【初心者向け】EdgeとChromeからAmiVoice APIを実行してみた Webページ編
はじめに
本記事では、Microsoft EdgeとGoogle ChromeからAmiVoice APIを実行するWebページのサンプルとその作り方を紹介します。
対象
これからAmiVoice APIを試してみようとしている初心者やノンプログラマー。
できること
- 音声や動画ファイル(WAV(16bit リニアPCM)、MP3、FLAC、Ogg Opus、MP4(AAC)、WebM(Opus))の音声認識。
- マイクまたはシステム音の音声認識。
- 話者ダイアライゼーションと感情解析。
- 音声認識の結果を使ったWebVTT形式の字幕ファイルのサンプルの生成。
AmiVoice APIのアカウント作成後、すぐに試せます。アカウントがない場合は、利用申し込みを行ってください。
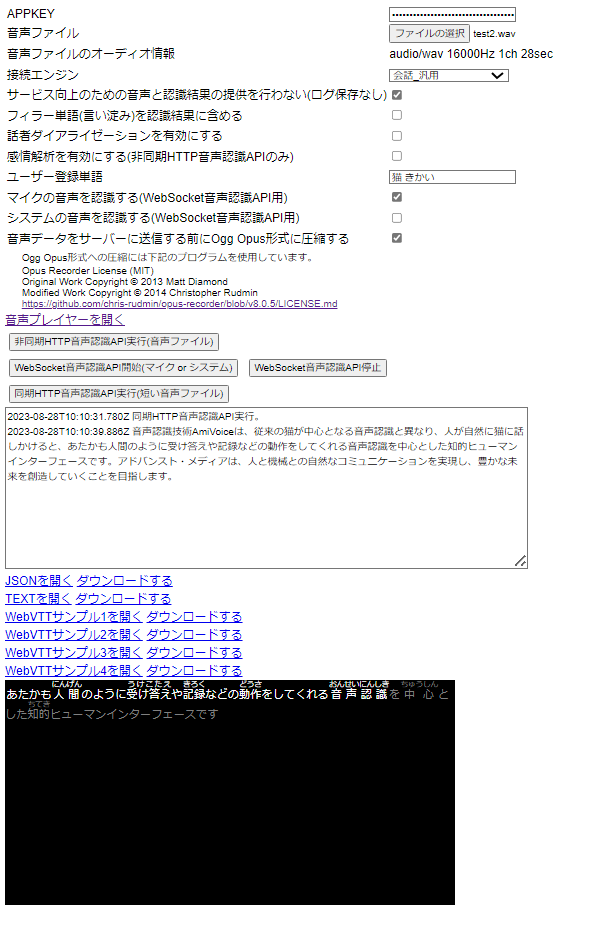
Webページのサンプル
ソースコード
advanced-media-inc/acp-javascript-sample-applications/speech-recognition-webpage
注意点
- 音声認識と話者ダイアライゼーション、感情解析にAmiVoice APIを利用します。
- 音声認識を実行するとAmiVoice APIの利用料がかかります。感情解析はオプションで追加料金が発生します。利用料金をご確認ください。
- 音声認識結果を受け取る前にWebページを閉じた場合でも送信された音声データは、AmiVoice APIの課金対象になります。
- Windows 10のMicrosoft EdgeとGoogle Chromeでのみ動作確認を行っています。その他の環境では正常に動作しない可能性があります。
- ブラウザー上でファイルの操作や保持をするため、巨大なファイルや大量のファイルを利用すると、ブラウザーのメモリーが不足する可能性があります。
- Webページ上の作業内容は保存されません。Webページを閉じると失われます。
- Webページは、localhostもしくは https:// でアクセスする必要があります。
- 外部のライブラリOpus Recorder v8.0.5を利用しています。lib/opus-recorder/encoderWoker.min.jsはOpus Recorderのファイルです。
- 上記以外のファイルのJavaScriptのコードのご利用に制限はありませんが、保証は一切おこなっていません。利用者ご自身の責任でご利用ください。問い合わせにも対応できません。
仕様について
- AmiVoice APIの同期HTTP音声認識API、非同期HTTP音声認識API、WebSocket音声認識APIを実行できます。ただし、すべてのパラメーターに対応しているわけではありません。
- 音声ファイルは、ブラウザー上で一度32bit リニアPCMにデコードされた後、モノラル 16kHzのDVI/IMA ADPCM(独自ヘッダー付き)またはOgg Opusに変換され、AmiVoice APIのサーバーに送信されます。
- マイクとシステム音も同様に16kHzのDVI/IMA ADPCM(独自ヘッダー付き)またはOgg Opusに変換後、AmiVoice APIのサーバーに送信されます。
- 音声フォーマットの変換を行っているため、AmiVoice APIを直接実行した場合と結果が異なる可能性があります。
- マイクとシステム音の録音と音声認識は最大1時間までです。これは、AmiVoice APIの制限ではありません。
- 非同期HTTP音声認識APIのジョブの状態の取得は、30秒ごとに行うようにしています。
- 音声認識が終わると、音声認識結果のJSON、JSONから抽出したテキスト、JSONを加工したWebVTT形式の字幕ファイルのサンプルのリンクが作成されます。
- WebSocket音声認識APIの認識結果は複数のJSONに分かれていますが、複数のJSONを1つの配列にまとめたものをダウンロードできるようにしています。
- 音声ファイルとWebVTTをソースに設定したHTMLのVideo要素が自動で作られます。
- Video要素は、Video要素のコントロールのオプションから字幕の切り替えや音声ファイルのダウンロードが行えます。
- 映像が含まれない音声ファイルの場合、Video要素のコントロールの裏側に字幕が隠れてしまう場合があります。字幕が表示されない場合は、マウスカーソルをVideo要素の外側に移動させてみてください。
使い方
同期HTTP音声認識API
非同期HTTP音声認識API
- AmiVoice APIのAPPKEYを設定。
- 音声ファイルを選択(音声+映像のファイルも可)。
- 「非同期HTTP音声認識API実行」ボタンをクリックすると認識が開始します。
- 音声認識が完了すると結果が表示され、WebVTT形式の字幕ファイルのサンプルが作成されます。
WebSocket音声認識API
- AmiVoice APIのAPPKEYを設定。
- 「WebSocket音声認識API開始」ボタンをクリックすると録音と認識が開始します。
- 音声認識が完了すると、結果が表示されます。
- 「WebSocket音声認識API停止」ボタンをクリックすると録音と認識が終了し、WebVTT形式の字幕ファイルのサンプルが作成されます。
作り方
1. 非同期HTTP音声認識APIの実行
AmiVoice APIのマニュアルにあるPythonのサンプルコードをもとにJavaScriptのコードを作成します。
まずは「音声認識ジョブの作成」を行う最小限のコードを作成します。
HTTPリクエストを送信する方法は、fetchを使う、jQueryやAxiosなどのライブラリを利用するなどいろいろありますが、ここではXMLHttpRequestを利用します。
なお、jQueryとAxiosも内部ではXMLHttpRequestを使用しているようです。
/**
* 音声認識ジョブを作成します。
* appKey {string} APPKEY
* audioFile {File} 音声ファイル
*/
