AmiVoice API アップデート解説 ボイスボット向け新パラメータで応答待ち時間を短縮
2025年11月、AmiVoice API に音声認識処理に関して複数の新機能がリリースされ、それらを使うためのリクエストパラメータが追加されました。
機能やパラメータの説明はマニュアルにも掲載していますが、新機能は少し応用的なものであるため、使い方や使い道がよくわからないという方もいらっしゃるかと思います。
この記事では、この時リリースされた新機能・パラメータのうち、特にボイスボットのような利用シーンに活躍する「recognitionTimeout」と「noInputTimeout」についてご紹介します。なお、音声認識リクエストにおけるパラメータの指定方法については、マニュアルを参照してください。
ざっくり説明すると
AmiVoice API では、通常、送信した音声データ全体の音声認識を実施します(エラー等が発生しなかった場合)。そのため、送信した音声データが長ければ、セッションが完了するまでにかかる時間も相応に長くなります。
しかし、利用シーンによっては、音声データ全体の認識結果は必要なく、最初の発話の認識結果が得られたらその音声の認識はさっさと切り上げて次の音声の認識へ移りたい、というような場合もあるでしょう。このような場合に役立つのが「認識完了タイムアウト」の「recognitionTimeout」です。
また、システムが音声による入力などを待っていてもしばらく発話が無いのであれば、ある程度で待機をやめて次のステップへ移りたいという場合もあるかもしれません。このような場合に使うのが「発話開始待ちタイムアウト」の「noInputTimeout」です。
| パラメータ | インタフェース | 用途 |
| recognitionTimeout | 同期 HTTP / 非同期 HTTP / WebSocket | 最初の有効な発話のみ音声認識させ、応答速度を上げたい場合 |
| noInputTimeout | WebSocket | 発話の開始を待つ時間の上限を設定したい場合 |
認識完了タイムアウト:recognitionTimeout
たとえば電話によるカスタマー対応に音声認識を導入しているボイスボットのような場合、一問一答形式の質問に対するカスタマーの回答の発話だけが必要であり、その音声認識結果のみをその後のシステム処理に利用していて、回答の発話以降の音声データ(無音や雑音、回答と関係のない発話など)に対する音声認識は不要である、というケースがあるかと思います。
この時、通常は、送信した音声データ全体の音声認識処理を行いますので、カスタマーの回答の部分の音声認識処理が終わった後も、残りの音声の認識処理も実施され、この音声認識リクエストのセッションが完了するまでに少し時間がかかってしまう場合があります。
ここで活躍するのが認識完了タイムアウトの機能です。
