動画に字幕を簡単合成!音声認識APIで作る字幕ワークフロー

 スパイス犬
スパイス犬
こんにちは。スパイス犬です。
「ブログ」という言葉ができたのはいつ頃でしょうか。それまでの「ウェブサイトを運営する」という、果てしなく複雑だった手段に代わって、ドメインもHTML知識も要らない画期的な情報発信手段となりました。その後は、SNSを中心とし、フォトを加えた華やかな手段に代わり、今や「VLog(ブイログ)」にて、個人の日記や記録を動画形式で公開するまでになりました。デジタルコミュニケーションが、ヒューマンインターフェースにより近づいてきた気がします。
VLogをはじめとするコミュニケーション手段としての動画にも、字幕やサブタイトルが付くことは今や普通です。グローバル発信するユーザも多く多言語の字幕をもつケースも多いです。近年のアクセシビリティの向上には驚くばかりです。
「字幕付き動画」の生成は、実はAmiVoiceを使うととっても簡単にできるんです。今日は、AmiVoiceを用いた字幕生成の例をご紹介します。
字幕付き動画の構造について
MP4、MOV、AVI、あるいはMPEG 皆さんはどの動画フォーマットを目にされたことがあるでしょうか?私は圧倒的にMPEG。光ディスクドライブやビデオカメラを設計していたその昔、DVD-Videoで使用されるフォーマットはすべてMPEGやVOBだったからです。スマホ録画やネット配信の現代においてはMPEGを見ることは稀になりましたが、地デジは今もMPEG-2コーデックだということなので息の長いフォーマットですね。
しかし、字幕生成の対象としやすいフォーマットはMP4、MOVなどのコンテナタイプになります。MP4やMOVには、MPEGにない”字幕”というメタデータがあらかじめ備わっている他、柔軟に対応できるタイムスタンプを持っているからです。ここからはMP4をベースに字幕合成の方法を示していきます。
字幕合成には2つの方法があります。それはハードサブ(焼き付け) と ソフトサブ(字幕トラック埋め込み)です。これらの違いはざっとこんなところ
- ハードサブ(焼き付け):
- 字幕が動画に直接焼き付けられているため、視聴者は字幕をオン・オフすることができません。
- どのデバイスやプレイヤーでも同じように表示されるため、互換性の問題がありません。
- 一度焼き付けると字幕を編集することが難しくなります。
- ソフトサブ(トラック埋め込み):
- 字幕が別のトラックとして動画ファイルに埋め込まれており、視聴者は字幕をオン・オフすることができます。
- 字幕ファイルを編集することで、簡単に内容を変更したり、複数の言語を追加することが可能です。
- 一部のデバイスやプレイヤーでは、ソフトサブが正しく表示されない場合があります。
グローバルなスマホ時代、私はソフトサブの方が柔軟でいいと感じています。字幕動画の作り方においてはオプション設定の違いだけです。今回はソフトサブで行きます。
手順
ステップは(視聴まで含めて)4つです
STEP1:音声ファイルの作成 : 動画から音声を抽出する
STEP2:テキスト化 :音声を音声認識でテキスト化する
STEP3:字幕作成と動画合成 :字幕用のテキストを動画トラックに埋め込む
FINAL:動画を見る :字幕が読める
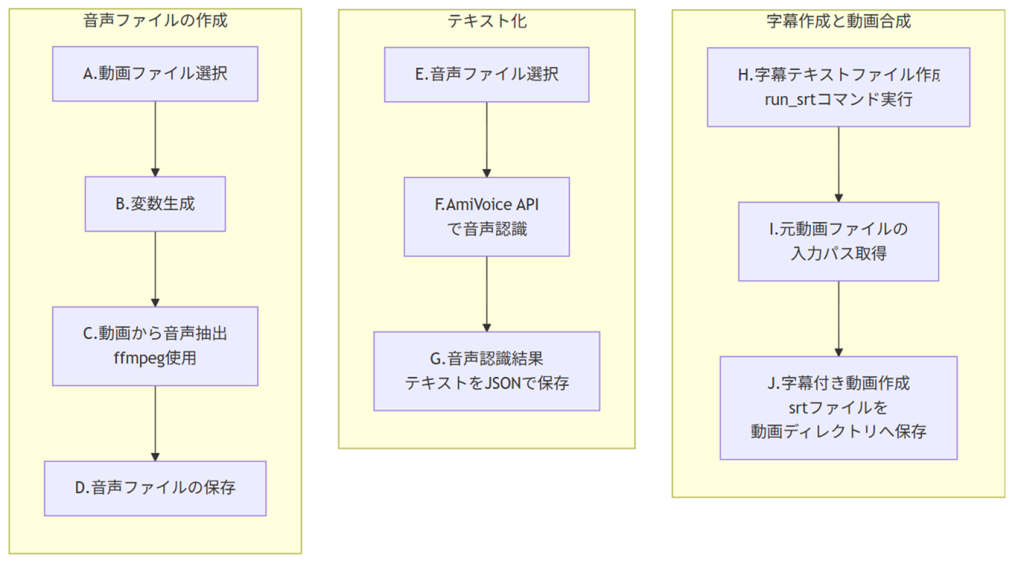
STEP1 音声ファイルの作成 :動画から音声を抽出する
高市総理の、「トランプ米国大統領との電話会談」を題材にします
https://www.kantei.go.jp/jp/104/statement/2025/111125kaiken.html
Web上の動画を再生してそのまま音を拾うこともできるのですが、動画をダウンロードして音声を抽出(音声ファイル書き出し)するととても高速です。抽出にはフリーツールのffmpegを使います。
mp3として保存するコマンド例
ffmpeg -i “%SelectedFile%” -vn -ar 44100 -ac 2 -b:a 192k “%SoundFilePath%” -y
ffmpegパラメータ説明
-i "%MovieFilePath%"
入力する動画ファイルを指定します。(例:C:\video\source.mp4)です。
-vn
Video None の略で、動画ストリームを無効化します。→ 音声だけを抽出・出力したいときに使います。
-ar 44100 Audio Rate(サンプリングレート)を 44,100 Hz に設定します。→ CD音質の標準的なサンプリングレートです。
-ac 2
Audio Channels を 2(ステレオ) に設定します。→ モノラルにしたい場合は -ac 1。
-b:a 192k Audio bitrate を 192 kbps に設定します。→ 128k~192k は音楽でも比較的良好な品質です。
"%SoundFilePath%"
出力音声ファイルのパスを指定します。拡張子(例:.mp3, .aac, .wav)によって音声コーデックやコンテナが自動選択されます。
-y 既存の出力ファイルがある場合でも確認なしで上書きします。→ 安全にしたい場合は -n(上書き禁止)に変更。
入力(ダウンロード)した動画”%selectedfile%”を “takaichi_voice.mp4″、出力した音声ファイル”%soundfilepath%”を ”takaichi_voice.mp3”として保存しておきます
Tips:mp3などの音声ファイルのリンクとしてWebに掲載されている音声は、音声認識とダウンロード(STEP1とSTEP2)をワンストップで行う方法もあります。こちらについても近く公開したいと考えています
STEP2 テキスト化 :音声認識でテキスト化する
AmiVoice Cloud Platform(ACP)のAmiVoice APIを用いて、音声をテキスト化します。APIの使い方は、ACPのマニュアルからサンプルプログラムをご活用頂くと簡単です。ここでは、WrpSimpleTester.pyを使っています。