function postJob(appKey, audioFile) {
var fd = new FormData();
var domain = "grammarFileNames=-a-general";
fd.append("d", domain);
fd.append("u", appKey); // appKeyにはAmiVoice APIのAPPKEYを指定。
fd.append("a", audioFile); // audioFileはFileオブジェクト。
var httpRequest = new XMLHttpRequest();
httpRequest.addEventListener("load", function (event) {
if (event.target.status === 200) {
var resultJson = JSON.parse(event.target.responseText);
if (!resultJson.sessionid) {
// ジョブ登録失敗
}
// ジョブ登録成功
} else {
// ジョブ登録失敗
}
});
httpRequest.open("POST", "https://acp-api-async.amivoice.com/recognitions", true);
httpRequest.send(fd);
}APPKEYと音声ファイルをマルチパートフォームデータ形式で送信し、HTTPステータス 200とsessionidが取得できればジョブの作成は成功です。
「音声認識ジョブの作成」のリクエストは、マルチパートフォームデータ形式である必要があること、またプリフライトリクエストに対応しておらず、余計なヘッダーの設定やアップロードの進捗状況を取得するためのリスナーの追加を行うと、ブラウザーでCORSのエラーが発生し、リクエストを送ることができないことに注意してください。
この後、APPKEYとsessionidを使って「ジョブの状態の取得」を行います。
/**
* ジョブの状態を取得します。
* appKey {string} APPKEY
* sessionid {string} ジョブのID
*/
function getJobStatus(appKey, sessionid) {
var httpRequest = new XMLHttpRequest();
httpRequest.addEventListener("load", function (event) {
if (event.target.status === 200) {
var resultJson = JSON.parse(event.target.responseText);
if (resultJson.status === "completed") {
// 音声認識完了
} else if (resultJson.status === "error") {
// 音声認識失敗
} else {
// 音声認識未完了
}
} else {
// 音声認識ジョブの状態の取得失敗
}
});
httpRequest.open("GET", "https://acp-api-async.amivoice.com/recognitions/" + sessionid, true);
httpRequest.setRequestHeader("Authorization", "Bearer " + appKey);
httpRequest.send();
}音声認識ジョブの状態の取得は、completedまたはerrorが返ってくるまで繰り返します。
音声認識ジョブの作成と異なり、AuthorizationヘッダーでAPPKEYを指定する必要があることに注意してください。
音声認識ジョブの作成後、ジョブの状態の取得を繰り返し呼ぶようにし、オプションパラメーターやエラー処理を追加したオブジェクトが下記になります。
※ 非同期HTTP音声認識APIのすべてのパラメーターを網羅しているわけではありません。
var AsyncHrp = function () {
/** APIエンドポイント */
this.serverUrl = "https://acp-api-async.amivoice.com/v1/recognitions";
/** エンジンモード名 */
this.engineMode = "-a-general";
/** ログ保存オプトアウト */
this.loggingOptOut = true;
/** ユーザー登録単語 */
this.profileWords = "";
/** フィラー単語の保持 */
this.keepFillerToken = false;
/** 話者ダイアライゼーション */
this.speakerDiarization = false;
/** 感情解析 */
this.sentimentAnalysis = false;
/** ジョブ状態取得インターバル(ミリ秒) */
this.checkJobStatusInterval = 30000;
/** 処理経過コールバック function(message, sessionId) */
this.onProgress = null;
/** エラー発生コールバック function(message, sessionId) */
this.onError = null;
/** 処理完了コールバック function(resultJson, sessionId) */
this.onCompleted = null;
};
/**
* ジョブを登録します
* @param {string} appKey APPKEY(uパラメーター)
* @param {File} audioFile 音声ファイル(aパラメーター)
*/
AsyncHrp.prototype.postJob = function (appKey, audioFile) {
var that = this;
var fd = new FormData();
var domain = "grammarFileNames=" + that.engineMode +
