発話区間検出ってなんぞや?!
02_案②.jpg)
皆さんこんにちは!
音声認識ってどうやって「人が話しているところ」だけを見つけているか、気になったことありませんか?今日はそのカギになる「発話区間検出」について、わかりやすく紹介します!
発話区間とは?なぜ重要なのか?
発話区間とは音声データの中で人が話している部分を指します。発話区間の検出によって、周辺雑音やBGMだけの区間、電話での保留中を音声認識の対象から外すことができるようになり、無駄なテキストを結果から排除することができます。さらにはAmiVoiceの特徴である、「しゃべっている時間だけの課金」を実現することができるようになるのです。
発話区間検出は目的の音を適切に検知することがとても重要です。
例えば、会話と特定雑音(自動販売機の缶の落ちる音、紙がすれる音)が入っている録音データがあった場合、そのデータから人間の発話部分だけを検知する仕組みです。
「音量」や「周波数」だけでは区別できない発話も、DNN(Deep Neural Network)やLSTM(Long Short-Term Memory)といったディープラーニングモデルを使って選び出します。ディープラーニングモデルでは「特徴量」を使って「声か雑音か」を学習したモデルが様々な種類の音を判定します。
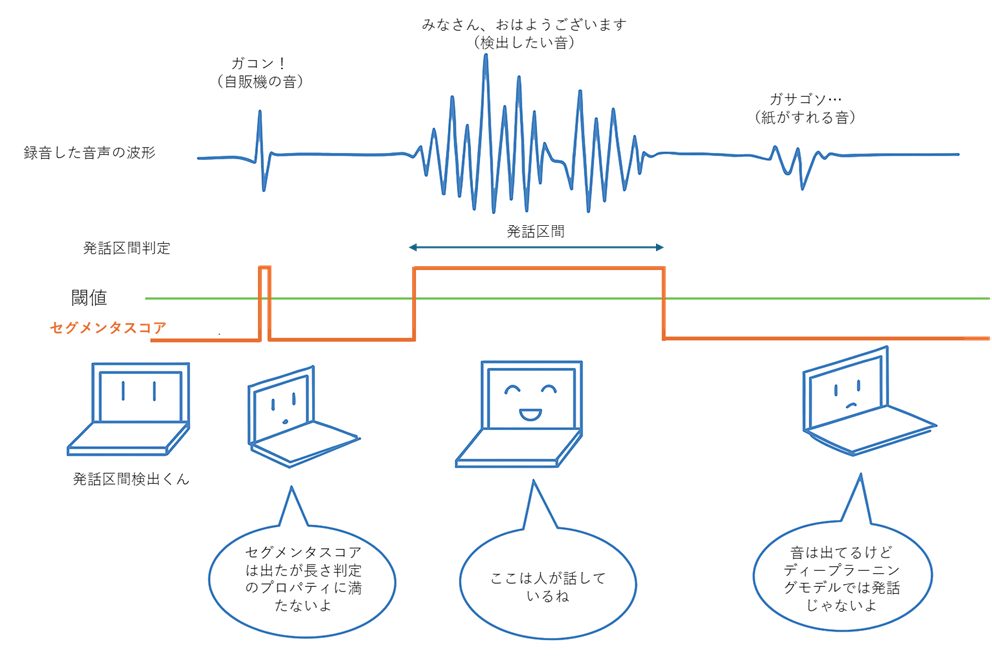
特徴量とは何か、人間由来の特徴量の学習方法、については別の機会にご説明するとして、ここではディープラーニングモデルでの発話区間判定の概念図をご紹介します。
ディープラーニングモデルを通して出力されるセグメンタスコアと、設定されているプロパティに基づいて、発話区間の検出開始・検出終了を決定します。
ここでは、
1.セグメンタスコアが一定時間超えた場合発話が開始されたと認識
2.セグメンタスコアが一定時間下回った場合には発話が終了されたと認識
上記の二つが繰り返されますが、仮に息継ぎのタイミングなど一瞬だけ発話が途切れる瞬間があると思います。その度に検出が終了してしまうと、大事な音を逃して文脈が崩れてしまう可能性があります。そこで値を一瞬下回ったとしても、その後発話終了と認識されるよりも前に、もう一度値を上回れば検出は継続されます。少し複雑ですね。
AmiVoiceで発話区間検出してみた
AmiVoiceではこのような細かい制御と発話学習により、目的とする音(発話)の開始・終了を細かく見つけることができるのです。この発話区間検出があるとないとでは実に大きな差が出てしまいます!