入手方法 | AmiVoice Cloud Platform
WrpSimpleTester.py
JSONのみを抽出するため105,106行をコメントアウトしています
# encoding: UTF-8
import sys
import time
import json
# <!-- バイトコードキャッシュファイルの作成を抑制するために...
sys.dont_write_bytecode = True
# -->
import com.amivoice.wrp.Wrp
import com.amivoice.wrp.WrpListener
class WrpSimpleTester(com.amivoice.wrp.WrpListener):
@staticmethod
def main(args):
if len(args) < 4:
print("Usage: python WrpSimpleTester.py <url> <audioFileName> <codec> <grammarFileNames> [<authorization>]")
return
serverURL = args[0]
audioFileName = args[1]
codec = args[2]
grammarFileNames = args[3]
authorization = args[4] if len(args) > 4 else None
# WebSocket 音声認識サーバイベントリスナの作成
listener = WrpSimpleTester()
# WebSocket 音声認識サーバの初期化
wrp = com.amivoice.wrp.Wrp.construct()
wrp.setListener(listener)
wrp.setServerURL(serverURL)
wrp.setCodec(codec)
wrp.setGrammarFileNames(grammarFileNames)
wrp.setAuthorization(authorization)
# WebSocket 音声認識サーバへの接続
if not wrp.connect():
print(wrp.getLastMessage())
print(u"WebSocket 音声認識サーバ %s への接続に失敗しました。" % serverURL)
return
try:
# WebSocket 音声認識サーバへの音声データの送信の開始
if not wrp.feedDataResume():
print(wrp.getLastMessage())
print(u"WebSocket 音声認識サーバへの音声データの送信の開始に失敗しました。")
return
try:
with open(audioFileName, "rb") as audioStream:
# 音声データファイルからの音声データの読み込み
audioData = audioStream.read(4096)
while len(audioData) > 0:
# 微小時間のスリープ
wrp.sleep(1)
# 認識結果情報待機数が 1 以下になるまでスリープ
maxSleepTime = 50000
while wrp.getWaitingResults() > 1 and maxSleepTime > 0:
wrp.sleep(100)
maxSleepTime -= 100
# WebSocket 音声認識サーバへの音声データの送信
if not wrp.feedData(audioData, 0, len(audioData)):
print(wrp.getLastMessage())
print(u"WebSocket 音声認識サーバへの音声データの送信に失敗しました。")
break
# 音声データファイルからの音声データの読み込み
audioData = audioStream.read(4096)
except:
print(u"音声データファイル %s の読み込みに失敗しました。" % audioFileName)
# WebSocket 音声認識サーバへの音声データの送信の完了
if not wrp.feedDataPause():
print(wrp.getLastMessage())
print(u"WebSocket 音声認識サーバへの音声データの送信の完了に失敗しました。")
return
finally:
# WebSocket 音声認識サーバからの切断
wrp.disconnect()
def __init__(self):
pass
def utteranceStarted(self, startTime):
# print("S %d" % startTime)
pass
def utteranceEnded(self, endTime):
# print("E %d" % endTime)
pass
def resultCreated(self):
# print("C")
pass
def resultUpdated(self, result):
# print("U %s" % result)
pass
def resultFinalized(self, result):
# print("F %s" % result)
print(result)
text = self.text_(result)
#if text != None: # コメントアウトしているのは、JSON以外の音声認識結果を表示しないため
# print(" -> %s" % text)
def eventNotified(self, eventId, eventMessage):
# print(eventId + " " + eventMessage)
pass
def TRACE(self, message):
pass
def text_(self, result):
try:
return json.loads(result)["text"]
except:
return None
WrpSimpleTester.main(sys.argv[1:])
なお、音声認識リクエストの方法は”同期”、”非同期”のインターフェースがあります。どちらをお使い頂いても構いませんが16MBを超過する音声ファイルは”非同期”をお使いください。なお、認識結果はタイムスタンプを含むJSON形式ですべてのテキストを取得してください。
Windows OS向けのバッチファイルで動作させる場合の例を示します(16k 汎用エンジン を使用)
run_amivoice.bat
引数 %1 : 音声ファイルパス
引数 %2 : 出力するJSONファイルパス
set PYTHONPATH=src
set SSL_CERT_FILE=../../curl-ca-bundle.crt
python WrpSimpleTesterJimaku.py wss://acp-api.amivoice.com/v1/ %1 16K -a-general {APPKEY} |jq > %2
@pauseJSON形式で取得した会話テキストはこちら
ファイル名は”takaichi_voice.json”とします
takaichi_voice.json
{
"results": [
{
"tokens": [
{
"written": "皆様",
"confidence": 0.80,
"starttime": 422,
"endtime": 694,
"spoken": "みなさま"
},
{
"written": "どうぞ",
"confidence": 1.00,
"starttime": 694,
"endtime": 1286,
"spoken": "どうぞ"
}
],
"confidence": 0.922,
"starttime": 150,
"endtime": 1286,
"tags": [],
"rulename": "",
"text": "皆様どうぞ"
}
],
"utteranceid": "20260116/18/019bc62be4af0a3035e58536_20260116_183844",
"text": "皆様どうぞ",
"code": "",
"message": ""
}
{
"results": [
{
"tokens": [
{
"written": "朝日新聞",
"confidence": 0.98,
"starttime": 1938,
"endtime": 2562,
"spoken": "あさひしんぶん"
},
{
"written": "陣野",
"confidence": 0.98,
"starttime": 2562,
"endtime": 2786,
"spoken": "じんの"
},
{
"written": "と",
"confidence": 1.00,
"starttime": 2786,
"endtime": 2882,
"spoken": "と"
},
{
"written": "申し",
"confidence": 1.00,
"starttime": 2882,
"endtime": 3106,
"spoken": "もうし"
},
{
"written": "ます",
"confidence": 0.96,
"starttime": 3106,
"endtime": 3378,
"spoken": "ます"
},
{
"written": "。",
"confidence": 0.58,
"starttime": 3378,
"endtime": 3410,
"spoken": "_"
},
{
"written": "よろしくお願いします",
"confidence": 0.99,
"starttime": 3410,
"endtime": 4386,
"spoken": "よろしくおねがいします"
},
{
"written": "。",
"confidence": 0.53,
"starttime": 4386,
"endtime": 4418,
"spoken": "_"
},
{
"written": "よろしくお願いします",
"confidence": 0.98,
"starttime": 4418,
"endtime": 5522,
"spoken": "よろしくおねがいします"
},
{
"written": "。",
"confidence": 0.99,
"starttime": 5522,
"endtime": 5634,
"spoken": "_"
},
{
"written": "総理",
"confidence": 1.00,
"starttime": 5634,
"endtime": 5970,
"spoken": "そうり"
},
{
"written": "は",
"confidence": 1.00,
"starttime": 5970,
"endtime": 6130,
"spoken": "は"
},
{
"written": "アメリカ",
"confidence": 1.00,
"starttime": 6130,
"endtime": 6498,
"spoken": "あめりか"
},
{
"written": "の",
"confidence": 1.00,
"starttime": 6498,
"endtime": 6610,
"spoken": "の"
},
{
"written": "トランプ",
"confidence": 0.62,
"starttime": 6610,
"endtime": 6946,
"spoken": "とらんぷ"
},
{
"written": "大統領",
"confidence": 0.62,
"starttime": 6946,
"endtime": 7474,
"spoken": "だいとうりょう"
},
{
"written": "と",
"confidence": 1.00,
"starttime": 7474,
"endtime": 7618,
"spoken": "と"
},
{
"written": "電話",
"confidence": 1.00,
"starttime": 7650,
"endtime": 7954,
"spoken": "でんわ"
},
{
"written": "会談",
"confidence": 1.00,
"starttime": 7954,
"endtime": 8290,
"spoken": "かいだん"
},
{
"written": "に",
"confidence": 0.96,
"starttime": 8290,
"endtime": 8370,
"spoken": "に"
},
{
"written": "臨ま",
"confidence": 0.70,
"starttime": 8402,
"endtime": 8738,
"spoken": "のぞま"
},
{
"written": "れる",
"confidence": 1.00,
"starttime": 8738,
"endtime": 8930,
"spoken": "れる"
},
{
"written": "と",
"confidence": 1.00,
"starttime": 8930,
"endtime": 9010,
"spoken": "と"
},
{
"written": "行動",
"confidence": 0.99,
"starttime": 9010,
"endtime": 9346,
"spoken": "こうどう"
},
{
"written": "が",
"confidence": 1.00,
"starttime": 9346,
"endtime": 9458,
"spoken": "が"
},
{
"written": "出て",
"confidence": 0.95,
"starttime": 9458,
"endtime": 9634,
"spoken": "でて"
},
{
"written": "います",
"confidence": 0.98,
"starttime": 9634,
"endtime": 10194,
"spoken": "います"
},
{
"written": "。",
"confidence": 0.98,
"starttime": 10194,
"endtime": 10290,
"spoken": "_"
}
],
"confidence": 0.978,
"starttime": 1650,
"endtime": 10290,
"tags": [],
"rulename": "",
"text": "朝日新聞陣野と申します。よろしくお願いします。よろしくお願いします。総理はアメリカのトランプ大統領と電話会談に臨まれると行動が出ています。"
}
],
"utteranceid": "20260116/18/019bc62be4af0a3035e58536_20260116_183845",
"text": "朝日新聞陣野と申します。よろしくお願いします。よろしくお願いします。総理はアメリカのトランプ大統領と電話会談に臨まれると行動が出ています。",
"code": "",
"message": ""
}
{
"results": [
{
"tokens": [
{
"written": "こちら",
"confidence": 1.00,
"starttime": 10332,
"endtime": 10620,
"spoken": "こちら"
},
{
"written": "の",
"confidence": 1.00,
"starttime": 10620,
"endtime": 10732,
"spoken": "の"
},
{
"written": "実施",
"confidence": 1.00,
"starttime": 10732,
"endtime": 11084,
"spoken": "じっし"
},
{
"written": "状況",
"confidence": 1.00,
"starttime": 11084,
"endtime": 11436,
"spoken": "じょうきょう"
},
{
"written": "と",
"confidence": 1.00,
"starttime": 11436,
"endtime": 11708,
"spoken": "と"
},
{
"written": "どちら",
"confidence": 1.00,
"starttime": 11740,
"endtime": 12108,
"spoken": "どちら"
},
{
"written": "から",
"confidence": 1.00,
"starttime": 12108,
"endtime": 12252,
"spoken": "から"
},
{
"written": "持ちかけ",
"confidence": 1.00,
"starttime": 12252,
"endtime": 12652,
"spoken": "もちかけ"
},
{
"written": "られ",
"confidence": 1.00,
"starttime": 12652,
"endtime": 12844,
"spoken": "られ"
},
{
"written": "た",
"confidence": 1.00,
"starttime": 12844,
"endtime": 12972,
"spoken": "た"
},
{
"written": "の",
"confidence": 1.00,
"starttime": 12972,
"endtime": 13052,
"spoken": "の"
},
{
"written": "か",
"confidence": 1.00,
"starttime": 13052,
"endtime": 13164,
"spoken": "か"
},
{
"written": "について",
"confidence": 1.00,
"starttime": 13164,
"endtime": 13676,
"spoken": "について"
},
{
"written": "お尋ね",
"confidence": 0.82,
"starttime": 13708,
"endtime": 14092,
"spoken": "おたずね"
},
{
"written": "します",
"confidence": 0.97,
"starttime": 14092,
"endtime": 14764,
"spoken": "します"
},
{
"written": "。",
"confidence": 0.99,
"starttime": 14764,
"endtime": 14908,
"spoken": "_"
},
{
"written": "また",
"confidence": 1.00,
"starttime": 14908,
"endtime": 15340,
"spoken": "また"
},
{
"written": "、",
"confidence": 0.80,
"starttime": 15340,
"endtime": 15372,
"spoken": "_"
},
{
"written": "既に",
"confidence": 1.00,
"starttime": 15372,
"endtime": 15724,
"spoken": "すでに"
},
{
"written": "実施",
"confidence": 1.00,
"starttime": 15724,
"endtime": 16012,
"spoken": "じっし"
},
{
"written": "済み",
"confidence": 1.00,
"starttime": 16012,
"endtime": 16204,
"spoken": "ずみ"
},
{
"written": "の",
"confidence": 1.00,
"starttime": 16204,
"endtime": 16300,
"spoken": "の"
},
{
"written": "場合",
"confidence": 1.00,
"starttime": 16300,
"endtime": 16556,
"spoken": "ばあい"
},
{
"written": "は",
"confidence": 1.00,
"starttime": 16588,
"endtime": 16812,
"spoken": "は"
},
{
"written": "、",
"confidence": 0.52,
"starttime": 16812,
"endtime": 16844,
"spoken": "_"
},
{
"written": "会談",
"confidence": 0.80,
"starttime": 16844,
"endtime": 17196,
"spoken": "かいだん"
},
{
"written": "で",
"confidence": 1.00,
"starttime": 17196,
"endtime": 17292,
"spoken": "で"
},
{
"written": "どの",
"confidence": 0.99,
"starttime": 17292,
"endtime": 17484,
"spoken": "どの"
},
{
"written": "よう",
"confidence": 1.00,
"starttime": 17484,
"endtime": 17596,
"spoken": "よう"
},
{
"written": "な",
"confidence": 1.00,
"starttime": 17596,
"endtime": 17676,
"spoken": "な"
},
{
"written": "議論",
"confidence": 1.00,
"starttime": 17676,
"endtime": 17980,
"spoken": "ぎろん"
},
{
"written": "を",
"confidence": 1.00,
"starttime": 17980,
"endtime": 18076,
"spoken": "を"
},
{
"written": "され",
"confidence": 1.00,
"starttime": 18076,
"endtime": 18252,
"spoken": "され"
},
{
"written": "た",
"confidence": 1.00,
"starttime": 18252,
"endtime": 18380,
"spoken": "た"
},
{
"written": "の",
"confidence": 1.00,
"starttime": 18380,
"endtime": 18492,
"spoken": "の"
},
{
"written": "でしょうか?",
"confidence": 1.00,
"starttime": 18492,
"endtime": 19132,
"spoken": "でしょうか_"
}
],
"confidence": 0.972,
"starttime": 10300,
"endtime": 19132,
"tags": [],
"rulename": "",
"text": "こちらの実施状況とどちらから持ちかけられたのかについてお尋ねします。また、既に実施済みの場合は、会談でどのような議論をされたのでしょうか?"
