なぜAmiVoiceは高精度なのか?音声認識エンジンの種類が豊富な理由

 安藤章悟
安藤章悟
みなさま、こんにちは。
AmiVoiceが搭載された製品はいろいろありますが、その中には複数のAmiVoiceエンジンが搭載されており用途に応じて適切なものを選択できるものもあります。
例えば、開発者向けサービスのAmiVoice Cloud Platform(ACP)では、日本語エンジンとして下記の画像のように会話用のエンジンが5種類と、音声入力用のエンジンが6種類あり、用途に応じて使い分けできるようになっています。(2021年9月現在の情報です)
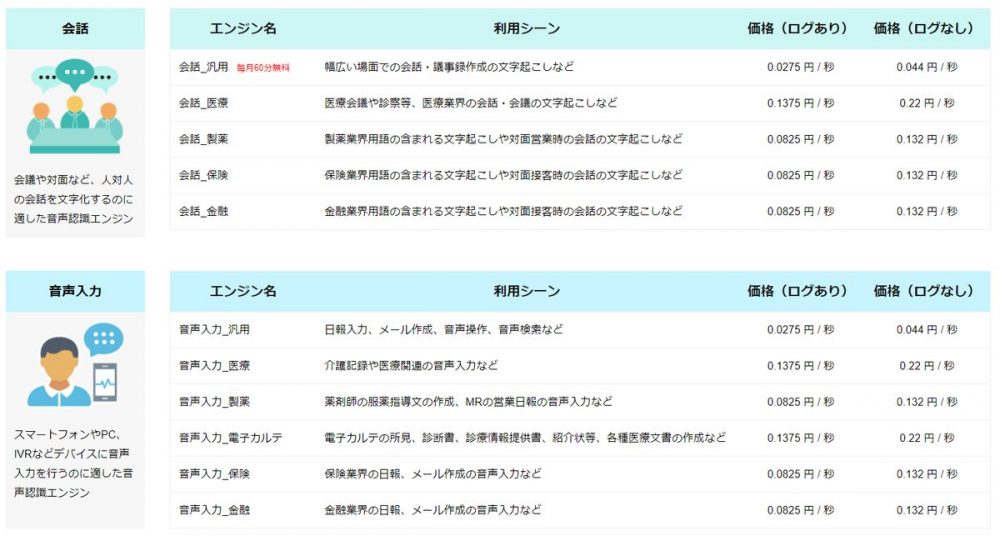
ちなみに、ACPではこれらのエンジンを「領域特化型エンジン」と呼称しています*1。
詳しい情報や最新情報は下記に掲載されています。
多くの方は音声認識に対してMicrosoft IMEのような「かな漢字変換」と似たイメージを持っていると思います。ですので、この領域特化型エンジンのように、複数のエンジンから用途に適したものを選択するというイメージは持ちにくいかもしれません。
今回はなぜAmiVoiceがこの領域特化型エンジンのように、複数のエンジンを用意しているのかを説明します。
結論:AmiVoiceは領域特化することでずば抜けた高精度を実現している
まずは結論から。音声認識は「音声」という曖昧なものを扱うため、どうしても誤認識をしてしまうという問題があります。AmiVoiceではこの誤認識を減らし高精度の音声認識を実現するために、用途ごとに特化した音声認識エンジンを用意するという工夫をしています。
音声認識の難しさと、IMEかな漢字変換との違い
なぜ領域特化すると音声認識精度が高くなるのかを説明したいのですが、その前に少し回り道をして「どうして音声認識は難しいのか」というお話をします。
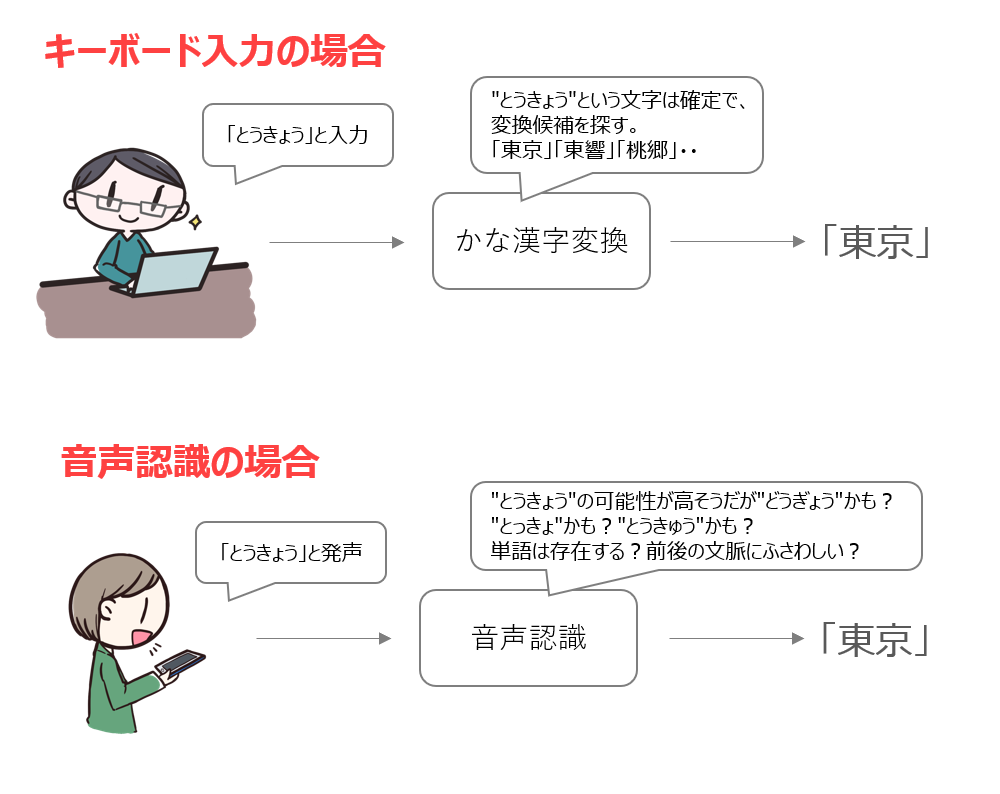
音声認識を使っていて、自分が喋ったつもりの内容と全く違うことが表示された経験は多くの方にあると思います。どうしてそうなるかというと、音声はキーボードのように入力が明確ではなく、とても曖昧なものだからです。キーボード入力なら入力した文字を1文字ずつ確定することができますが、音声入力の場合はそれがとても難しいのです。
少し例で説明します。例えばキーボード入力(ローマ字)で「こんにちは」と入力する場合は、「k o n n n i c h i h a」と11回キーを順番に入力します。「ち」が「chi」でも「ti」でもよいなどの違いはありますが、誰がやってもほぼ同じキーがほぼ同じ順番で押されることになるので間違いは起こりにくいです。
では、音声の場合はどうなるかというと、下記をご覧ください。これは私が「こんにちわ」と喋ったものをマイクで録音した音声波形です。横軸が時間で、縦軸が声による空気の振動(空気圧の変化)を示しています。
