音声認識を使ったシステム開発の前提条件<前編>ー開発ノウハウシリーズ1ー

みなさま、こんにちは。
音声認識システム開発時にあたり、「音声認識サービスを開発したいけど、認識精度が不安」
「ユーザーに上手く音声認識を使ってもらうためにシステム側で制御できないだろうか」といった悩みはありませんか?
今回は、音声認識開発前に知っておくと役に立つ知識についてシリーズで解説していきます。
第一回目は「音声認識の前提条件」を2回に分けて詳しく説明します。
本記事は、過去にウェビナーにてお話した内容を記事にしたものです。
以下より動画でもご覧いただけます。
▶【動画】【開発者向け】 これだけは押さえたい!音声認識導入で失敗しないシステム開発のノウハウ(1) ー要件定義とUI・UX編ー
音声認識の前提条件 前編
1.なぜ音声認識を使うのか
音声認識を利用するにあたり、本当に音声認識を使った方がいいのかどうかはよく検討する必要があります。まずは、音声認識のメリット・デメリットを理解しておきましょう。
| 音声認識のメリット | 音声認識のデメリット |
|---|---|
| 長文ならキー入⼒より早い | 誤認識する場合がある |
| マイクがあればいい | マイクが必要 |
| 手を使わないでいい | 周りに聞こえる |
| 人手よりも安価に文字化できる | 計算量が多い(CPU負荷やサーバー代がかかる) |
入⼒手段としては音声認識よりもキーボード・マウス・タッチパネルなどの方が優れていることも多いです。また、セキュリティやコンプライアンス的に人に聞かれたら問題がある内容は、周りに人がいない状況でしか利用できないので制限されます。一方で特定の条件下では音声認識を利用したほうが便利な場合もあります。
<音声認識が有効な場合の例>
- 入⼒デバイスがマイクのみに限られる場合(電話など)
- 選択肢が膨大にある場合(映画タイトルの検索など)
- 長い文章を高速に文字化したい場合(メールの音声入⼒など)
- 大量の文章を人手よりも安価に文字化したい場合(通話や会議の文字化など)
- 手を使わずに入⼒や操作をしたい場合(倉庫作業の記録など)
以上を踏まえて、本当に音声認識を利用するべきか検討しましょう。
2.どんな内容を音声認識するか
続いて音声認識したい内容についてです。音声認識はどんなことをしゃべっても認識できるというわけではなく、内容によって難易度が変わります。
音声認識したい内容の難易度が高いと、音声認識が性能が発揮されずサービスとして成立しないこともよくありますので、事前の確認が重要になります。
<音声認識の難易度が高いもの一覧>
- 扱う話題が幅広かったり、単語が多くなるほど難易度が上がりやすい
話題が広い → 音声認識エンジンが知らない未知の単語が増える → 音声認識できない - 似た読みの単語・フレーズが多いと難易度が上がりやすい
似た読みのものは聞き間違えやすい。例えば、アルファベットや氏名は非常に難易度が高い - 多くの音声認識エンジンは一般的な内容しかカバーしていない
一般的でない内容(専門用語、固有名詞、新語など)を正確に音声認識するには、対策が必要 - 複数の言語に対応したい場合は言語識別が必要になる
例えば、タッチパネルで何語か選択させる、音声から識別可能なエンジンもある(OpenAI Whisper等)