}
],
"utteranceid": "20260116/18/019bc62be4af0a3035e58536_20260116_183846",
"text": "こちらの実施状況とどちらから持ちかけられたのかについてお尋ねします。また、既に実施済みの場合は、会談でどのような議論をされたのでしょうか?",
"code": "",
"message": ""
}
{
"results": [
{
"tokens": [
{
"written": "台湾",
"confidence": 1.00,
"starttime": 19326,
"endtime": 19790,
"spoken": "たいわん"
},
{
"written": "問題",
"confidence": 1.00,
"starttime": 19790,
"endtime": 20206,
"spoken": "もんだい"
},
{
"written": "や",
"confidence": 1.00,
"starttime": 20206,
"endtime": 20478,
"spoken": "や"
},
{
"written": "総理",
"confidence": 1.00,
"starttime": 20510,
"endtime": 20830,
"spoken": "そうり"
},
{
"written": "の",
"confidence": 0.87,
"starttime": 20830,
"endtime": 20958,
"spoken": "の"
},
{
"written": "存立",
"confidence": 0.97,
"starttime": 21038,
"endtime": 21486,
"spoken": "そんりつ"
},
{
"written": "危機",
"confidence": 1.00,
"starttime": 21486,
"endtime": 21710,
"spoken": "きき"
},
{
"written": "事態",
"confidence": 1.00,
"starttime": 21710,
"endtime": 22078,
"spoken": "じたい"
},
{
"written": "を",
"confidence": 1.00,
"starttime": 22078,
"endtime": 22110,
"spoken": "を"
},
{
"written": "巡る",
"confidence": 1.00,
"starttime": 22110,
"endtime": 22382,
"spoken": "めぐる"
},
{
"written": "答弁",
"confidence": 1.00,
"starttime": 22382,
"endtime": 22750,
"spoken": "とうべん"
},
{
"written": "について",
"confidence": 1.00,
"starttime": 22750,
"endtime": 23358,
"spoken": "について"
},
{
"written": "、",
"confidence": 0.56,
"starttime": 23358,
"endtime": 23390,
"spoken": "_"
},
{
"written": "どの",
"confidence": 1.00,
"starttime": 23390,
"endtime": 23582,
"spoken": "どの"
},
{
"written": "よう",
"confidence": 1.00,
"starttime": 23582,
"endtime": 23710,
"spoken": "よう"
},
{
"written": "な",
"confidence": 1.00,
"starttime": 23710,
"endtime": 23806,
"spoken": "な"
},
{
"written": "やり取り",
"confidence": 1.00,
"starttime": 23806,
"endtime": 24254,
"spoken": "やりとり"
},
{
"written": "を",
"confidence": 1.00,
"starttime": 24254,
"endtime": 24350,
"spoken": "を"
},
{
"written": "され",
"confidence": 1.00,
"starttime": 24350,
"endtime": 24574,
"spoken": "され"
},
{
"written": "た",
"confidence": 1.00,
"starttime": 24574,
"endtime": 24686,
"spoken": "た"
},
{
"written": "の",
"confidence": 1.00,
"starttime": 24686,
"endtime": 24798,
"spoken": "の"
},
{
"written": "か",
"confidence": 1.00,
"starttime": 24798,
"endtime": 24910,
"spoken": "か"
},
{
"written": "について",
"confidence": 0.99,
"starttime": 24910,
"endtime": 25278,
"spoken": "について"
},
{
"written": "も",
"confidence": 1.00,
"starttime": 25278,
"endtime": 25470,
"spoken": "も"
},
{
"written": "あわせ",
"confidence": 0.77,
"starttime": 25470,
"endtime": 25774,
"spoken": "あわせ"
},
{
"written": "て",
"confidence": 1.00,
"starttime": 25774,
"endtime": 25870,
"spoken": "て"
},
{
"written": "伺い",
"confidence": 1.00,
"starttime": 25870,
"endtime": 26206,
"spoken": "うかがい"
},
{
"written": "ます",
"confidence": 1.00,
"starttime": 26206,
"endtime": 26766,
"spoken": "ます"
},
{
"written": "。",
"confidence": 0.98,
"starttime": 26766,
"endtime": 26846,
"spoken": "_"
}
],
"confidence": 0.987,
"starttime": 19150,
"endtime": 26846,
"tags": [],
"rulename": "",
"text": "台湾問題や総理の存立危機事態を巡る答弁について、どのようなやり取りをされたのかについてもあわせて伺います。"
}
],
"utteranceid": "20260116/18/019bc62be4af0a3035e58536_20260116_183848",
"text": "台湾問題や総理の存立危機事態を巡る答弁について、どのようなやり取りをされたのかについてもあわせて伺います。",
"code": "",
"message": ""
}
{
"results": [
{
"tokens": [
{
"written": "はい",
"confidence": 1.00,
"starttime": 27338,
"endtime": 27802,
"spoken": "はい"
},
{
"written": "。",
"confidence": 0.77,
"starttime": 27802,
"endtime": 27994,
"spoken": "_"
}
],
"confidence": 1.000,
"starttime": 27050,
"endtime": 27994,
"tags": [],
"rulename": "",
"text": "はい。"
}
],
"utteranceid": "20260116/18/019bc62be4af0a3035e58536_20260116_183850",
"text": "はい。",
"code": "",
"message": ""
}
{
"results": [
{
"tokens": [
{
"written": "ありがとうございます",
"confidence": 1.00,
"starttime": 28112,
"endtime": 29152,
"spoken": "ありがとうございます"
},
{
"written": "。",
"confidence": 0.84,
"starttime": 29312,
"endtime": 29376,
"spoken": "_"
},
{
"written": "先ほど",
"confidence": 1.00,
"starttime": 29664,
"endtime": 30448,
"spoken": "さきほど"
},
{
"written": "トランプ大統領",
"confidence": 1.00,
"starttime": 30448,
"endtime": 31424,
"spoken": "とらんぷだいとうりょう"
},
{
"written": "から",
"confidence": 1.00,
"starttime": 31424,
"endtime": 31744,
"spoken": "から"
},
{
"written": "の",
"confidence": 1.00,
"starttime": 31744,
"endtime": 32048,
"spoken": "の"
},
{
"written": "お",
"confidence": 1.00,
"starttime": 32304,
"endtime": 32416,
"spoken": "お"
},
{
"written": "申し出",
"confidence": 1.00,
"starttime": 32416,
"endtime": 32896,
"spoken": "もうしで"
},
{
"written": "に",
"confidence": 1.00,
"starttime": 32896,
"endtime": 33008,
"spoken": "に"
},
{
"written": "より",
"confidence": 1.00,
"starttime": 33008,
"endtime": 33200,
"spoken": "より"
},
{
"written": "まして",
"confidence": 1.00,
"starttime": 33200,
"endtime": 33600,
"spoken": "まして"
},
{
"written": "電話",
"confidence": 0.99,
"starttime": 33600,
"endtime": 33936,
"spoken": "でんわ"
},
{
"written": "会談",
"confidence": 1.00,
"starttime": 33936,
"endtime": 34448,
"spoken": "かいだん"
},
{
"written": "を",
"confidence": 1.00,
"starttime": 34448,
"endtime": 34608,
"spoken": "を"
},
{
"written": "行い",
"confidence": 1.00,
"starttime": 34608,
"endtime": 35040,
"spoken": "おこない"
},
{
"written": "ました",
"confidence": 1.00,
"starttime": 35040,
"endtime": 35440,
"spoken": "ました"
},
{
"written": "。",
"confidence": 0.96,
"starttime": 35440,
"endtime": 35584,
"spoken": "_"
}
],
"confidence": 0.998,
"starttime": 28000,
"endtime": 35584,
"tags": [],
"rulename": "",
"text": "ありがとうございます。先ほどトランプ大統領からのお申し出によりまして電話会談を行いました。"
}
],
"utteranceid": "20260116/18/019bc62be4af0a3035e58536_20260116_183850_",
"text": "ありがとうございます。先ほどトランプ大統領からのお申し出によりまして電話会談を行いました。",
"code": "",
"message": ""
}
{
"results": [
{
"tokens": [
{
"written": "私",
"confidence": 1.00,
"starttime": 36144,
"endtime": 36528,
"spoken": "わたくし"
},
{
"written": "から",
"confidence": 1.00,
"starttime": 36528,
"endtime": 36720,
"spoken": "から"
},
{
"written": "は",
"confidence": 1.00,
"starttime": 36720,
"endtime": 37088,
"spoken": "は"
},
{
"written": "トランプ大統領",
"confidence": 1.00,
"starttime": 37376,
"endtime": 38336,
"spoken": "とらんぷだいとうりょう"
},
{
"written": "が",
"confidence": 1.00,
"starttime": 38336,
"endtime": 38656,
"spoken": "が"
},
{
"written": "訪日",
"confidence": 1.00,
"starttime": 38864,
"endtime": 39424,
"spoken": "ほうにち"
},
{
"written": "され",
"confidence": 1.00,
"starttime": 39424,
"endtime": 39680,
"spoken": "され"
},
{
"written": "た",
"confidence": 1.00,