リクエストパラメータの「recognitionTimeout」に 0 以外の数値を指定することで機能が使えるようになります。また、ここで指定した数値は、この機能で働くタイムアウトまでの時間(ミリ秒)となります。
この機能を有効にすると、音声認識処理において、大きく述べて以下の2パターンの挙動が行われるようになります。
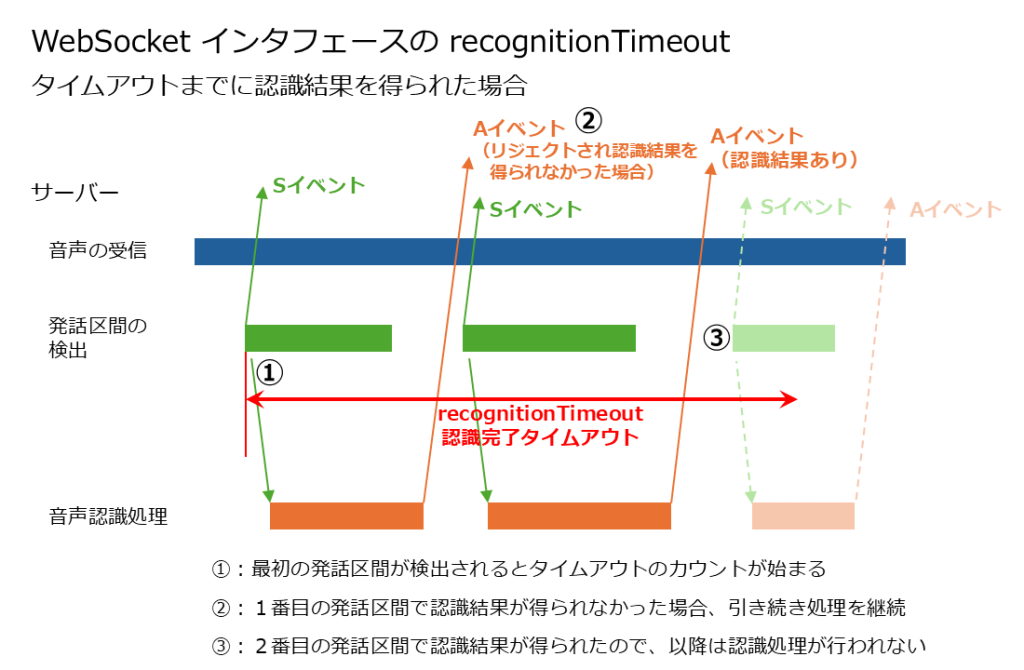
- タイムアウトまでの間に一つの発話区間の音声認識処理に成功し、認識結果(文字起こしデータ)が得られた場合、それ以降の残りの音声データについては音声認識処理を行わず、セッションを終了させる。
- タイムアウトまでの時間内に音声認識処理が完了しなかった場合は、処理がそこで中断され、その時点で得られている認識結果をクライアントに返却してセッションを終了させる。
この機能により、カスタマーの回答の後に続く不要な音声データの認識処理が終わるのを待たずに次のステップへ進むことや、認識処理に時間がかかる場合であっても、ある程度の時間で処理を切り上げて早めに次に進むことが可能になります。
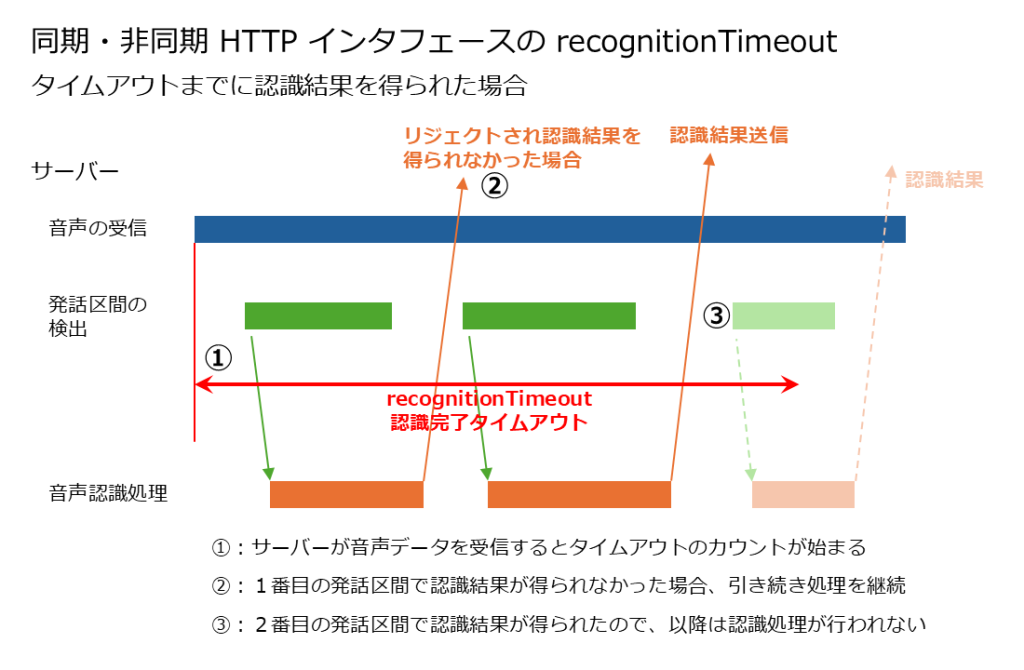
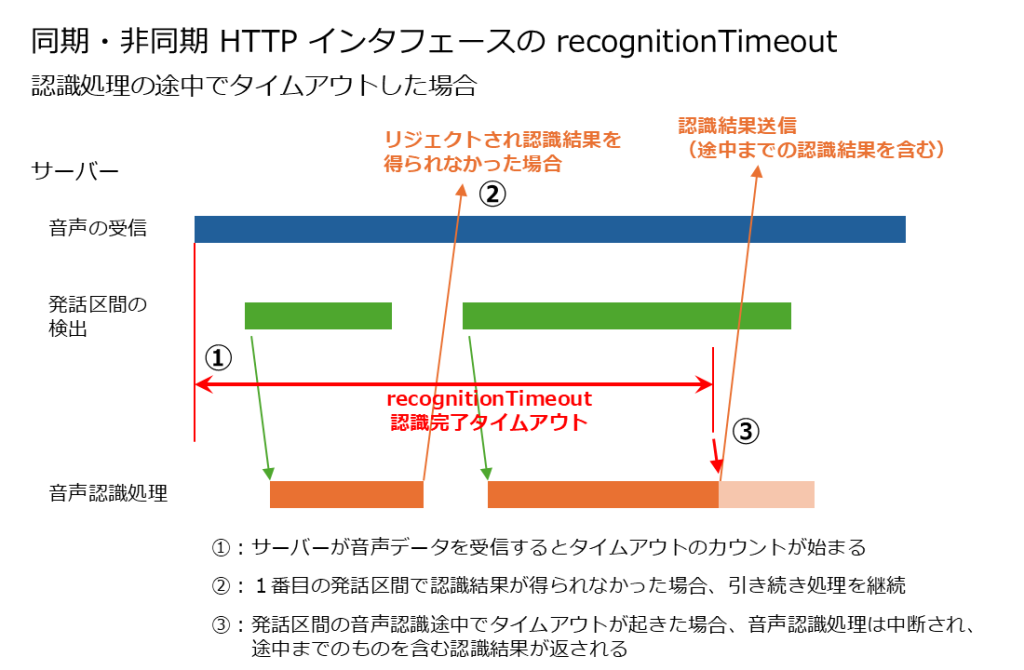
