音声認識されない単語は単語登録!AmiVoiceの単語登録のコツ

 安藤章悟
安藤章悟
みなさま、こんにちは。
AmiVoiceを使っていて、喋った単語が正しく音声認識されないことはありませんか?「もしかしたら自分の発音が悪いのかもしれない」と思うかもしれませんが、何度試しても音声認識されない場合はそもそも単語が登録されていない可能性があります。
そういう場合には単語登録が有効です。今回はその単語登録機能について解説します。
- はじめに
- 結論:AmiVoiceの単語登録のコツ
- 単語登録について
- 音声認識の仕組みはIMEかな漢字変換の仕組みと少し違う
- 単語登録の「クラス」とは?
- AmiVoiceの単語登録のコツの詳細
- ACPで単語登録を使う場合の補足
- さいごに
はじめに
- 今回の記事は、開発者向けサービスであるAmiVoice Cloud Platform(ACP)を前提とします。ACP以外のAmiVoice搭載製品でも基本的には同じ考え方になりますが、AmiVoice搭載製品によっては仕組みや名称が異なったり、登録可能な単語数上限や使用できない文字などの仕様が異なる場合などがありますので、あらかじめご了承ください。
- 本記事は2022年1月時点の情報です。今後音声認識エンジンのバージョンアップなどによって一部内容が変更されていく可能性がありますので、ご了承ください。
結論:AmiVoiceの単語登録のコツ
まずは最初に結論!ということで単語登録のコツを箇条書きにしました。
- 登録する単語数はできるだけ最小限に(ACPでは最大で1000単語まで)
- 「読み」が短いものは要注意(できれば1~2文字のものは避ける)
- 同じ「表記」の単語を複数登録してもOK
- 同じ「読み」の単語を複数登録しても意味がない
- 同じ「読み」の単語でも「クラス」が異なれば登録してもよい
- 「読み」は自動的に変換される
- “.”(半角ドット)を使うと細かい読みの指定ができる
- 「読み」はふりがなではでなく「どう読むか」
これらのコツの詳しい解説はこの記事の後半にやります。
少し回り道になりますが、音声認識の単語登録の仕組みについて説明しましょう。
もしも詳細な説明が不要な方は、後半まで読み飛ばして頂いて結構です
単語登録について
AmiVoiceの単語登録では、登録したい単語の「表記」と「読み」、必要に応じて「クラス」(このクラスについては後で解説します)を指定することで、音声認識エンジンに単語を登録することができます。
Microsoftのかな漢字変換にも単語登録機能がありますが、こちらは「語句」と「読み」、必要に応じて「品詞」を指定する仕組みになっています。とても似ていますね。