"starttime": 39680,
"endtime": 40000,
"spoken": "た"
},
{
"written": "とき",
"confidence": 0.81,
"starttime": 40224,
"endtime": 40496,
"spoken": "とき"
},
{
"written": "の",
"confidence": 1.00,
"starttime": 40496,
"endtime": 40592,
"spoken": "の"
},
{
"written": "こと",
"confidence": 0.89,
"starttime": 40592,
"endtime": 40848,
"spoken": "こと"
},
{
"written": "を",
"confidence": 1.00,
"starttime": 40848,
"endtime": 40944,
"spoken": "を"
},
{
"written": "報道",
"confidence": 1.00,
"starttime": 40944,
"endtime": 41344,
"spoken": "ほうどう"
},
{
"written": "した",
"confidence": 1.00,
"starttime": 41344,
"endtime": 41744,
"spoken": "した"
},
{
"written": "。",
"confidence": 0.92,
"starttime": 41744,
"endtime": 41936,
"spoken": "_"
}
],
"confidence": 0.995,
"starttime": 35600,
"endtime": 41936,
"tags": [],
"rulename": "",
"text": "私からはトランプ大統領が訪日されたときのことを報道した。"
}
],
"utteranceid": "20260116/18/019bc62be4af0a3035e58536_20260116_183851",
"text": "私からはトランプ大統領が訪日されたときのことを報道した。",
"code": "",
"message": ""
}
{
"results": [
{
"tokens": [
{
"written": "アメリカ",
"confidence": 1.00,
"starttime": 42526,
"endtime": 43022,
"spoken": "あめりか"
},
{
"written": "の",
"confidence": 1.00,
"starttime": 43022,
"endtime": 43374,
"spoken": "の"
},
{
"written": "新聞",
"confidence": 1.00,
"starttime": 43662,
"endtime": 44094,
"spoken": "しんぶん"
},
{
"written": "に",
"confidence": 1.00,
"starttime": 44094,
"endtime": 44430,
"spoken": "に"
},
{
"written": "採用",
"confidence": 0.71,
"starttime": 44558,
"endtime": 45134,
"spoken": "さいよう"
},
{
"written": "した",
"confidence": 0.99,
"starttime": 45134,
"endtime": 45374,
"spoken": "した"
},
{
"written": "の",
"confidence": 1.00,
"starttime": 45374,
"endtime": 45502,
"spoken": "の"
},
{
"written": "を",
"confidence": 0.48,
"starttime": 45534,
"endtime": 45566,
"spoken": "を"
},
{
"written": "送っ",
"confidence": 1.00,
"starttime": 46110,
"endtime": 46430,
"spoken": "おくっ"
},
{
"written": "て",
"confidence": 1.00,
"starttime": 46430,
"endtime": 46526,
"spoken": "て"
},
{
"written": "きて",
"confidence": 1.00,
"starttime": 46526,
"endtime": 46702,
"spoken": "きて"
},
{
"written": "くださっ",
"confidence": 1.00,
"starttime": 46702,
"endtime": 47166,
"spoken": "くださっ"
},
{
"written": "た",
"confidence": 1.00,
"starttime": 47166,
"endtime": 47262,
"spoken": "た"
},
{
"written": "こと",
"confidence": 0.76,
"starttime": 47262,
"endtime": 47518,
"spoken": "こと"
},
{
"written": "への",
"confidence": 1.00,
"starttime": 47518,
"endtime": 47758,
"spoken": "への"
},
{
"written": "お礼",
"confidence": 0.57,
"starttime": 47758,
"endtime": 48046,
"spoken": "おれい"
},
{
"written": "と",
"confidence": 1.00,
"starttime": 48046,
"endtime": 48366,
"spoken": "と"
}
],
"confidence": 0.983,
"starttime": 41950,
"endtime": 48542,
"tags": [],
"rulename": "",
"text": "アメリカの新聞に採用したのを送ってきてくださったことへのお礼と"
}
],
"utteranceid": "20260116/18/019bc62be4af0a3035e58536_20260116_183852",
"text": "アメリカの新聞に採用したのを送ってきてくださったことへのお礼と",
"code": "",
"message": ""
}
{
"results": [
{
"tokens": [
{
"written": "あと",
"confidence": 0.78,
"starttime": 48582,
"endtime": 48838,
"spoken": "あと"
},
{
"written": "ウクライナ",
"confidence": 0.82,
"starttime": 49030,
"endtime": 49638,
"spoken": "うくらいな"
},
{
"written": "和平",
"confidence": 0.99,
"starttime": 49638,
"endtime": 50182,
"spoken": "わへい"
},
{
"written": "に",
"confidence": 1.00,
"starttime": 50214,
"endtime": 50422,
"spoken": "に"
},
{
"written": "関する",
"confidence": 1.00,
"starttime": 50422,
"endtime": 51238,
"spoken": "かんする"
},
{
"written": "米国",
"confidence": 1.00,
"starttime": 51782,
"endtime": 52294,
"spoken": "べいこく"
},
{
"written": "の",
"confidence": 1.00,
"starttime": 52294,
"endtime": 52486,
"spoken": "の"
},
{
"written": "取り組み",
"confidence": 1.00,
"starttime": 52518,
"endtime": 53078,
"spoken": "とりくみ"
},
{
"written": "への",
"confidence": 1.00,
"starttime": 53078,
"endtime": 53302,
"spoken": "への"
},
{
"written": "評価",
"confidence": 1.00,
"starttime": 53302,
"endtime": 53846,
"spoken": "ひょうか"
}
],
"confidence": 0.991,
"starttime": 48550,
"endtime": 54086,
"tags": [],
"rulename": "",
"text": "あとウクライナ和平に関する米国の取り組みへの評価"
}
],
"utteranceid": "20260116/18/019bc62be4af0a3035e58536_20260116_183853",
"text": "あとウクライナ和平に関する米国の取り組みへの評価",
"code": "",
"message": ""
}
{
"results": [
{
"tokens": [
{
"written": "について",
"confidence": 1.00,
"starttime": 54276,
"endtime": 55252,
"spoken": "について"
},
{
"written": "お伝え",
"confidence": 1.00,
"starttime": 55604,
"endtime": 56084,
"spoken": "おつたえ"
},
{
"written": "を",
"confidence": 1.00,
"starttime": 56084,
"endtime": 56164,
"spoken": "を"
},
{
"written": "しました",
"confidence": 1.00,
"starttime": 56164,
"endtime": 56740,
"spoken": "しました"
},
{
"written": "その",
"confidence": 1.00,
"starttime": 57108,
"endtime": 57380,
"spoken": "その"
},
{
"written": "上",
"confidence": 1.00,
"starttime": 57380,
"endtime": 57524,
"spoken": "うえ"
},
{
"written": "で",
"confidence": 1.00,
"starttime": 57524,
"endtime": 57716,
"spoken": "で"
},
{
"written": "日米",
"confidence": 1.00,
"starttime": 57716,
"endtime": 58196,
"spoken": "にちべい"
},
{
"written": "同盟",
"confidence": 1.00,
"starttime": 58196,
"endtime": 58484,
"spoken": "どうめい"
},
{
"written": "の",
"confidence": 1.00,
"starttime": 58484,
"endtime": 58580,
"spoken": "の"
},
{
"written": "強化",
"confidence": 1.00,
"starttime": 58580,
"endtime": 58996,
"spoken": "きょうか"
},
{
"written": "や",
"confidence": 1.00,
"starttime": 58996,
"endtime": 59300,
"spoken": "や"
},
{
"written": "、",
"confidence": 0.75,
"starttime": 59412,
"endtime": 59492,
"spoken": "_"
}
],
"confidence": 0.999,
"starttime": 54100,
"endtime": 59492,
"tags": [],
"rulename": "",
"text": "についてお伝えをしましたその上で日米同盟の強化や、"
}
],
"utteranceid": "20260116/18/019bc62be4af0a3035e58536_20260116_183854",
"text": "についてお伝えをしましたその上で日米同盟の強化や、",
"code": "",
"message": ""
}
{
"results": [
{
"tokens": [
{
"written": "インド",
"confidence": 0.94,
"starttime": 59612,
"endtime": 59916,
"spoken": "いんど"
},
{
"written": "太平洋",
"confidence": 0.94,
"starttime": 59916,
"endtime": 60380,
"spoken": "たいへいよう"
},
{
"written": "地域",
"confidence": 0.94,
"starttime": 60380,
"endtime": 60732,
"spoken": "ちいき"
},
{
"written": "が",
"confidence": 1.00,
"starttime": 60732,
"endtime": 60828,
"spoken": "が"
},
{
"written": "直面",
"confidence": 1.00,
"starttime": 60828,
"endtime": 61324,
"spoken": "ちょくめん"
},
{
"written": "する",
"confidence": 1.00,
"starttime": 61324,
"endtime": 61692,
"spoken": "する"
},
{
"written": "情勢",
"confidence": 1.00,
"starttime": 61692,
"endtime": 62108,
"spoken": "じょうせい"
},
{
"written": "や",
"confidence": 1.00,