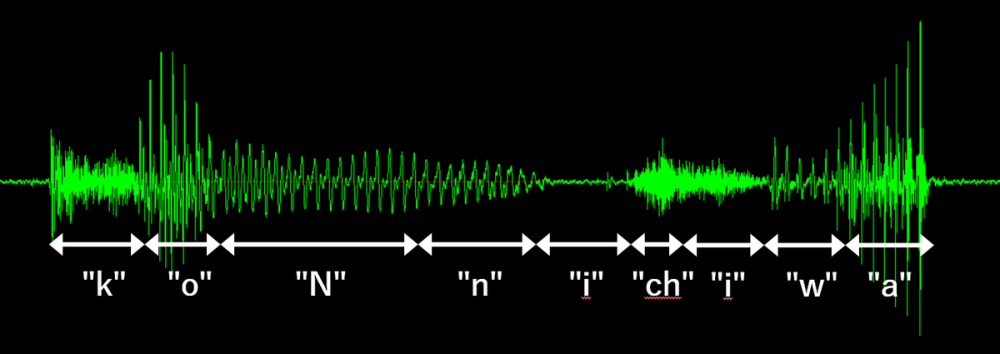
この波形は喋るたびに少しずつ違う形になりますし、声の調子が悪い時や、早口で喋った場合はさらに違った波形になります。また、違う人が喋ったらまた違った波形になりますし、雑音が入るともっと違った波形になります。要するに、キーボードと違って音声認識では毎回異なる内容のデータが入力されるため、文字(かな)の特定がとても難しいのです*2。
そのためかなを1文字ずつ特定していくのではなく「この波形はどのかなに似ているのか?」という解析をしてさまざまな可能性を探ります。さらに、かなの組み合わせのパターンを見て「どの単語の可能性が高いのか?」という探索を行います。
キーボード入力と音声認識は一見似ていますが、中でやっている処理はかなり違うものなのです。大雑把に表現すると下記の図のようになります。
さて、音声認識の難しさをざっくり説明したところで、次はどうやってその難しさを解決しているかの説明をします。音声認識では主に「音響モデル」「言語モデル」という2つのデータを使うという点が大きなポイントとなります*3。
音声認識の「音響モデル」のおはなし
音響モデルというのは、「あ」の音や、「い」の音、「う」の音*4・・・などをモデル化したデータです。入力された音声を音響モデルと照合して、「この音はどのかなの可能性が高いか?」という推定を行うためのものです。
AmiVoiceでは音響モデルに大勢の人の音を学習させることによって「人によって波形が違う」という部分を吸収しています。また、いろいろな種類の雑音を学習したり、いろいろな種類のマイクの音を学習させることで、雑音環境や録音環境の違いも吸収しています。さまざまなバリエーションの音を広く学習させることでより多くのパターンに対応できる汎用的な音響モデルを作ることができます。
しかし、何でもかんでも全ての音を学習させればいいかというと、そうでない場合もあります。例えば、ACPでは下記の2種類はそれぞれ別のものとして、特化した音響モデルを提供しています*5。
- 「会話」用音響モデル
人対人の会話を想定したものです。
- 「音声入力」用音響モデル
機械に対して音声入力する用途を想定したものです。
機械に対して音声入力する時、多くの利用者は明瞭にハキハキ発話しますが、人と喋る時はもう少し砕けた喋り方になることが多いです。ACPではこういった喋り方の違いに合わせ特化した音響モデルを用意することで、より高い音声認識精度を実現しています。
音声認識の「言語モデル」のおはなし
上述の通り、音声認識では喋られた音声に対して「どのかなの可能性が高いのか」という解析をし、かなの組み合わせパターンの中から「どの単語の可能性が高いのか」という探索を行います。ただ、これだけだとあらゆる単語が無関係に飛び出してしまい、音声認識結果の文章の内容が支離滅裂になってしまう可能性があります。