イラストのような、「過去」「かっこ」「加工」など似た発音の単語は会話中だと音声認識されづらいです。同義語も音だけだと判断できなく、どういう文脈内で発話されたかを判断しなくてはいけなくなります。
3.音声認識エンジンの認識できる範囲
音声認識エンジンの認識できるカバー範囲を下記の図に表してみました。
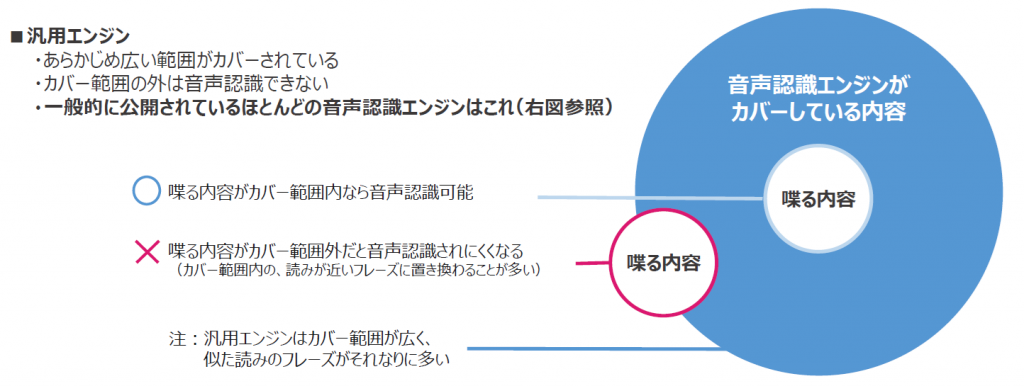
図の青い円を音声認識がカバーできる範囲とします。カバー範囲内の内容とは主に一般的な日常会話のことを意味しています。ただ、その会話の中に専門用語や独自の単語が含まれていると、図の赤い円のように部分的に範囲がはみ出す状態になります。そうすると、音声認識されなかったり、別の単語に認識してしまう可能性があります。
この赤い円のはみ出してる部分を音声認識させたいときは、単語登録や追加学習をする必要があります。単語登録とは単語の表記と読みを指定して登録すること、追加学習とは音声認識エンジンに文章を学習させることです。
ここで気を付けておきたいのは、汎用エンジンはもともと広範囲の日本語や単語を登録してあるので、更に単語登録や追加学習を行うと、似たフレーズや読みが同じ単語と間違えて判断してしまう可能性があることです。
そのような認識間違えを解決するには、あえてカバー範囲を限定する方法があります。
詳しく説明すると、必要な単語やフレーズだけを音声認識させる、音声認識が必要のない単語はエンジンに登録しないという方法です。音声認識システムの用途や認識したい発話内容が決まってる場合には、高い精度の音声認識が可能です。
<AmiVoiceの場合>
追加学習やカバー範囲を限定した音声認識エンジンを提供しています。
- 領域特化エンジン:特定の分野に特化したエンジン(医療系など)や、汎用的な語彙に様々な業界の専門用語に対応したエンジン(金融・保険など)
- 個別構築エンジン:大量のテキストから独自に構築したエンジン
- ルールグラマ:開発者が文法を定義
個別構築エンジンとルールグラマについてはご相談ください。
4.音声認識対象となる単語やフレーズによって難易度が異なる
ここまで音声認識にとって認識するのに難易度が高い会話や単語があることを説明してきました。いくつかの具体例を表にまとめましたので参考にしてください。
| 比較的難しい | 比較的簡単 | 理由・備考 |
|---|---|---|
| アルファベット | 数字 | ・アルファベットは似た発音のものが非常に多い ・数字は「いち」と「しち」など一部例外を除き似た発音は少ない |
| 不特定のアパート名・マンション名・建物名・店舗名 | ランドマーク名 | ・アパート名・マンション名などは件数が多く、ユニークなものや未知のものが多い。専用の音声認識エンジンの利用やカスタマイズが必要 ・ランドマーク名なら限定的になる。単語登録等でもカバー可能 |
| 不特定の氏名 | 有名人の名前 | ・不特定の氏名は似た発音のものが非常に多い。専用の音声認識エンジンの利用やカスタマイズが必要 ・有名人の名前なら限定的になる。単語登録等でもカバー可能 |
| 電子カルテ | 放射線読影レポート | ・読影は非常に専門的で一見難しそうだが、出現する単語やフレーズはそこまで幅広くはない。電子カルテは例えば怪我をした理由などユニークな要素があり内容の幅が広く難易度が上がる ・どちらも専用の音声認識エンジンの利用やカスタマイズが必要 |
| 非定型的な会話(⽇常会話など) | 定型的な会話(受付業務など) | ・定型的な会話は単語やフレーズが限定的になり難易度は低い ・⽇常会話はさまざまな単語・フレーズが出てくるため難易度が上がる ・どちらもデフォルトの音声認識エンジンである程度カバー可能 |
5.難易度の高い内容を音声認識したい場合どうすればいいか?
音声認識にとって解析に難易度が高い内容の会話があることをお伝えしましたが、それでも難易度が高い内容を音声認識したい場合はどのように対策すればいいのか解説していきます。
前提として100%正確に音声認識をするというのは、現在の技術では現実的ではありません。音声認識は本質的に不確実性を伴うものであり、ある程度の誤認識は避けられないという認識を持つことが重要です。その上で、以下の対策を検討します。
- 難易度の高い単語を回避する
氏名は判別が難しいので、ユーザIDを使う。ユーザIDもアルファベットは判別が難しいので数字だけにする。不特定の氏名は難しいので、あらかじめ特定可能なら、その候補の中から音声認識させる - 誤認識してもリカバリーできる仕組みを用意する
ユーザに結果を示して、間違っていたら喋り直しや修正を促す - 誤認識が許容される使い方をする
後で人が確認するようなワークフローを組む。入⼒データのバリデーションを行う。統計的な分析で使う
これらを知識として知っていると、難易度の高い内容を音声認識したい場合に役に立ちます。
音声認識の前提条件 前編まとめ
今回は音声認識の前提条件として、音声認識のメリット・デメリットや音声認識をしたい内容に難易度があること、音声認識エンジンのカバー範囲について解説していきました。これらを音声認識エンジン導入前の検討段階で理解しておくと、自社に合った音声認識エンジンの選定時や開発時の基準になると思います。
次回は、音声認識の前提条件の後編を解説します。
よく見られている記事



新着記事
-
AmiVoice API アップデート解説 ボイスボット向け新パラメータで応答待ち時間を短縮

-
AmiVoice APIアップデート解説 End-to-End対応の「単語強調」機能

-
動画に字幕を簡単合成!音声認識APIで作る字幕ワークフロー

カテゴリ一覧
アーカイブ