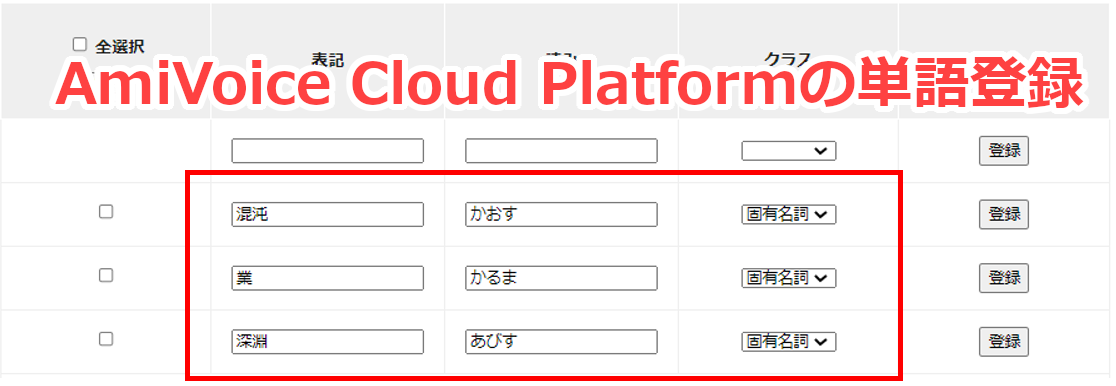
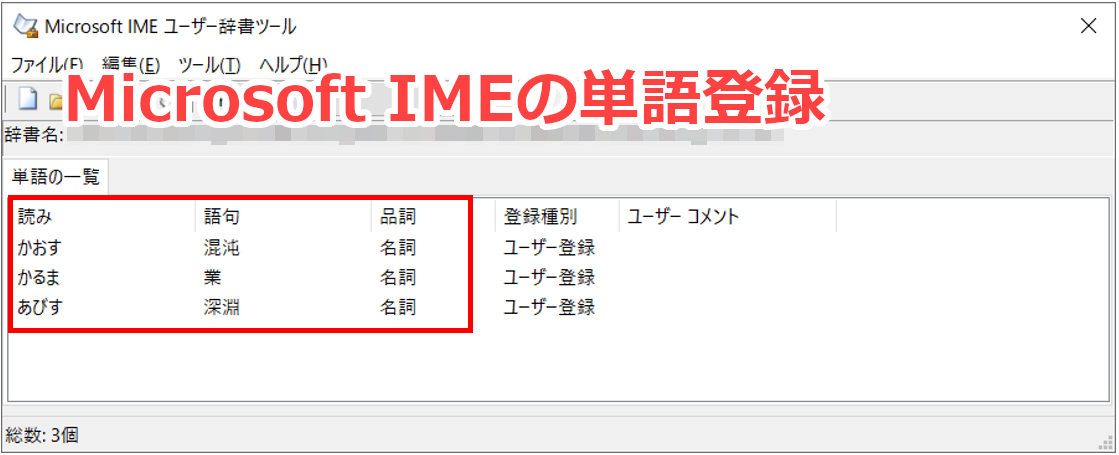
AmiVoiceもMicrosoftのかな漢字変換も単語登録機能の使い方はほとんど同じです。しかし、音声認識の場合は入力が「音声」という非常に曖昧なもののため、うまく使いこなすにはコツを押さえる必要があります。
音声認識の仕組みはIMEかな漢字変換の仕組みと少し違う
AmiVoiceの音声認識とMicrosoft等のかな漢字変換との仕組みの違いや、音声認識の難しさなどについて、こちらの記事で詳しく解説しました。
AmiVoice Cloud Platform-Tech Blog
この記事の中で「言語モデル」というものに触れています。言語モデルは「この単語はこういう単語・フレーズの前後に出やすい」という情報をまとめたデータで、音声認識結果の予測の精度を高めるために必要なものです。
例えば、”池袋” という東京の地名・駅名を例に説明しましょう。Googleで「池袋」で検索して、その結果に表示される文章をいくつかピックアップしてみました。

“池袋”という単語は、上記のような前後のフレーズに挟まれて出現していることが分かると思います。こういったデータを大量に集めて、”池袋”の周辺にどういう単語やフレーズが出現しやすいのかをモデル化したデータが言語モデルです。
通常、音声認識エンジンに登録される単語数は数万単語~数十万単語くらいになりますが、すべての単語はこのような「この単語はこういう単語・フレーズの前後に出やすい」という情報を持つことになります。
単語登録の「クラス」とは?
さて、前述の通り、AmiVoiceの音声認識エンジンに入っているすべての単語は「こういう単語・フレーズの前後に出やすい」という情報を持っているのですが、ここで問題になるのは「ユーザーが自分で登録した単語はどういう単語・フレーズの前後に出やすくなるのか?」という点です。
ここで出てくるのが「クラス」です。
単語登録の時にクラスを指定すると、そのクラスが持つ「どういう単語・フレーズの前後に出やすいのか?」という情報が使われます。
例えばACPの単語登録画面から、接続エンジン名で例えば「会話_汎用エンジン(-a-general)」を指定すると、下記のようなクラスが選べるようになります。
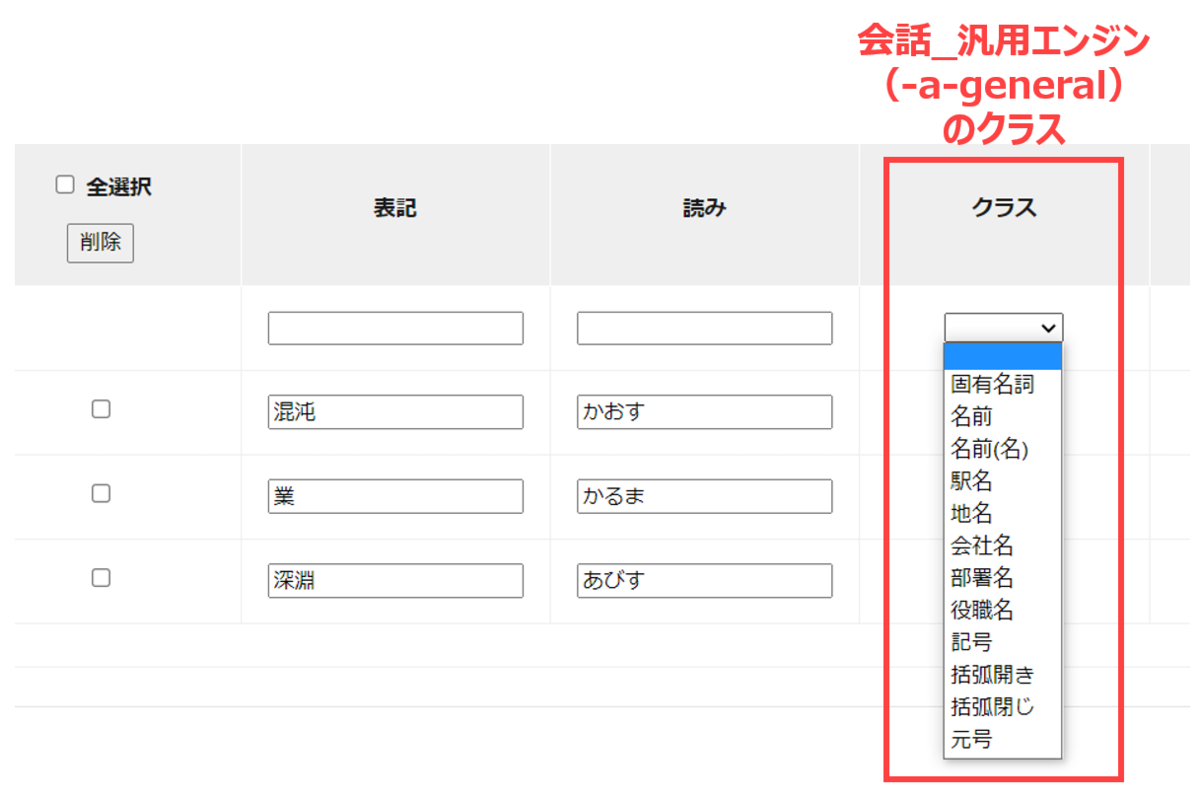
ここで「駅名」というクラスを選択して単語登録すると、その単語はさきほどの「池袋」の例のような単語・フレーズの前後に出やすい形で登録されます。(「池袋」だけではなく、音声認識エンジンに学習されているさまざまな駅名が持つ前後の単語・フレーズの情報をまとめて「駅名」というクラスが共有しています。)