そこで、音声認識では「言語モデル」というデータを使って、どの単語を出すのがふさわしいかを判断しています。
例えば、「明日の天気は・・・」と言った後にはきっと「晴れ」「雨」「曇り」「良い」「悪い」「知らない」などが出てくる可能性が高く、逆に「カレー」や「ラーメン」などは可能性が低いだろうと予想できます。このような予測をするためのデータが「言語モデル」です。
言語モデルを作る際は、大量の文章を使用して単語間の繋がりの可能性などを計算するのですが、基本的には文章量が多ければ多いほど可能性が正確に計算され、品質の高い言語モデルが出来ます。なので、さまざまな文章をかき集めて単一の巨大な言語モデルを作る、というのがよくあるアプローチです。
しかしAmiVoiceでは単一の巨大な言語モデルだけではなく、喋るシーンに応じて領域特化した言語モデルも多数開発しています。何故かというと、利用者が喋る内容はシーンによって異なるため、それに特化したものを使った方がより高い音声認識精度を実現できるからです。
どうして領域特化すると高精度の音声認識ができるのか
音声認識では、ここまで説明した音響モデル・言語モデルの2つのデータを使って、曖昧な音声入力に対してもっとも可能性の高そうな音声認識結果を出力することになるのですが、ここで2つの考え方があります。
- さまざまな音声データやテキストデータを音響モデル・言語モデルに学習させることで、幅広い喋り方や内容を音声認識可能にする。
- 用途を限定して、その範囲内の限られた音声データやテキストデータを音響モデル・言語モデルに学習させる。
この2つはどちらが良い/悪いというわけではなく、両方にメリット・デメリットがあります。さまざまなデータを学習させると何でもだいたいカバーできるようになりますが、範囲が広い分どうしても誤認識しやすくなります。また、用途を限定するとその範囲内のことしか音声認識できなくなりますが、余計な単語が出現しなくなるので非常に高い音声認識精度を出すことが可能になります。
一般的にクラウドサービス等で利用可能な音声認識エンジンは幅広く学習しているものがほとんどです。AmiVoiceでは、もちろんこの幅広いデータを学習したものを提供していますが、用途を絞って学習したものも数多く提供しております。
まとめると以下の表のようになります。

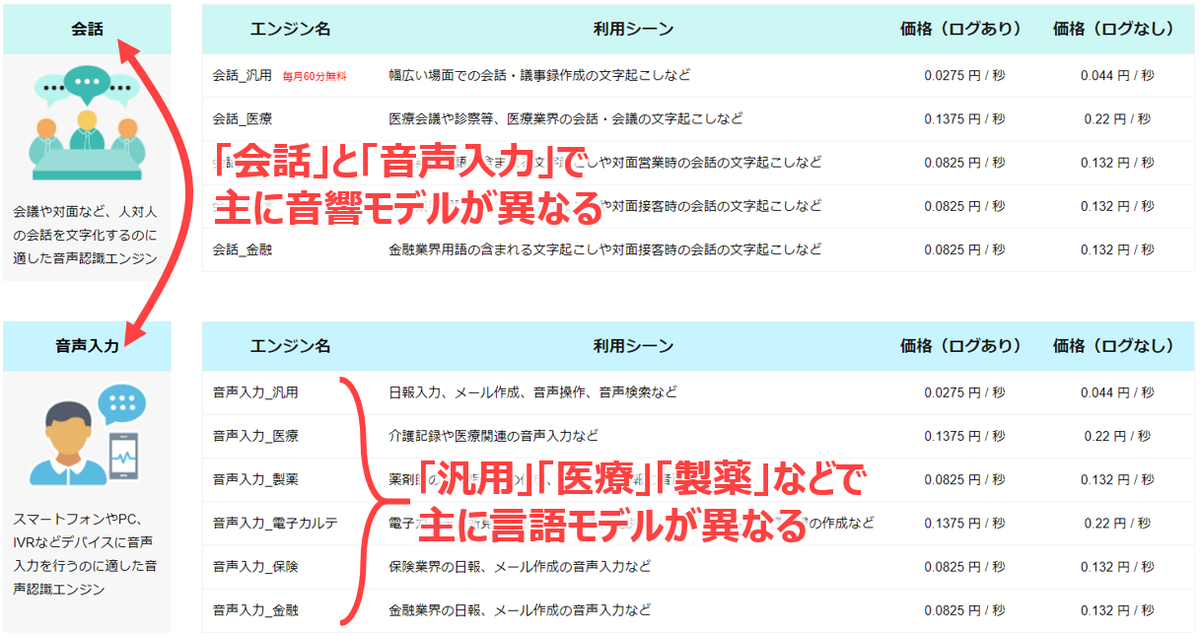
ACPで使える領域特化型エンジン
AmiVoiceが提供している音響モデルと言語モデルには数えきれないくらいの種類が存在するのですが、例えばACPでは https://acp.amivoice.com/main/plan/ にある選択肢から選ぶことができます。