"starttime": 62108,
"endtime": 62396,
"spoken": "や"
},
{
"written": "諸",
"confidence": 1.00,
"starttime": 62428,
"endtime": 62556,
"spoken": "しょ"
},
{
"written": "課題",
"confidence": 1.00,
"starttime": 62556,
"endtime": 62876,
"spoken": "かだい"
},
{
"written": "について",
"confidence": 1.00,
"starttime": 62876,
"endtime": 63372,
"spoken": "について"
},
{
"written": "幅広く",
"confidence": 1.00,
"starttime": 63372,
"endtime": 64092,
"spoken": "はばひろく"
},
{
"written": "意見",
"confidence": 1.00,
"starttime": 64380,
"endtime": 64732,
"spoken": "いけん"
},
{
"written": "交換",
"confidence": 1.00,
"starttime": 64732,
"endtime": 65212,
"spoken": "こうかん"
},
{
"written": "を",
"confidence": 1.00,
"starttime": 65212,
"endtime": 65468,
"spoken": "を"
},
{
"written": "行い",
"confidence": 1.00,
"starttime": 65500,
"endtime": 65868,
"spoken": "おこない"
},
{
"written": "ました",
"confidence": 1.00,
"starttime": 65868,
"endtime": 66236,
"spoken": "ました"
},
{
"written": "。",
"confidence": 0.91,
"starttime": 66236,
"endtime": 66444,
"spoken": "_"
}
],
"confidence": 0.999,
"starttime": 59500,
"endtime": 66444,
"tags": [],
"rulename": "",
"text": "インド太平洋地域が直面する情勢や諸課題について幅広く意見交換を行いました。"
}
],
"utteranceid": "20260116/18/019bc62be4af0a3035e58536_20260116_183855",
"text": "インド太平洋地域が直面する情勢や諸課題について幅広く意見交換を行いました。",
"code": "",
"message": ""
}
{
"results": [
{
"tokens": [
{
"written": "その",
"confidence": 1.00,
"starttime": 66738,
"endtime": 66962,
"spoken": "その"
},
{
"written": "中",
"confidence": 0.88,
"starttime": 66962,
"endtime": 67218,
"spoken": "なか"
},
{
"written": "で",
"confidence": 1.00,
"starttime": 67218,
"endtime": 67442,
"spoken": "で"
},
{
"written": "、",
"confidence": 0.63,
"starttime": 67442,
"endtime": 67474,
"spoken": "_"
},
{
"written": "トランプ大統領",
"confidence": 0.97,
"starttime": 67474,
"endtime": 68354,
"spoken": "とらんぷだいとうりょう"
},
{
"written": "から",
"confidence": 0.99,
"starttime": 68354,
"endtime": 68626,
"spoken": "から"
},
{
"written": "は",
"confidence": 1.00,
"starttime": 68626,
"endtime": 68818,
"spoken": "は"
},
{
"written": "昨晩",
"confidence": 1.00,
"starttime": 68818,
"endtime": 69458,
"spoken": "さくばん"
},
{
"written": "行わ",
"confidence": 1.00,
"starttime": 69922,
"endtime": 70482,
"spoken": "おこなわ"
},
{
"written": "れ",
"confidence": 1.00,
"starttime": 70482,
"endtime": 70610,
"spoken": "れ"
},
{
"written": "た",
"confidence": 1.00,
"starttime": 70610,
"endtime": 70930,
"spoken": "た"
},
{
"written": "米中",
"confidence": 0.99,
"starttime": 71186,
"endtime": 71586,
"spoken": "べいちゅう"
},
{
"written": "首脳",
"confidence": 1.00,
"starttime": 71586,
"endtime": 71954,
"spoken": "しゅのう"
},
{
"written": "会談",
"confidence": 1.00,
"starttime": 71954,
"endtime": 72338,
"spoken": "かいだん"
},
{
"written": "を",
"confidence": 1.00,
"starttime": 72338,
"endtime": 72434,
"spoken": "を"
},
{
"written": "含む",
"confidence": 1.00,
"starttime": 72434,
"endtime": 73106,
"spoken": "ふくむ"
}
],
"confidence": 0.996,
"starttime": 66450,
"endtime": 73138,
"tags": [],
"rulename": "",
"text": "その中で、トランプ大統領からは昨晩行われた米中首脳会談を含む"
}
],
"utteranceid": "20260116/18/019bc62be4af0a3035e58536_20260116_183856",
"text": "その中で、トランプ大統領からは昨晩行われた米中首脳会談を含む",
"code": "",
"message": ""
}
{
"results": [
{
"tokens": [
{
"written": "最近",
"confidence": 1.00,
"starttime": 73550,
"endtime": 74142,
"spoken": "さいきん"
},
{
"written": "の",
"confidence": 1.00,
"starttime": 74142,
"endtime": 74286,
"spoken": "の"
},
{
"written": "米中",
"confidence": 1.00,
"starttime": 74286,
"endtime": 74670,
"spoken": "べいちゅう"
},
{
"written": "関係",
"confidence": 1.00,
"starttime": 74670,
"endtime": 75150,
"spoken": "かんけい"
},
{
"written": "の",
"confidence": 1.00,
"starttime": 75150,
"endtime": 75374,
"spoken": "の"
},
{
"written": "状況",
"confidence": 1.00,
"starttime": 75406,
"endtime": 75886,
"spoken": "じょうきょう"
},
{
"written": "について",
"confidence": 1.00,
"starttime": 75886,
"endtime": 76702,
"spoken": "について"
},
{
"written": "説明",
"confidence": 1.00,
"starttime": 77166,
"endtime": 77758,
"spoken": "せつめい"
},
{
"written": "が",
"confidence": 1.00,
"starttime": 77758,
"endtime": 78222,
"spoken": "が"
},
{
"written": "ございました",
"confidence": 1.00,
"starttime": 78494,
"endtime": 79326,
"spoken": "ございました"
},
{
"written": "。",
"confidence": 0.62,
"starttime": 79326,
"endtime": 79438,
"spoken": "_"
}
],
"confidence": 1.000,
"starttime": 73150,
"endtime": 79438,
"tags": [],
"rulename": "",
"text": "最近の米中関係の状況について説明がございました。"
}
],
"utteranceid": "20260116/18/019bc62be4af0a3035e58536_20260116_183857",
"text": "最近の米中関係の状況について説明がございました。",
"code": "",
"message": ""
}
{
"results": [
{
"tokens": [
{
"written": "あわせて",
"confidence": 0.79,
"starttime": 79578,
"endtime": 80314,
"spoken": "あわせて"
},
{
"written": "私",
"confidence": 1.00,
"starttime": 80634,
"endtime": 81098,
"spoken": "わたくし"
},
{
"written": "が",
"confidence": 1.00,
"starttime": 81098,
"endtime": 81338,
"spoken": "が"
},
{
"written": "出席",
"confidence": 1.00,
"starttime": 81338,
"endtime": 81882,
"spoken": "しゅっせき"
},
{
"written": "した",
"confidence": 1.00,
"starttime": 81882,
"endtime": 82314,
"spoken": "した"
},
{
"written": "GTP",
"confidence": 0.72,
"starttime": 82490,
"endtime": 83402,
"spoken": "じーてぃーぴー"
},
{
"written": "の",
"confidence": 0.72,
"starttime": 84154,
"endtime": 84378,
"spoken": "の"
},
{
"written": "様子",
"confidence": 0.57,
"starttime": 84410,
"endtime": 84842,
"spoken": "ようす"
},
{
"written": "に",
"confidence": 0.57,
"starttime": 84842,
"endtime": 85306,
"spoken": "に"
},
{
"written": "つい",
"confidence": 0.87,
"starttime": 85418,
"endtime": 85706,
"spoken": "つい"
},
{
"written": "ても",
"confidence": 0.89,
"starttime": 85706,
"endtime": 86138,
"spoken": "ても"
},
{
"written": "尋ね",
"confidence": 0.95,
"starttime": 86170,
"endtime": 86634,
"spoken": "たずね"
},
{
"written": "られ",
"confidence": 1.00,
"starttime": 86634,
"endtime": 86842,
"spoken": "られ"
},
{
"written": "ました",
"confidence": 1.00,
"starttime": 86842,
"endtime": 87210,
"spoken": "ました"
},
{
"written": "ので",
"confidence": 1.00,
"starttime": 87210,
"endtime": 87594,
"spoken": "ので"
},
{
"written": "、",
"confidence": 0.76,
"starttime": 87594,
"endtime": 87690,
"spoken": "_"
}
],
"confidence": 0.996,
"starttime": 79450,
"endtime": 87690,
"tags": [],
"rulename": "",
"text": "あわせて私が出席したGTPの様子についても尋ねられましたので、"
}
],
"utteranceid": "20260116/18/019bc62be4af0a3035e58536_20260116_183857_",
"text": "あわせて私が出席したGTPの様子についても尋ねられましたので、",
"code": "",
"message": ""
}
{
"results": [
{
"tokens": [
{
"written": "お答え",
"confidence": 1.00,
"starttime": 87764,
"endtime": 88468,
"spoken": "おこたえ"
},