ちなみに、例えば「会話_医療エンジン(-a-medgeneral)」を指定すると、下記のようなクラスが選べるようになります。ご覧の通り、音声認識エンジンによって持っているクラスは異なりますので、ご注意ください。
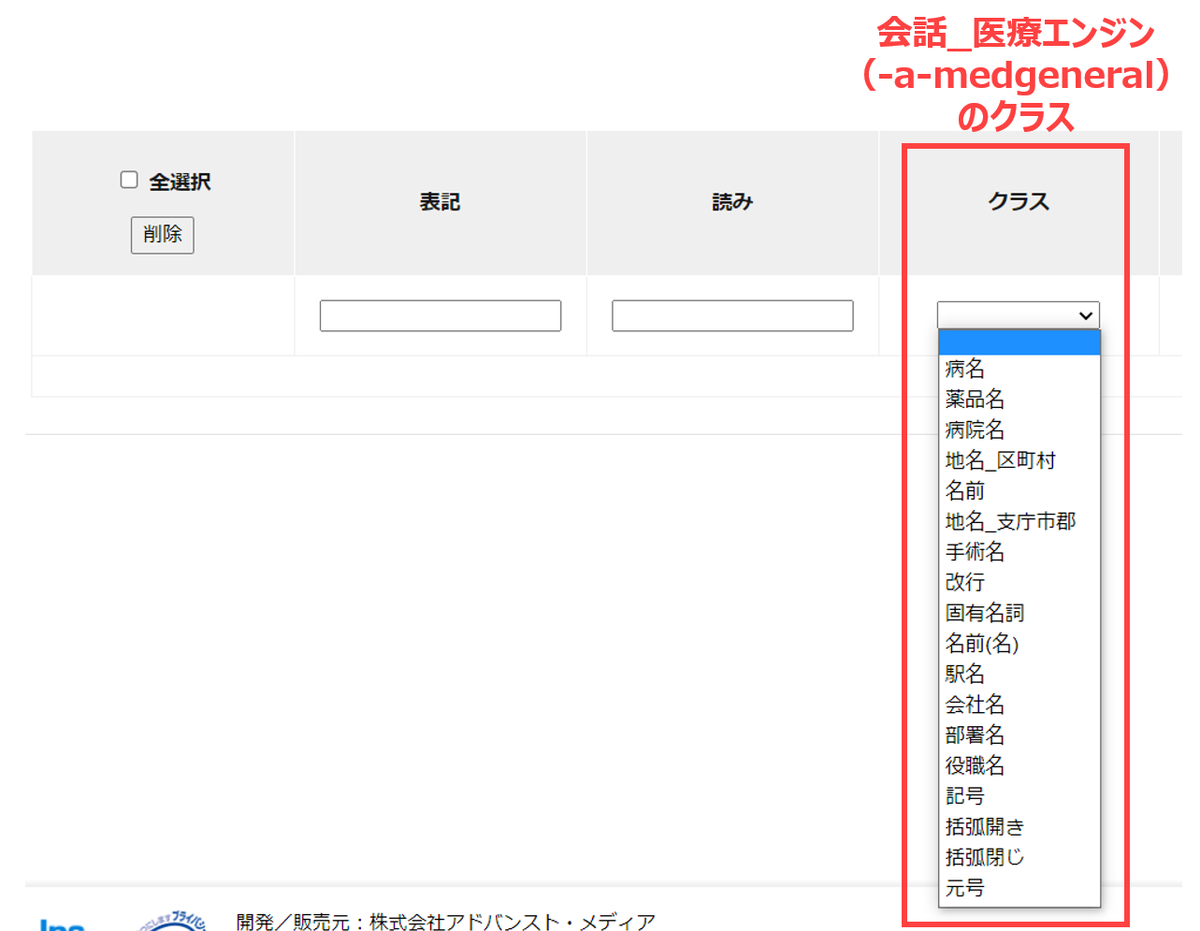
また、ここで1つ重要なポイントとして「クラスを指定しなかったらどうなるか」というものがあります。クラスを指定しない場合、登録した単語は「さまざまな単語・フレーズの前後に出現する」という登録のされ方になります。
登録した単語がさまざまな場所で出現しやすくなるのは一見便利なのですが、裏を返すと「喋ったつもりが無いのに間違って音声認識されてしまう」という可能性が上がりやすくなることになります。特に音声認識は前述のリンク先の記事で解説しましたが「音声」という非常に曖昧な情報をなんとかして文字化する技術でもあります。喋ったつもりがなくても発音が似ている単語は音声認識されてしまう可能性があるので、気をつける必要があります。
AmiVoiceの単語登録のコツの詳細
さて、それでは単語登録のコツについて詳細を解説していきましょう。
登録する単語数はできるだけ最小限に(ACPでは最大で1000単語まで)
登録した単語は音声認識されるようになりますが、同時に、登録した「読み」と近い発音の単語を喋った時に誤って音声認識されてしまう可能性も出てきます。登録単語数が少ない時はその可能性は低いのであまり気にしなくてもよいのですが、多数の単語を登録する時には注意が必要になります。
「読み」が短いものは要注意(できれば1~2文字のものは避ける)
「読み」の長さが短い単語ほど、同音異義語や似た発音の単語が既に存在している可能性が高くなりますので注意が必要です。逆に、十分に長い読みの単語の場合はあまり注意をする必要はありません。
同じ「表記」の単語を複数登録してもOK
「表記」が同じ単語を複数登録することができます。例えば「雰囲気」という単語の読みは「ふんいき」ですが、「ふいんき」と読む方もいると思います。このような場合には下記のように2単語を登録するといいでしょう。
■異なる読みの単語を複数登録する例
・表記:雰囲気 読み:ふんいき
・表記:雰囲気 読み:ふいんき
同じ「読み」の単語を複数登録しても意味がない
「読み」が同じ単語を複数登録しても意味がありません。例えば「こんぶちゃ」にはお馴染みの「昆布茶」以外に「Kombucha」という紅茶キノコの飲料もあるそうですが、「こんぶちゃを飲んだ」とだけ言われた場合にそれがどちらなのか人間には判断するのは難しいです。音声認識でも同様で、下記のように読みが同じ単語を2つ登録して「こんぶちゃ」と発話すると音声認識エンジンはどちらの表記を出力すればいいか判断ができません。同じ読みの単語は複数登録しないようにしましょう。