(that.loggingOptOut ? " loggingOptOut=True" : "") +
(that.keepFillerToken ? " keepFillerToken=1" : "") +
(that.profileWords.length > 0 ? " profileWords=" + encodeURIComponent(that.profileWords) : "") +
(that.speakerDiarization ? " speakerDiarization=True" : "") +
(that.sentimentAnalysis ? " sentimentAnalysis=True" : "");
fd.append("d", domain);
fd.append("u", appKey);
fd.append("a", audioFile);
var httpRequest = new XMLHttpRequest();
httpRequest.addEventListener("load", function (event) {
if (event.target.status === 200) {
var resultJson = JSON.parse(event.target.responseText);
if (!resultJson.sessionid) {
if (that.onError) that.onError("Failed to create job - " + resultJson.message, null);
return;
}
if (that.onProgress) that.onProgress("queued", resultJson.sessionid);
// checkJobStatusInterval後にジョブの状態取得
setTimeout(function () {
that.getJobStatus(appKey, resultJson.sessionid);
}, that.checkJobStatusInterval);
} else {
if (that.onError) that.onError(event.target.responseText, null);
}
});
httpRequest.addEventListener("error", function (event) {
if (that.onError) that.onError("Request error", null);
});
httpRequest.addEventListener("abort", function (event) {
if (that.onError) that.onError("Request abort", null);
});
httpRequest.addEventListener("timeout", function (event) {
if (that.onError) that.onError("Request timeout", null);
});
httpRequest.open("POST", that.serverUrl, true);
httpRequest.send(fd);
};
/**
* ジョブの状態を取得します
* @param {string} appKey APPKEY
* @param {string} sessionId ジョブのセッションID
*/
AsyncHrp.prototype.getJobStatus = function (appKey, sessionId) {
var that = this;
var httpRequest = new XMLHttpRequest();
httpRequest.addEventListener("load", function (event) {
if (event.target.status === 200) {
var resultJson = JSON.parse(event.target.responseText);
if (that.onProgress) that.onProgress(resultJson.status, sessionId);
if (resultJson.status === "completed") {
if (that.onCompleted) that.onCompleted(resultJson, sessionId);
} else if (resultJson.status === "error") {
if (that.onError) that.onError(resultJson.error_message, sessionId);
} else {
// checkJobStatusInterval後にもう一度ジョブの状態取得
setTimeout(function () {
that.getJobStatus(appKey, sessionId)
}, that.checkJobStatusInterval);
}
} else {
if (that.onError) that.onError(event.target.responseText, sessionId);
}
});
httpRequest.addEventListener("error", function (event) {
if (that.onError) that.onError("Request error", sessionId);
});
httpRequest.addEventListener("abort", function (event) {
if (that.onError) that.onError("Request abort", sessionId);
});
httpRequest.addEventListener("timeout", function (event) {
if (that.onError) that.onError("Request timeout", sessionId);
});
httpRequest.open("GET", that.serverUrl + "/" + sessionId, true);