{
"written": "を",
"confidence": 1.00,
"starttime": 88468,
"endtime": 88724,
"spoken": "を"
},
{
"written": "いたし",
"confidence": 1.00,
"starttime": 88756,
"endtime": 89156,
"spoken": "いたし"
},
{
"written": "ました",
"confidence": 1.00,
"starttime": 89156,
"endtime": 89652,
"spoken": "ました"
},
{
"written": "現下",
"confidence": 1.00,
"starttime": 90036,
"endtime": 90420,
"spoken": "げんか"
},
{
"written": "の",
"confidence": 1.00,
"starttime": 90420,
"endtime": 90628,
"spoken": "の"
},
{
"written": "国際",
"confidence": 1.00,
"starttime": 90660,
"endtime": 91060,
"spoken": "こくさい"
},
{
"written": "情勢",
"confidence": 0.98,
"starttime": 91060,
"endtime": 91380,
"spoken": "じょうせい"
},
{
"written": "の",
"confidence": 1.00,
"starttime": 91380,
"endtime": 91540,
"spoken": "の"
},
{
"written": "もと",
"confidence": 1.00,
"starttime": 91540,
"endtime": 91860,
"spoken": "もと"
},
{
"written": "で",
"confidence": 1.00,
"starttime": 91860,
"endtime": 92244,
"spoken": "で"
},
{
"written": "先般",
"confidence": 1.00,
"starttime": 92580,
"endtime": 93092,
"spoken": "せんぱん"
},
{
"written": "の",
"confidence": 1.00,
"starttime": 93092,
"endtime": 93332,
"spoken": "の"
},
{
"written": "トランプ大統領",
"confidence": 0.94,
"starttime": 93380,
"endtime": 94164,
"spoken": "とらんぷだいとうりょう"
},
{
"written": "委員",
"confidence": 0.98,
"starttime": 94164,
"endtime": 94292,
"spoken": "いいん"
},
{
"written": "の",
"confidence": 1.00,
"starttime": 94292,
"endtime": 94500,
"spoken": "の"
},
{
"written": "訪日",
"confidence": 1.00,
"starttime": 94532,
"endtime": 95444,
"spoken": "ほうにち"
},
{
"written": "、",
"confidence": 0.68,
"starttime": 95444,
"endtime": 95492,
"spoken": "_"
}
],
"confidence": 0.970,
"starttime": 87700,
"endtime": 95492,
"tags": [],
"rulename": "",
"text": "お答えをいたしました現下の国際情勢のもとで先般のトランプ大統領委員の訪日、"
}
],
"utteranceid": "20260116/18/019bc62be4af0a3035e58536_20260116_183859",
"text": "お答えをいたしました現下の国際情勢のもとで先般のトランプ大統領委員の訪日、",
"code": "",
"message": ""
}
{
"results": [
{
"tokens": [
{
"written": "に",
"confidence": 0.95,
"starttime": 95788,
"endtime": 95980,
"spoken": "に"
},
{
"written": "続き",
"confidence": 1.00,
"starttime": 95980,
"endtime": 96364,
"spoken": "つづき"
},
{
"written": "まし",
"confidence": 1.00,
"starttime": 96364,
"endtime": 96636,
"spoken": "まし"
},
{
"written": "て",
"confidence": 1.00,
"starttime": 96636,
"endtime": 97132,
"spoken": "て"
},
{
"written": "日米",
"confidence": 0.70,
"starttime": 97996,
"endtime": 98460,
"spoken": "にちべい"
},
{
"written": "間",
"confidence": 0.70,
"starttime": 98460,
"endtime": 98684,
"spoken": "かん"
},
{
"written": "の",
"confidence": 1.00,
"starttime": 98684,
"endtime": 98876,
"spoken": "の"
},
{
"written": "緊密",
"confidence": 1.00,
"starttime": 98940,
"endtime": 99644,
"spoken": "きんみつ"
},
{
"written": "な",
"confidence": 1.00,
"starttime": 99644,
"endtime": 100092,
"spoken": "な"
},
{
"written": "連携",
"confidence": 1.00,
"starttime": 100124,
"endtime": 100668,
"spoken": "れんけい"
},
{
"written": "を",
"confidence": 1.00,
"starttime": 100668,
"endtime": 101020,
"spoken": "を"
},
{
"written": "確認",
"confidence": 1.00,
"starttime": 101052,
"endtime": 101500,
"spoken": "かくにん"
},
{
"written": "でき",
"confidence": 0.97,
"starttime": 101500,
"endtime": 101740,
"spoken": "でき"
},
{
"written": "た",
"confidence": 0.99,
"starttime": 101740,
"endtime": 101852,
"spoken": "た"
},
{
"written": "と",
"confidence": 1.00,
"starttime": 101852,
"endtime": 102140,
"spoken": "と"
}
],
"confidence": 0.999,
"starttime": 95500,
"endtime": 102284,
"tags": [],
"rulename": "",
"text": "に続きまして日米間の緊密な連携を確認できたと"
}
],
"utteranceid": "20260116/18/019bc62be4af0a3035e58536_20260116_183900",
"text": "に続きまして日米間の緊密な連携を確認できたと",
"code": "",
"message": ""
}
{
"results": [
{
"tokens": [
{
"written": "思い",
"confidence": 1.00,
"starttime": 102652,
"endtime": 102924,
"spoken": "おもい"
},
{
"written": "ます",
"confidence": 1.00,
"starttime": 102924,
"endtime": 103260,
"spoken": "ます"
},
{
"written": "。",
"confidence": 0.89,
"starttime": 103260,
"endtime": 103324,
"spoken": "_"
},
{
"written": "トランプ大統領",
"confidence": 0.99,
"starttime": 103692,
"endtime": 104636,
"spoken": "とらんぷだいとうりょう"
},
{
"written": "から",
"confidence": 1.00,
"starttime": 104636,
"endtime": 104924,
"spoken": "から"
},
{
"written": "は",
"confidence": 1.00,
"starttime": 104924,
"endtime": 105180,
"spoken": "は"
},
{
"written": "私",
"confidence": 1.00,
"starttime": 105484,
"endtime": 105916,
"spoken": "わたくし"
},
{
"written": "ども",
"confidence": 0.80,
"starttime": 105916,
"endtime": 106060,
"spoken": "ども"
},
{
"written": "は",
"confidence": 0.99,
"starttime": 106060,
"endtime": 106284,
"spoken": "は"
},
{
"written": "極めて",
"confidence": 1.00,
"starttime": 106284,
"endtime": 107132,
"spoken": "きわめて"
},
{
"written": "親しい",
"confidence": 1.00,
"starttime": 107324,
"endtime": 107852,
"spoken": "したしい"
},
{
"written": "友人",
"confidence": 1.00,
"starttime": 107852,
"endtime": 108268,
"spoken": "ゆうじん"
},
{
"written": "で",
"confidence": 1.00,
"starttime": 108268,
"endtime": 108380,
"spoken": "で"
},
{
"written": "あり",
"confidence": 1.00,
"starttime": 108380,
"endtime": 108780,
"spoken": "あり"
},
{
"written": "、",
"confidence": 0.87,
"starttime": 108780,
"endtime": 108844,
"spoken": "_"
}
],
"confidence": 0.979,
"starttime": 102300,
"endtime": 108844,
"tags": [],
"rulename": "",
"text": "思います。トランプ大統領からは私どもは極めて親しい友人であり、"
}
],
"utteranceid": "20260116/18/019bc62be4af0a3035e58536_20260116_183901",
"text": "思います。トランプ大統領からは私どもは極めて親しい友人であり、",
"code": "",
"message": ""
}
{
"results": [
{
"tokens": [
{
"written": "いつ",
"confidence": 0.92,
"starttime": 109058,
"endtime": 109298,
"spoken": "いつ"
},
{
"written": "でも",
"confidence": 0.91,
"starttime": 109298,
"endtime": 109810,
"spoken": "でも"
},
{
"written": "電話",
"confidence": 1.00,
"starttime": 110274,
"endtime": 110658,
"spoken": "でんわ"
},
{
"written": "を",
"confidence": 1.00,
"starttime": 110658,
"endtime": 110754,
"spoken": "を"
},
{
"written": "して",
"confidence": 1.00,
"starttime": 110754,
"endtime": 110946,
"spoken": "して"
},
{
"written": "きて",
"confidence": 1.00,
"starttime": 110946,
"endtime": 111186,
"spoken": "きて"
},
{
"written": "ほしい",
"confidence": 0.82,
"starttime": 111186,
"endtime": 111602,
"spoken": "ほしい"
},
{
"written": "と",
"confidence": 1.00,
"starttime": 111602,
"endtime": 112018,
"spoken": "と"
},
{
"written": "いう",
"confidence": 1.00,
"starttime": 112018,
"endtime": 112242,
"spoken": "いう"
},
{
"written": "お話",
"confidence": 1.00,
"starttime": 112274,
"endtime": 112850,
"spoken": "おはなし"
},
{
"written": "が",
"confidence": 1.00,