まず大きく「会話」と「音声入力」の2種類に分かれますが、これらは主に音響モデルが異なります。また、同じ音響モデルの中でも「汎用」「医療」「製薬」などに分かれますが、これらは主に言語モデルが異なります*6。用途に応じて、最適なものを選んでいただければと思います。
さいごに
今回は、音声認識は音声という曖昧なものを扱うため、誤認識が発生しやすい点と、その解決のために音響モデル・言語モデルというものを使う点、そしてAmiVoiceではこの音響モデル・言語モデルと用途に応じて使い分けることで高い精度を実現している、というお話をしました。
また、ACPではこれらの音響モデル・言語モデルを組み合わせたいくつかの種類の音声認識エンジンを提供していますが、今後もラインナップを増やしていきたいと考えています。「こういう用途に特化した音声認識エンジンが欲しい」などの要望があれば是非コメントや、ACPの問い合わせからご連絡ください。対応をお約束することはできませんが、是非とも検討させていただきます。
この記事を書いた人
-
安藤章悟
音声認識の研究をしていたら、近所に音声認識屋を見つけてしまい入社。今に至る。
趣味は海外旅行と美味しいものを食べることとサウナ。
*1:正確には、「会話_汎用」「音声入力_汎用」の2つを「汎用エンジン」と呼び、それ以外のエンジンを領域特化型エンジンと呼んでいます。
*2:音声認識を難しくしている理由として、他にも下記のようなものもあります。
- 波形画像に「ここからここまでが “k” 」のような注釈を入れていますが、実際はこういったかなの境目は曖昧だったり、あるいは次のかなに移行する「中間の音」のようなものがあることも多いです。
- 2回出現している「i」の形がそれぞれ違うことからも分かりますが、同じかなでも前後のかなによって波形が変わることがあります。
- 同じかなでも人や喋り方によって波形の長さが変わります。
*3:音響モデルと言語モデル以外の工夫で解決している部分もありますが、今回の説明では割愛させていただきます
*4:前述のとおり、同じかなでも前後のかなによって波形が変わることがあるので、実際はひらがな1文字単位ではなく前後の音ごとに別のものとするなどの工夫もしています
*5:ACPでは提供していませんが、AmiVoiceでは他にも特殊な雑音環境用の音響モデルや、録音環境や音質に合わせた音響モデルなど、個別に特化したものも多数開発しています。
*6:「会話_汎用」と「音声入力_汎用」はどちらも「汎用」と名前が付きますが、会話と音声入力では用途が異なるためそれぞれ少しだけ中身の違う言語モデルを搭載しています
よく見られている記事



新着記事
-
音声認識が生成AIに与える影響とは?品質評価の新基準

-
AmiVoice APIを安全に使おう!APIキー発行&接続元IPアドレス制限実践ガイド

-
音声認識API「AmiVoice API」を使ってみよう

カテゴリ一覧
アーカイブ