「recognitionTimeout」は同期 HTTP インタフェース、非同期 HTTP インタフェース、WebSocket インタフェースのいずれでも利用可能です。その詳細な挙動は以下のようになります。
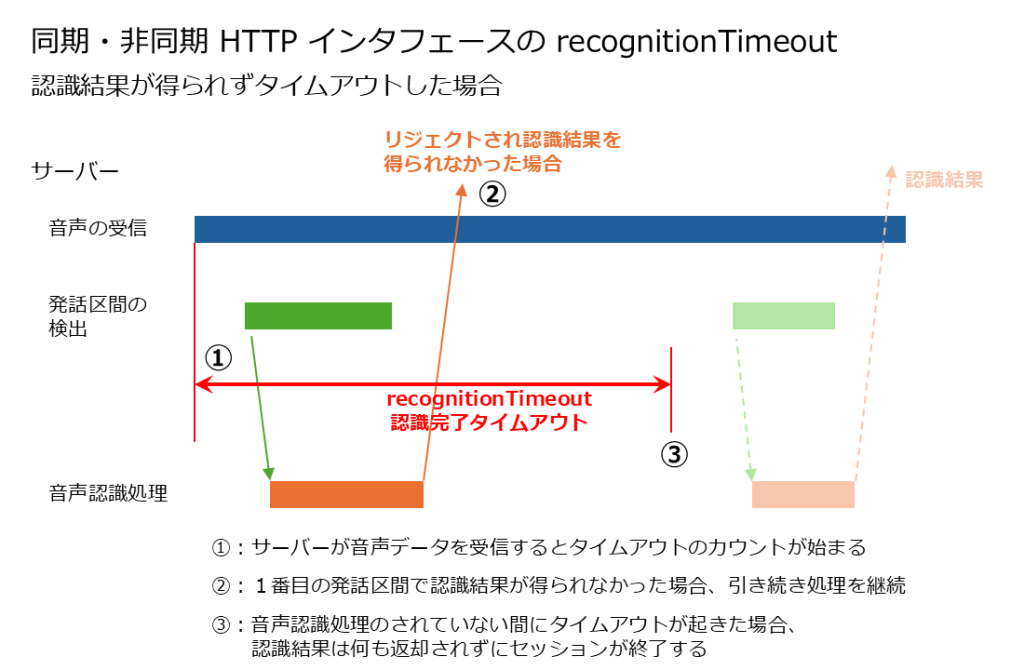
- 同期 HTTP インタフェースと非同期 HTTP インタフェースの場合は「音声認識サーバが音声データを受信してから『recognitionTimeout』のパラメータに指定した時間の長さ(ミリ秒)の間」、WebSocket インタフェースの場合は「最初の発話区間の先頭が検出されてから『recognitionTimeout』のパラメータに指定した時間の長さ(ミリ秒)の間」、音声認識処理を試みます。
- この間に音声認識が完了し、かつ認識結果が得られた発話区間があれば、「recognitionTimeout」の時間内であっても、以降の音声認識処理は行われなくなります。
- 発話区間が検出されて音声認識処理が行われたものの、たとえば全てがフィラーやノイズとして認識されてリジェクトされた場合など、認識結果が得られなかった場合は、続きの音声に対して音声認識処理が続行されます。
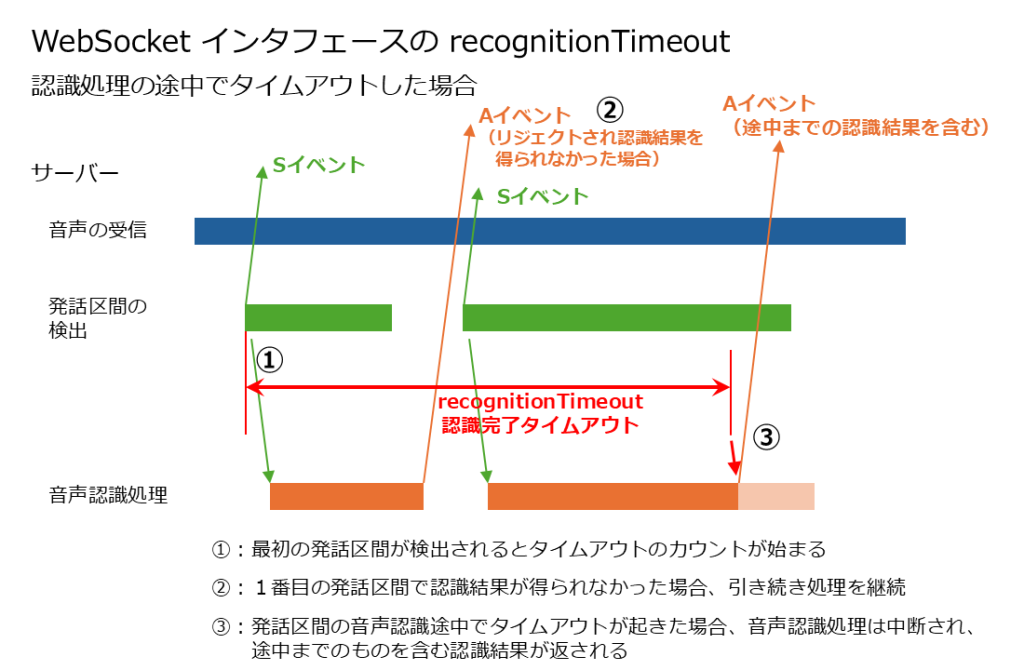
- 発話区間が検出されて音声認識処理が開始されたものの、「recognitionTimeout」の時間内に処理が完了しなかった場合、音声認識処理は途中で中断され、途中までの認識結果が返却されます。