"starttime": 112850,
"endtime": 113106,
"spoken": "が"
},
{
"written": "ございました",
"confidence": 1.00,
"starttime": 113138,
"endtime": 113970,
"spoken": "ございました"
},
{
"written": "。",
"confidence": 0.89,
"starttime": 113970,
"endtime": 114194,
"spoken": "_"
}
],
"confidence": 0.999,
"starttime": 108850,
"endtime": 114194,
"tags": [],
"rulename": "",
"text": "いつでも電話をしてきてほしいというお話がございました。"
}
],
"utteranceid": "20260116/18/019bc62be4af0a3035e58536_20260116_183902",
"text": "いつでも電話をしてきてほしいというお話がございました。",
"code": "",
"message": ""
}
{
"results": [
{
"tokens": [
{
"written": "会談",
"confidence": 1.00,
"starttime": 114584,
"endtime": 115128,
"spoken": "かいだん"
},
{
"written": "内容",
"confidence": 1.00,
"starttime": 115128,
"endtime": 115464,
"spoken": "ないよう"
},
{
"written": "で",
"confidence": 1.00,
"starttime": 115464,
"endtime": 115576,
"spoken": "で"
},
{
"written": "ございます",
"confidence": 1.00,
"starttime": 115576,
"endtime": 116184,
"spoken": "ございます"
},
{
"written": "けれども",
"confidence": 1.00,
"starttime": 116184,
"endtime": 116872,
"spoken": "けれども"
},
{
"written": "これ",
"confidence": 1.00,
"starttime": 117176,
"endtime": 117848,
"spoken": "これ"
},
{
"written": "外交",
"confidence": 1.00,
"starttime": 118232,
"endtime": 118600,
"spoken": "がいこう"
},
{
"written": "上",
"confidence": 1.00,
"starttime": 118600,
"endtime": 118808,
"spoken": "じょう"
},
{
"written": "の",
"confidence": 1.00,
"starttime": 118808,
"endtime": 119096,
"spoken": "の"
},
{
"written": "やり取り",
"confidence": 1.00,
"starttime": 119128,
"endtime": 119640,
"spoken": "やりとり"
},
{
"written": "で",
"confidence": 1.00,
"starttime": 119640,
"endtime": 119736,
"spoken": "で"
},
{
"written": "ございます",
"confidence": 1.00,
"starttime": 119736,
"endtime": 120312,
"spoken": "ございます"
},
{
"written": "ので",
"confidence": 1.00,
"starttime": 120312,
"endtime": 120600,
"spoken": "ので"
},
{
"written": "、",
"confidence": 0.81,
"starttime": 120600,
"endtime": 120632,
"spoken": "_"
},
{
"written": "詳細",
"confidence": 1.00,
"starttime": 120632,
"endtime": 121096,
"spoken": "しょうさい"
},
{
"written": "について",
"confidence": 1.00,
"starttime": 121096,
"endtime": 121592,
"spoken": "について"
},
{
"written": "は",
"confidence": 1.00,
"starttime": 121592,
"endtime": 121816,
"spoken": "は"
}
],
"confidence": 0.999,
"starttime": 114200,
"endtime": 121944,
"tags": [],
"rulename": "",
"text": "会談内容でございますけれどもこれ外交上のやり取りでございますので、詳細については"
}
],
"utteranceid": "20260116/18/019bc62be4af0a3035e58536_20260116_183903",
"text": "会談内容でございますけれどもこれ外交上のやり取りでございますので、詳細については",
"code": "",
"message": ""
}
{
"results": [
{
"tokens": [
{
"written": "差し",
"confidence": 1.00,
"starttime": 121982,
"endtime": 122382,
"spoken": "さし"
},
{
"written": "控え",
"confidence": 1.00,
"starttime": 122382,
"endtime": 122670,
"spoken": "ひかえ"
},
{
"written": "させ",
"confidence": 1.00,
"starttime": 122670,
"endtime": 122958,
"spoken": "させ"
},
{
"written": "て",
"confidence": 1.00,
"starttime": 122958,
"endtime": 123166,
"spoken": "て"
},
{
"written": "ください",
"confidence": 1.00,
"starttime": 123166,
"endtime": 123790,
"spoken": "ください"
},
{
"written": "。",
"confidence": 0.89,
"starttime": 123790,
"endtime": 124046,
"spoken": "_"
}
],
"confidence": 1.000,
"starttime": 121950,
"endtime": 124046,
"tags": [],
"rulename": "",
"text": "差し控えさせてください。"
}
],
"utteranceid": "20260116/18/019bc62be4af0a3035e58536_20260116_183904",
"text": "差し控えさせてください。",
"code": "",
"message": ""
}
{
"results": [
{
"tokens": [
{
"written": "以上",
"confidence": 1.00,
"starttime": 125142,
"endtime": 125318,
"spoken": "いじょう"
},
{
"written": "で",
"confidence": 0.99,
"starttime": 125318,
"endtime": 125382,
"spoken": "で"
},
{
"written": "終わり",
"confidence": 0.98,
"starttime": 125382,
"endtime": 125558,
"spoken": "おわり"
},
{
"written": "ます",
"confidence": 0.99,
"starttime": 125558,
"endtime": 126374,
"spoken": "ます"
},
{
"written": "。",
"confidence": 0.81,
"starttime": 126374,
"endtime": 126438,
"spoken": "_"
}
],
"confidence": 0.991,
"starttime": 124550,
"endtime": 126438,
"tags": [],
"rulename": "",
"text": "以上で終わります。"
}
],
"utteranceid": "20260116/18/019bc62be4af0a3035e58536_20260116_183904_",
"text": "以上で終わります。",
"code": "",
"message": ""
}
{
"results": [
{
"tokens": [
{
"written": "お疲れ様です",
"confidence": 1.00,
"starttime": 127212,
"endtime": 128316,
"spoken": "おつかれさまです"
},
{
"written": "。",
"confidence": 0.90,
"starttime": 128316,
"endtime": 128428,
"spoken": "_"
}
],
"confidence": 1.000,
"starttime": 127100,
"endtime": 128588,
"tags": [],
"rulename": "",
"text": "お疲れ様です。"
}
],
"utteranceid": "20260116/18/019bc62be4af0a3035e58536_20260116_183905",
"text": "お疲れ様です。",
"code": "",
"message": ""
}
STEP3 字幕化と動画合成 :字幕用のテキストを動画トラックに埋め込む
いよいよクライマックスです。字幕用のタイムスタンプが入ったsrtを作成します。このバッチでjson2srt.pyを実行します。最終目的である字幕ファイル “takaichi_voice.srt”が出力されます。バッチファイルで実行します。
run_jimaku.bat takaichi_voice.json
run_jimaku.bat
@echo off
python json2srt2.py %1
@pause字幕ファイル出力
json2srt.py
import argparse
import json
parser = argparse.ArgumentParser()
parser.add_argument("file", help="Designate JSON file name to read")
parser.add_argument("-d", "--delimiters", help="Designate delimiters to separate subtitles. Default value is ['。','、']", default="。,、")
parser.add_argument("-s", "--skip", help="Designate skip words which do not inculud in subtitles. Default value is ['。','、']", default="。,、")
parser.add_argument("-t", "--time", help="Designate allowed time for single subtile by millisecongds. Default value is 5000", default=5000, type=int)
parser.add_argument("-c", "--charas", help="Designate allowed charas for single subtile. Default value is 25", default=25, type=int)
class SRTFomat():
def __init__(self, args):
self.text = ""
self.blocks = []
self.delimiters = args.delimiters.split(",")
self.skipWords = args.skip.split(",")
self.time = args.time
self.charas = args.charas
def readFile(self, file):
f = open(file, "r", encoding="utf-8")
contents = f.read()
f.close()
all_tokens = []
full_text = ""
# Method 1: Try to parse as single JSON object (original format)
try:
data = json.loads(contents)
# Handle original format: {"results": [0]: {"tokens": [], "text": ""}}
if "results" in data:
results = data["results"]
if isinstance(results, list) and len(results) > 0:
# Multiple results in array
for result in results:
if "tokens" in result:
all_tokens.extend(result["tokens"])
if "text" in result:
full_text += result["text"]
elif isinstance(results, dict):
# Single result object
if "tokens" in results:
all_tokens = results["tokens"]
if "text" in results:
