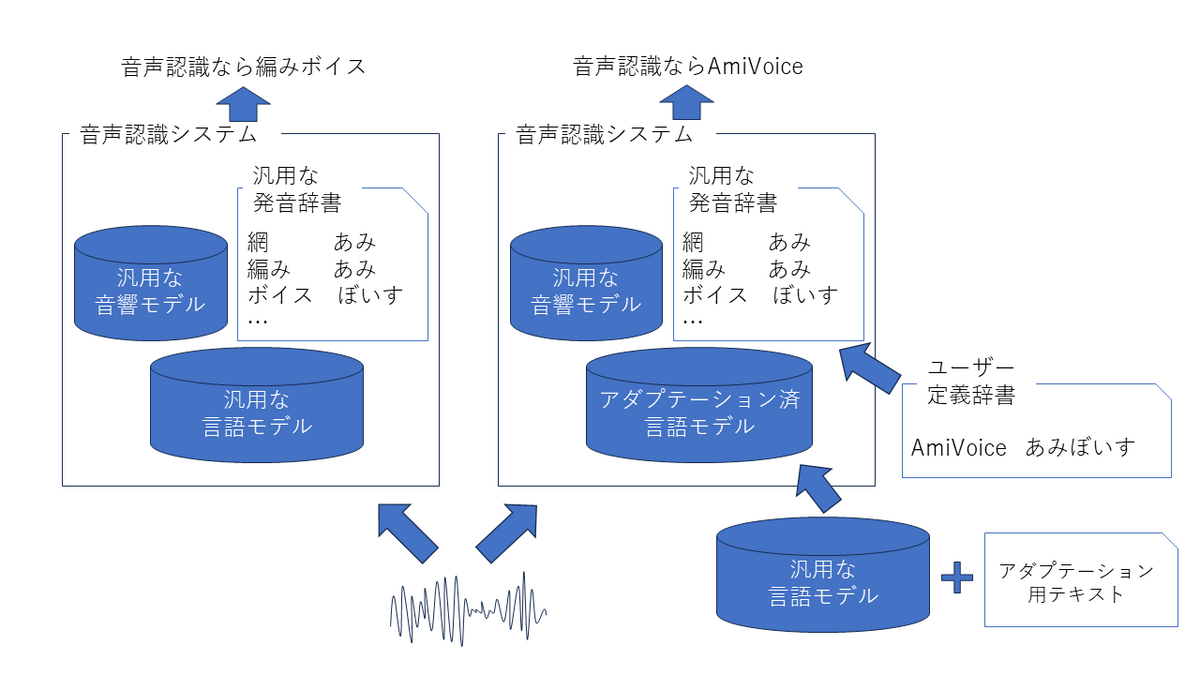
一方でEnd-to-Endでは発音辞書を持たないので簡単に単語を追加するということができません。単一のニューラルネットワークであるため、基本的には認識させたい単語を含む音声とその書き起こしを使って再学習させる必要があります。テキストだけでアダプテーションができるハイブリッド型と比べて音声も必要となるためデータ収集はとても大変です。またニューラルネットワークの学習は言語モデルのアダプテーションと比較してとても時間がかかります。このような課題については研究が盛んに行われていますが未だ実用化には至っておらず、End-to-Endはアダプテーションが難しい方式となっています。
ハイブリッド型とEnd-to-Endの作り方の違い
データ準備
End-to-Endの学習には音声とその書き起こしのみが必要であり、したがって学習データの準備は人手による書き起こしを行うだけで済みます。一方でハイブリッド型では音声の書き起こしだけでなく、発音辞書も作成する必要があります。発音辞書の作成ではまず音素体系を定め、その音素体系に従ってあらゆる単語の読みを振ることで作成します。音声の書き起こしのみであれば音声を聞き取れる人ならできますが、発音辞書の作成では言語的な知識も必要となるため非常に手間がかかります。
必要なデータ量
一般的に学習に必要なデータ量はEnd-toEndの方が多く、ハイブリッド型では数百時間以上、End-to-Endでは数千時間以上のデータが必要になります。ハイブリッド型ではタスク特化(領域特化)の音声認識を行うことも可能ですが、End-to-Endでは特定のタスクから音声を大量に集めることが困難であるため汎用な音声認識として開発することが多いです。
パラメータ調整
ハイブリッド型では音響モデル、言語モデル、発音辞書を組み合わせながら認識するため、最適な組み合わせ方を見つけなければなりません。たくさんあるパラメータを手作業で調整する必要があり、ノウハウが求められます。End-to-Endでは単一のニューラルネットワークなので手動で調整するパラメータが少なく最適化がしやすいというメリットがあります。
| ハイブリッド型 | End-to-End | |
|---|---|---|
| 構成要素 | 音響モデル 言語モデル 発音辞書 |
単一のモデル |
| 用途 | 汎用 タスク特化 |
汎用 |
| アダプテーション | 容易 | 困難 |
| 学習データ | 数百時間~ | 数千時間~ |
| 外国語音声認識の開発 | 困難 | 容易 |
| パラメータ調整 | 困難 | 容易 |
AmiVoiceはハイブリッド型?End-to-End?
ハイブリッド型、End-to-Endにはそれぞれメリット・デメリットがありますが、製品化するにあたってはアダプテーションのしやすさが重要になります。特に個別のお客様向けの音声認識では意図した認識結果を得られることが求められます。そのため現在でもアドバンスト・メディアの製品ではアダプテーションしやすいハイブリッド型音声認識を主流に扱っています。
特に日本語については長年蓄積した知見があり、細かくパラメータ調整ができるハイブリッド型の方が反映させやすいという側面もあります。一方であまり知見のない言語の音声認識ではEnd-to-Endの利用に積極的に取り組んでいます。
アドバンスト・メディアにおける研究開発ではハイブリッド型、End-to-Endのどちらも行っています。End-to-Endで使われるモデルの構造や学習手法を取り入れることでハイブリッド型の認識精度改善を実現したりと、新しい方式だけでなく従来の音声認識システムも進歩を遂げています。
今後もアドバンスト・メディアでは状況に応じて適切に技術の使い分けを行い、最適と思われる音声認識エンジンを提供します。AmiVoice APIは最新のエンジンを毎月60分無料でご利用いただけます。是非お試しください。
この記事を書いた人
-
柴田駿人
音声認識の研究開発をしています。
よく見られている記事



新着記事
-
AmiVoice APIアップデート解説 End-to-End対応の「単語強調」機能

-
動画に字幕を簡単合成!音声認識APIで作る字幕ワークフロー

-
AmiVoiceの単語登録APIで音声認識をもっと自由に!

カテゴリ一覧
アーカイブ