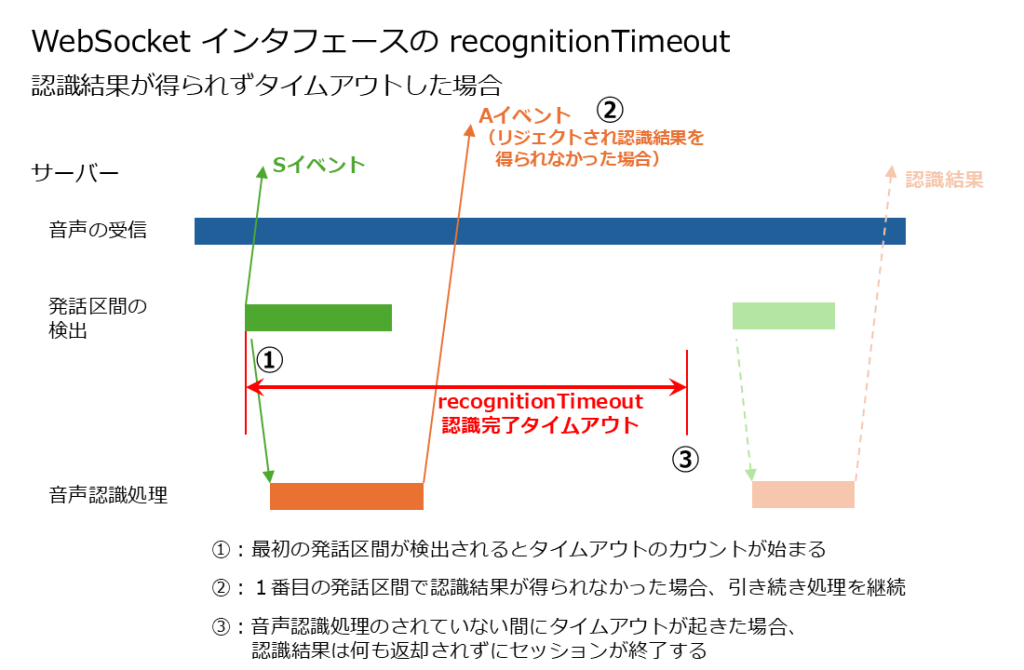
- 発話区間が検出されて音声認識処理が行われても、「recognitionTimeout」の時間内に処理の行われた発話区間が全てリジェクトされた場合は、認識結果は得られません。
たとえば、電話で顧客の問い合わせ対応を行うシステムにおいて、顧客番号を訊ねる質問を行い、顧客が以下のような発話をしたとします。
発話区間1:えーっと(フィラー)
発話区間2:○×◇番
発話区間3:……これであってるかな
この時、発話区間1が全てフィラーとして認識されてリジェクトされれば、認識結果は得られません。そのため、引き続き発話区間2の音声認識処理が行われます。次に、タイムアウトまでの間に発話区間2の認識結果が得られた場合、発話区間3は音声認識処理が行われません。タイムアウトまでに発話区間2の認識処理が終わらなかった場合は、処理が中断されて、その時点までに得られた認識の途中結果がクライアントに送られます。
この機能を図で表すと以下のようになります。
「recognitionTimeout」はミリ秒単位で時間を指定します。デフォルトでは 0 であり、0 の場合は、この認識完了タイムアウトの機能は無効です。
また、「recognitionTimeout」の時間の長さは、認識処理にかかる時間であり、音声データの時間とは異なる点に留意してください。