■同じ「読み」の単語を登録する例(どちらが音声認識されるか分からない)
・表記:昆布茶 読み:こんぶちゃ
・表記:Kombucha 読み:こんぶちゃ
※ちなみに、この2つを登録して「こんぶちゃ」と発話した時、どちらが音声認識結果として出るかは分かりません(仕様として未定義です)。
同じ「読み」の単語でも「クラス」が異なれば登録してもよい
同じ読みの単語でも、「クラス」が異なれば別の文脈の単語として扱われますので登録することに意味があります。例えば「とよた」と言った時に自動車メーカーの「トヨタ」を意味する場合があれば、名前(苗字)の「豊田」さんを意味する場合もあるかと思います。この場合はこういった登録の仕方をすると良いでしょう。
■同じ「読み」だが「クラス」が異なる単語の例(文脈によって音声認識される単語が変わる)
・表記:豊田 読み:とよた クラス:名前
・表記:トヨタ 読み:とよた クラス:会社名
上記のように登録した場合、会社名が出現する可能性の高い文脈で「とよた」と発話すると「トヨタ」と音声認識し、名前(苗字)が出現する可能性の高い文脈で「とよた」と発話すると「豊田」と音声認識することになります。
※音声認識エンジンが判断を誤る場合もあるのでご了承ください。
「読み」は自動的に変換される
「東京」という表記の単語を登録する時、読みを「とうきょう」とすると思います。しかし、実際「東京」という単語を発音するときは “う” の音は発音せずに 「とーきょー」と伸ばして発話すると思います。読みの表記と実際の発音が異なるというケースがあるということです。
このような現象の対策として、「読み」で指定した内容は内部で自動的に変換されます。例えば、以下の「読み」は全て同じものとして扱われますので、このようないろいろなパターンを登録する必要はなく、どれか1つだけを登録すれば十分です。
“とうきょう”
“とうきょお”
“とうきょー”
“とおきょう”
“とおきょお”
“とおきょー”
“とーきょう”
“とーきょお”
“とーきょー”
ただし、この自動変換によって意図しなかった読みが登録されてしまう可能性もあります。例えば「幕の内」という単語を登録する時、読みを「まくのうち」と入力すると思いますが、これは「まくのーち」と同じものとして扱われます。実際の発音が「まくのーち」の場合は問題ありませんが、人によっては「う」を明確にして「まくの “う” ち」と発音することもあるかと思います。
こういう場合の登録の方法を次の項目で説明します。
“.”(半角ドット)を使うと細かい読みの指定ができる