full_text = results["text"]
# Direct format without results wrapper
elif "tokens" in data:
all_tokens = data["tokens"]
if "text" in data:
full_text = data["text"]
if all_tokens:
self.text = full_text
self.readTokens(all_tokens)
return
except json.JSONDecodeError:
pass # Continue to try other formats
# Method 2: Try JSONL format (multiple JSON objects per line)
lines = contents.strip().split('\n')
for line in lines:
line = line.strip()
if not line:
continue
try:
data = json.loads(line)
if "results" in data and isinstance(data["results"], list):
for result in data["results"]:
if "tokens" in result:
all_tokens.extend(result["tokens"])
if "text" in result:
full_text += result["text"]
except json.JSONDecodeError:
continue # Skip invalid lines
# Method 3: Try parsing as multi-line JSON objects
if not all_tokens:
current_json = ""
brace_count = 0
for line in lines:
line = line.strip()
if not line:
continue
current_json += line
# Count braces to determine if JSON object is complete
for char in line:
if char == '{':
brace_count += 1
elif char == '}':
brace_count -= 1
# If braces are balanced, we have a complete JSON object
if brace_count == 0 and current_json:
try:
data = json.loads(current_json)
if "results" in data and isinstance(data["results"], list):
for result in data["results"]:
if "tokens" in result:
all_tokens.extend(result["tokens"])
if "text" in result:
full_text += result["text"]
current_json = ""
except json.JSONDecodeError:
current_json = ""
brace_count = 0
if not all_tokens:
print(f"No valid JSON data found in file: {file}")
return
self.text = full_text
self.readTokens(all_tokens)
def readTokens(self, tokens):
sub = ""
startTime = 0
index = 1
# subTitles = []
for token in tokens:
written = token["written"]
# 字幕が空の場合 startTime を設定する
if sub == "":
# 字幕が空でもTokenの中身が句読点などであった場合はスキップ
if written in self.delimiters or written in self.skipWords:
continue
else:
startTime = token["starttime"]
# 字幕区切りをつくっていく
# 各条件で字幕を blocks に格納して一度リセットする
# 句読点にあたったら
if written in self.delimiters or len(sub) > self.charas or token["endtime"] - startTime > self.time:
self.blocks.append(self.createSRTBlock(index, startTime, token["endtime"], sub))
sub = ""
startTime = 0
index += 1
# 条件以外では字幕をつなげていく
else:
if written not in self.skipWords:
sub += token["written"]
# Forループここまで
# 最後のブロックを格納する
self.blocks.append(self.createSRTBlock(index, startTime, tokens[-1]["endtime"], sub))
def createSRTBlock(self, index, startTime, endTime, sub):
stime = self.timeFormat(startTime)
etime = self.timeFormat(endTime)
return f"{index}\n{stime} --> {etime}\n{sub}\n"
def timeFormat(self, time):
time_ = time
ms_ = int(time_ % 1000)
time_ = int((time_ - ms_) / 1000)
sec_ = int(time_ % 60)
time_ = int((time_ - sec_) / 60)
mn_ = int(time_ % 60)
time_ = int((time_ - mn_) /60)
hr_ = int(time_ % 60)
if ms_ < 10:
ms = f"00{ms_}"
elif ms_ < 100:
ms = f"0{ms_}"
else:
ms = str(ms_)
if sec_ < 10:
sec = f"0{sec_}"
else:
sec = str(sec_)
if mn_ < 10:
mn = f"0{mn_}"
else:
mn = str(mn_)
if hr_ < 10:
hr = f"0{hr_}"
else:
hr = str(hr_)
return f"{hr}:{mn}:{sec},{ms}"
def exportSRTText(self):
return "\n".join(self.blocks)
if __name__ == "__main__":
args = parser.parse_args()
if not args.file.endswith(".json"):
print("Please set json file")
else:
srt = SRTFomat(args)
srt.readFile(args.file)
text = srt.exportSRTText()
srtName = args.file.replace(".json", ".srt")
f = open(srtName, "w", encoding="utf-8")
f.write(text)
f.close()
print("done")
完成した字幕ファイルです。
takaichi_voice.srt
1
00:00:00,422 --> 00:00:03,410
皆様どうぞ朝日新聞陣野と申します
2
00:00:03,410 --> 00:00:04,418
よろしくお願いします
3
00:00:04,418 --> 00:00:05,634
よろしくお願いします
4
00:00:05,634 --> 00:00:09,346
総理はアメリカのトランプ大統領と電話会談に臨まれると
5
00:00:09,346 --> 00:00:10,290
が出ています
6
00:00:10,332 --> 00:00:14,092
こちらの実施状況とどちらから持ちかけられたのかについて
7
00:00:14,092 --> 00:00:14,908
します
8
00:00:14,908 --> 00:00:15,372
また
9
00:00:15,372 --> 00:00:16,844
既に実施済みの場合は
10
00:00:16,844 --> 00:00:20,830
会談でどのような議論をされたのでしょうか?台湾問題や
11
00:00:20,830 --> 00:00:23,390
の存立危機事態を巡る答弁について
12
00:00:23,390 --> 00:00:26,766
どのようなやり取りをされたのかについてもあわせて伺い
13
00:00:27,338 --> 00:00:27,994
はい
14
00:00:28,112 --> 00:00:29,376
ありがとうございます
15
00:00:29,664 --> 00:00:34,608
先ほどトランプ大統領からのお申し出によりまして電話会談
16
00:00:34,608 --> 00:00:35,584
行いました
17
00:00:36,144 --> 00:00:41,344
私からはトランプ大統領が訪日されたときのことを
18
00:00:41,344 --> 00:00:41,936
した
19
00:00:42,526 --> 00:00:47,758
アメリカの新聞に採用したのを送ってきてくださったこと
20
00:00:47,758 --> 00:00:53,078
お礼とあとウクライナ和平に関する米国の
21
00:00:53,078 --> 00:00:58,196
への評価についてお伝えをしましたその上で
22
00:00:58,196 --> 00:00:59,492
同盟の強化や
23
00:00:59,612 --> 00:01:04,732
インド太平洋地域が直面する情勢や諸課題について幅広く
24
00:01:04,732 --> 00:01:06,444
交換を行いました
25
00:01:06,738 --> 00:01:07,474
その中で
26
00:01:07,474 --> 00:01:13,106
トランプ大統領からは昨晩行われた米中首脳会談を
27
00:01:13,550 --> 00:01:19,326
最近の米中関係の状況について説明が
28
00:01:19,578 --> 00:01:24,842
あわせて私が出席したGTPの
29
00:01:24,842 --> 00:01:27,690
についても尋ねられましたので
30
00:01:27,764 --> 00:01:33,092
お答えをいたしました現下の国際情勢のもとで
31
00:01:33,092 --> 00:01:35,492
のトランプ大統領委員の訪日
32
00:01:35,788 --> 00:01:41,020
に続きまして日米間の緊密な連携
33
00:01:41,052 --> 00:01:43,324
確認できたと思います
34
00:01:43,692 --> 00:01:48,780
トランプ大統領からは私どもは極めて親しい友人で
35
00:01:49,058 --> 00:01:54,194
いつでも電話をしてきてほしいというお話がございました
36
00:01:54,584 --> 00:01:59,640
会談内容でございますけれどもこれ外交上の
37
00:01:59,640 --> 00:02:00,632
でございますので
38
00:02:00,632 --> 00:02:04,046
詳細については差し控えさせてください
39
00:02:05,142 --> 00:02:06,438
以上で終わります
40
00:02:07,212 --> 00:02:08,428
お疲れ様です
41
00:00:00,000 --> 00:02:08,428
最終工程です。動画と同じフォルダにtakaichi_voice.srtを置きます。ここでのポイントは、動画のmp4ファイルと、srtファイルを同じファイル名にしておくことです。これで確実にsrtが読み込まれます。
FINAL 動画をみる、字幕が読める
VLCメディアプレーヤーで動画”takaichi_voice.mp4″開くと、字幕トラックからトラック1が選択できるはずです。
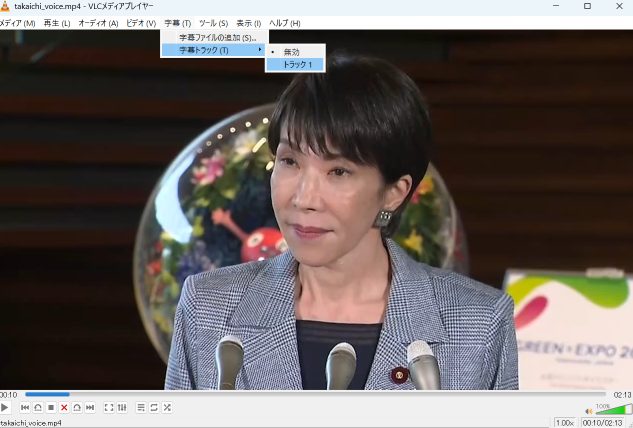
すると、でました字幕!
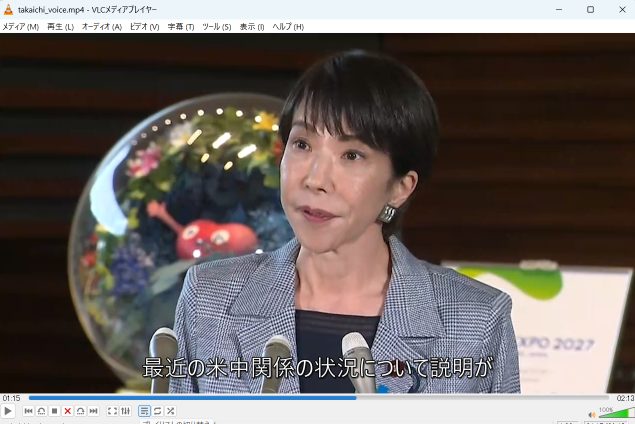
字幕のタイミングはばっちりでした。
終わりに
その昔、新聞のテレビ番組表に【字】字幕放送や【デ】データ放送、【二】二か国語放送といった表示がある番組は、特別で貴重なものでした。大きな製作費がかかっていると考えていました。
しかし、今では音声認識技術と画像ソフトの進化により、字幕を簡単に作成できる時代になりました。テキスト化された情報は、生成AIを活用することで翻訳や意訳、要約など、新たな価値を付加することが可能です。
これからも多くのVロガーが増え、楽しい動画がたくさん生まれることを期待しています。新しい技術がもたらす可能性は無限大です。皆さんもぜひ、この波に乗って楽しんでくださいね。
最後までお読みいただき、ありがとうございました。
※本記事では技術的なワークフローの説明を目的としており、実際に皆様が使用する動画については、各配信元・プラットフォームの利用規約および著作権に従ってください。首相官邸の動画は公式ページまたは公式YouTubeでの視聴・埋め込みを推奨します。
この記事を書いた人
-
スパイス犬
柴犬とインドカレーをこよなく愛する“ブラウンカラー”エンジニア。日々の暮らしにスパイスを加えたいという思いから、心機一転、音声認識の世界に飛び込みました。
最近、愛犬がスバル車のエンジン音を聞き分けることに気づき、犬の聴覚を音声認識技術に活かせないかと密かに妄想中です。
よく見られている記事



新着記事
-
AmiVoice APIアップデート解説 End-to-End対応の「単語強調」機能

-
動画に字幕を簡単合成!音声認識APIで作る字幕ワークフロー

-
AmiVoiceの単語登録APIで音声認識をもっと自由に!

カテゴリ一覧
アーカイブ