もしも、この機能を有効にしている際に、発話の途中で発話区間が途切れてしまい、必要な認識結果の全体が得られないような場合には、リクエストパラメータの segmenterProperties の発話区間検出に関するパラメータ、特に postTime を調節してみてください。
発話開始待ちタイムアウト:noInputTimeout
たとえば一問一答形式のボイスボットにおいて、カスタマーの回答が無ければその質問をスキップして次に進みたいというケースもあるかと思います。
通常は、送られてきた音声から発話区間が検出されなくても音声が続く間はセッションが継続され、WebSocket インタフェースの場合、発話区間が 600 秒間検出されなかった場合に接続が切断されます(制限事項)。
これを、600 秒待たずに切り上げたい場合に役立つのが、発話開始待ちタイムアウトの機能です。
リクエストパラメータの「noInputTimeout」に 0 以外の数値を指定することで機能が有効になります。また、ここで指定した数値は、この機能で働くタイムアウトまでの時間(ミリ秒)となります。
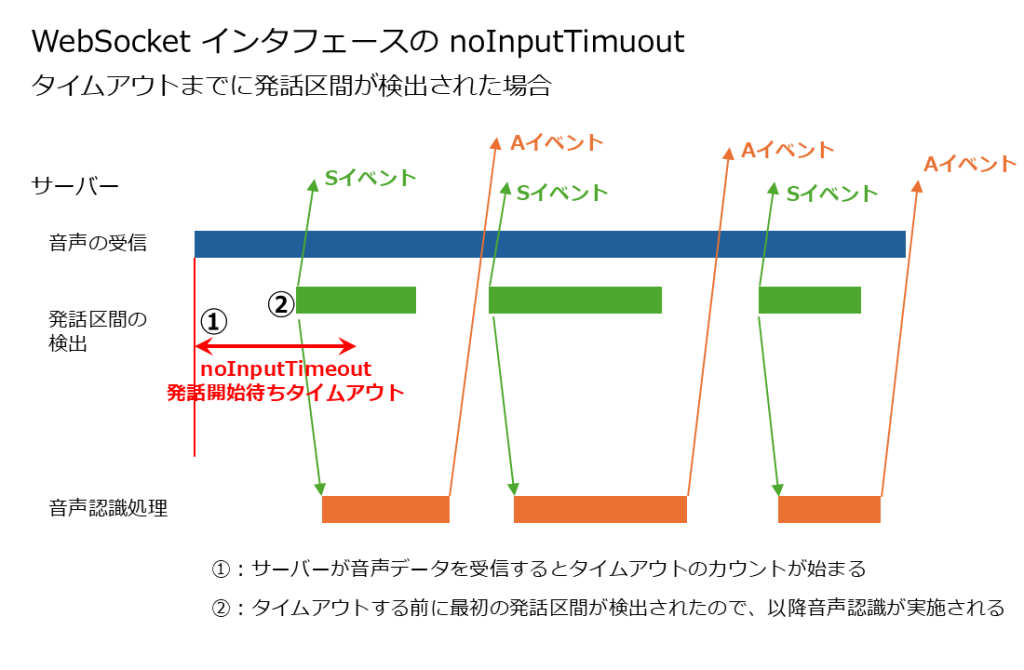
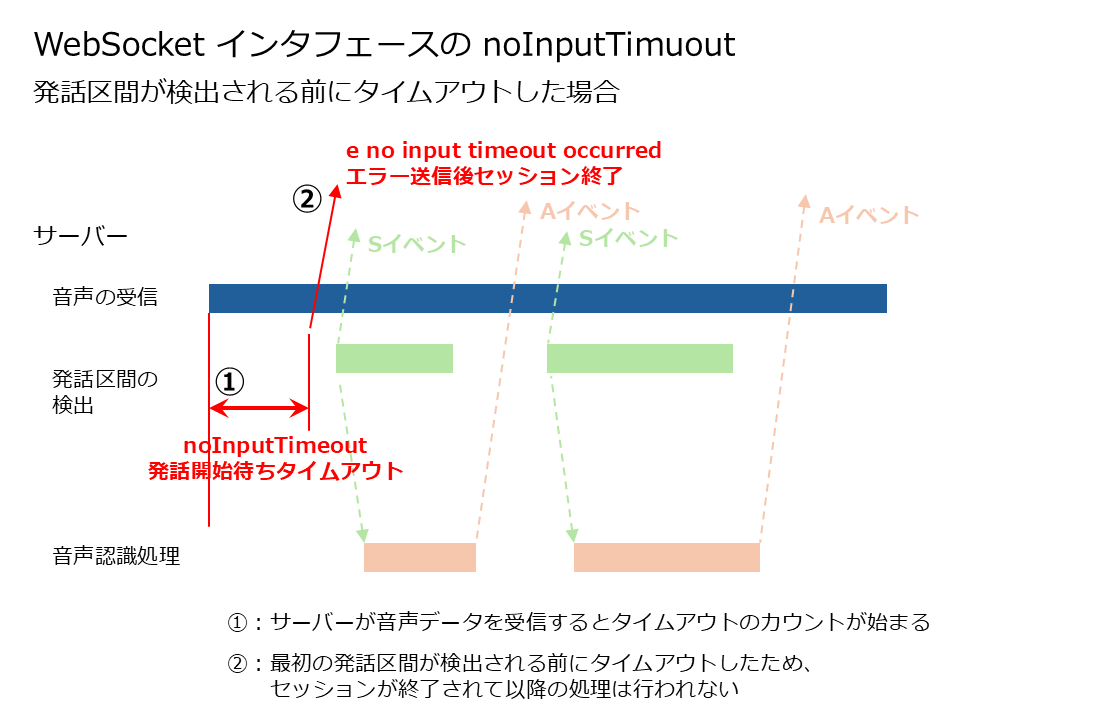
「noInputTimeout」は WebSocket インタフェースでのみ利用が可能であり、その挙動は以下のようになります。