読みの中に “.”(半角ドット)を挿入することで、読みの自動変換を抑制することができます。具体的には下記のようになります。
・「まくのーち」と発音する場合
→読みを「まくのうち」「まくのーち」のどちらかで登録
・「まくの “う” ち」と発音する場合
→読みを「まくの.うち」と登録
実際のところこの「まくのーち」と「まくの.うち」のような例は発音が非常に似ているので、区別しなくても問題なく音声認識できるケースが多いです。少しでも音声認識率を高くしたかったり、どうしても区別が必要なケースに検討するといいでしょう。
「読み」はふりがなではでなく「どう読むか」
「洗濯機」という単語、「せんたくき」と読む方もいれば「せんたっき」と読む方もいると思いますが、もしも「せんたっき」と読むのなら読みは「せんたっき」と登録する方が好ましいです。下記のように両方を登録してもいいでしょう。
・表記:洗濯機 読み:せんたくき
・表記:洗濯機 読み:せんたっき
ちなみにこの例の場合「せんたくき」も「せんたっき」も発音は似ているので、そこまで細かく考えなくても通常は問題なく音声認識出来ると思います。登録した読みと実際の発音が大きく異る場合や、うまく音声認識できない場合などに、読みの内容をチェックするといいでしょう。
ACPで単語登録を使う場合の補足
AmiVoice Cloud Plarform(ACP)での単語登録機能の使い方は下記の記事で解説しています。記事にも記載がありますが、注意点としてACPでは単語登録した後にプロファイルIDを指定する必要があります。指定しないと登録した単語が有効になりませんので、ご注意ください。
AmiVoice Cloud Platform-Tech Blog
さいごに
今回はAmiVoiceの単語登録の仕組みとコツについて説明しました。かな漢字変換の単語登録と一見そっくりですが、いろいろと違うところもあります。コツを参考にしながら実際に単語登録して、喋ってみて、体感していただけると理解しやすいと思います。音声認識を使ったソフトウェア開発に興味がある方は、ぜひ、AmiVoice Cloud Platformを試して頂けると嬉しいです。
この記事を書いた人
-

安藤章悟
音声認識の研究をしていたら、近所に音声認識屋を見つけてしまい入社。今に至る。
趣味は海外旅行と美味しいものを食べることとサウナ。
よく見られている記事



新着記事
-
AmiVoice API アップデート解説 ボイスボット向け新パラメータで応答待ち時間を短縮

-
AmiVoice APIアップデート解説 End-to-End対応の「単語強調」機能

-
動画に字幕を簡単合成!音声認識APIで作る字幕ワークフロー

カテゴリ一覧
アーカイブ