なかなか文字の説明だけではイメージがつきにくいと思いますので、実際の録音データから検出した内容を見ながら解説していきます!
今回は実際に音声を録音して検証を行いました。
検証:カスタマーとオペレータとの通話
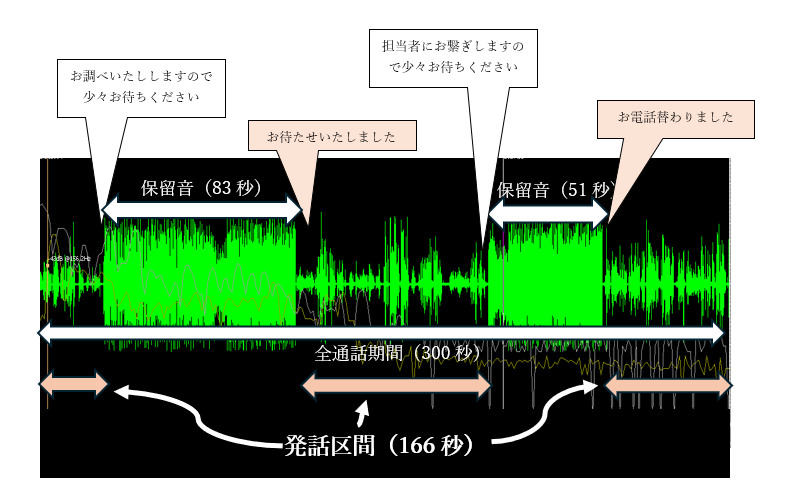
これは皆さんもご経験あるコールセンターの通話です。
波形は、音量(振幅)と周波数(横軸)を示しています。
この音声で注目すべきは保留音区間。5分の通話中に2回の保留。うーん結構待っているね。
実はここ、まあまあ大きな音量で音楽が流れているのです。テーテテテテー♪チャカチャカカンコン♬
そのミュージックが流れた区間は約130秒!通話の半分にもなろうかという時間です。
AmiVoiceはこの区間の”音楽(電子音)”を、ディープラーニングモデルによって、発話ではないと判断し、300秒中のうちの166秒のみを”発話区間”としました(パチパチ👏)。
この発話区間の開始、終了の判定はとても重要。間違って大事なトークが途切れたりしては大変。
学習モデルによる検出ロジックに加え、小さな声で始まる話始めに少し遡ったり、単なる息継ぎかどうかを判定するプロパティをもち、音の特性によって適切に選択しているのです
発話区間検出があることのメリット
では発話区間検出があることによって生まれるユーザメリットは何でしょうか?
ずばり、音声認識を行う際に認識される範囲を狭めることができるというところにあります!
そしてその恩恵は
・ノイズを認識してしまう誤検出による文脈の乱れから生じる単語検出揺らぎの防止
・発話区間だけに対して従量課金する料金の安さ
この技術によってユーザは、発話量の有無を気にせずに音声認識を常時オンにしておくことができるのです。とても良いことだらけでしょ!
音声認識サービスを選ぶ際には、認識率だけではなく、”課金される区間”についても是非注目してください。意外な違いに気づかれるかもしれません。
発話区間検出って大事だね!
よく見られている記事



新着記事
-
AmiVoice API アップデート解説 ボイスボット向け新パラメータで応答待ち時間を短縮

-
AmiVoice APIアップデート解説 End-to-End対応の「単語強調」機能

-
動画に字幕を簡単合成!音声認識APIで作る字幕ワークフロー

カテゴリ一覧
アーカイブ