- 音声認識サーバが音声を受信してから「noInputTimeout」のパラメータに指定した時間の長さ(ミリ秒)の間に発話区間が検出されなかった場合、エラーが返却され、音声認識処理が行われずにセッションが終了します。
- 「noInputTimeout」の時間内に最初の発話区間の先頭部分が検出されれば、「noInputTimeout」の時間を過ぎてもセッションは中断されず、音声認識処理が続行されます。
また、「noInputTimeout」は「recognitionTimeout」と併用が可能です。この場合、「noInputTimeout」の時間内に最初の発話区間の先頭部分が検出されれば、そこから「recognitionTimeout」のカウントが始まり、2段階のタイムアウトを設定できます。
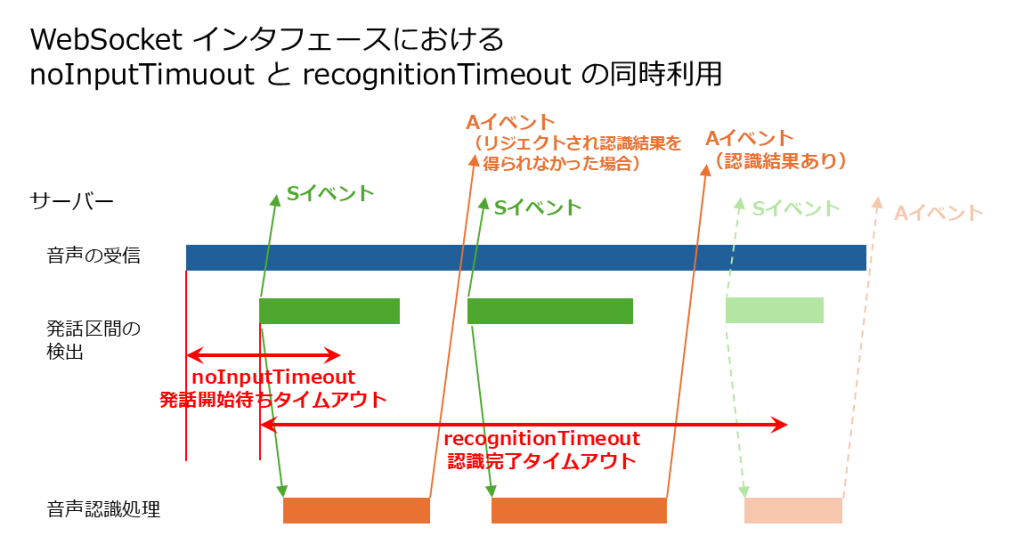
「noInputTimeout」はミリ秒単位で時間を指定します。デフォルトでは 0 であり、0 の場合は、この発話開始待ちタイムアウトの機能は無効です。
また「recognitionTimeout」と同様に、「noInputTimeout」の時間の長さは認識処理にかかる時間であり、音声データの時間とは異なる点に留意してください。
recognitionTimeout 開発のきっかけ
ご紹介した新機能について、どういうものかイメージしていただけるようになったでしょうか?
ちょっとややこしい「recognitionTimeout」の認識完了タイムアウト機能ですが、実は、実際にあった、あるユーザー様の困りごとが開発のきっかけになっています。
そのユーザー様のクライアントシステムでは、対話のような形式で発話によるシステムへの入力を行っていましたが、発話をしたのにシステムがエラーになってしまうようなケースがありました。このシステムには、一定時間 API から音声認識結果が返ってこない場合に、セッションを終了させるような仕組みが導入されていたのですが、このケースを調べてみると、このタイムアウトが発動してしまっていました。
この時 API に送られてきていた音声を調べてみたところ、入力のための発話の後に、話者が他の人と無関係の会話をする音声も入っていました。つまり、入力とは関係のない音声が加わってしまったことで、音声データの全体の長さが長くなった分、音声認識が完了するまでにシステムの想定よりも長く時間がかかってしまい、タイムアウトしてしまった、というわけです。
では、このような事例に対してどのような対策をしたら良いでしょうか?
たとえば、クライアントシステムの終話検知を調整する、ということが考えられます。しかし、雑音が発話と検知されてしまったり、関係の無い発話がすぐに始まってしまったりしたら、うまく終話を検知できない可能性がありますし、逆に、まだ入力用の発話の途中であるにも関わらず終話と判定されてしまうリスクが高まります。
もちろん、エンドユーザーに対して入力直後に余計な発話をしないようお願いする、というのは現実的ではありません。
そこで、余計な音声が送られてきた場合でも、必要と想定される部分以外は AmiVoice API 側で切り捨てられるように、「recognitionTimeout」が開発されました。
システムと人間が対話するような形式のシステムの場合、話者は通常、まずシステムへの回答となる発話をして、関係の無い発話をする場合はその後に続くことが想定されます。そのため、最初に認識結果の得られた発話区間がシステムに必要な発話であると想定し、それ以降の発話を無視する機能となっています。
回答の発話の前に「えーっと」などのフィラーが入った場合、全てがフィラーと認識された発話区間はリジェクトされて認識結果は得られず、次の発話区間に対して引き続き認識処理が行われますので、フィラーを除いた最初の発話だけが認識結果として得られる、という挙動となる想定です。
また、回答となる発話の直後に無関係な発話が続いてしまい、両者が一つの発話区間となって認識処理に時間がかかってしまう場合、指定した時間でタイムアウトする機能により、認識途中でも処理を中断して、それまでに得られた途中結果が返却されます。このため、返却される認識結果の中に必要な発話部分が含まれる可能性があります。
もしもクライアントシステム側でタイムアウトを設定するだけの場合、タイムアウトが発動してしまったら認識結果は一切得られません。しかし API 側で制御する場合は、タイムアウトまでに処理できた途中結果があれば、それを返すことが可能となり、これはメリットになります。
おまけ:ボイスボットに AmiVoice API を利用する場合のオススメエンジン
今回ご紹介した2つの新機能は、特にボイスボットのような利用シーンにおいて活用が期待されるものです。
ここでついでにボイスボットに向いている音声認識エンジンについても触れておきますと、端的に言えば End to End エンジンがオススメです。
End to End エンジンでは、特に、数字やアルファベット、その他短い発話に対して、ハイブリッドエンジンよりも精度が良くなる傾向があります。たとえば、英数字で構成されるカスタマーの顧客番号や生年月日、その他1単語で回答できる質問などを認識させたい場合、End to End エンジンが強いです。
最近、End to End エンジンでも、ハイブリッドエンジンにおける「単語登録」と似た機能である「単語強調」が使えるようになりましたので(参考テックブログ)、ぜひ試していただければと思います。
この記事を書いた人
-

茶まみれ
手がふさがっていても意思伝達に使える音声の活用の可能性を考えつつお茶を飲む人。
よく見られている記事



新着記事
-
AmiVoice API アップデート解説 ボイスボット向け新パラメータで応答待ち時間を短縮

-
AmiVoice APIアップデート解説 End-to-End対応の「単語強調」機能

-
動画に字幕を簡単合成!音声認識APIで作る字幕ワークフロー

カテゴリ一覧
アーカイブ