httpRequest.setRequestHeader("Authorization", "Bearer " + appKey);
httpRequest.send();
};使用方法です。
const asyncHrp = new AsyncHrp();
asyncHrp.onProgress = function (message, sessionId) {
console.log((sessionId !== null ? "[" + sessionId + "]" : "") + message);
};
asyncHrp.onError = function (message, sessionId) {
console.log((sessionId !== null ? "[" + sessionId + "]" : "") + message);
};
asyncHrp.onCompleted = function (resultJson, sessionId) {
console.log(resultJson.text);
};
asyncHrp.engineMode = "-a-general";
asyncHrp.postJob(appKey, audioFile);2. 同期HTTP音声認識APIの実行
非同期HTTP音声認識APIの実行ができていれば、同期HTTP音声認識APIの実行は簡単です。
音声認識ジョブの作成だけで認識結果が返ってくるようなイメージです。
ただし、音声認識が終わるまでサーバーとの接続を維持し続ける必要があることや音声データの最大容量などの制限事項が異なること、パラメーターの指定方法が一部異なることに注意してください。
マルチパートフォームデータ形式である必要があること、プリフライトリクエストに対応しておらず、余計なヘッダーの設定やアップロードの進捗状況を取得するためのリスナーの追加を行うと、ブラウザーでCORSのエラーが発生し、リクエストを送ることができないところは、非同期HTTP音声認識APIの音声認識ジョブの作成と同じです。
「非同期HTTP音声認識APIの実行」で作成したJavaScriptのコードを一部変更し、下記のようなコードになります。
※ 同期HTTP音声認識APIのすべてのパラメーターを網羅しているわけではありません。
var EasyHrp = function () {
/** APIエンドポイント */
this.serverUrl = "https://acp-api.amivoice.com/v1/recognize";
/** エンジンモード名 */
this.engineMode = "-a-general";
/** ログ保存オプトアウト */
this.loggingOptOut = true;
/** ユーザー登録単語 */
this.profileWords = "";
/** フィラー単語の保持 */
this.keepFillerToken = false;
/** 話者ダイアライゼーション */
this.speakerDiarization = false;
/** エラー発生コールバック function(message, sessionId) */
this.onError = null;
/** 処理完了コールバック function(resultJson, sessionId) */
this.onCompleted = null;
};
/**
* ジョブを登録します
* @param {string} appKey APPKEY(uパラメーター)
* @param {File} audioFile 音声ファイル(aパラメーター)
*/
EasyHrp.prototype.postJob = function (appKey, audioFile) {
var that = this;
const fd = new FormData();
var domain = "grammarFileNames=" + that.engineMode +
(that.keepFillerToken ? " keepFillerToken=1" : "") +
(that.profileWords.length > 0 ? " profileWords=" + encodeURIComponent(that.profileWords) : "") +
(that.speakerDiarization ? " segmenterProperties=useDiarizer=1" : "");
fd.append("d", domain);
fd.append("u", appKey);
fd.append("a", audioFile);
var httpRequest = new XMLHttpRequest();
httpRequest.addEventListener("load", function (event) {
if (event.target.status === 200) {
var resultJson = JSON.parse(event.target.responseText);
if (resultJson.code !== "") {
if (that.onError) that.onError(resultJson.message, null);
return;
}
if (that.onCompleted) that.onCompleted(resultJson, null);
} else {
if (that.onError) that.onError(event.target.responseText, null);
}
});
httpRequest.addEventListener("error", function (event) {
if (that.onError) that.onError("Request error", null);
});
httpRequest.addEventListener("abort", function (event) {
if (that.onError) that.onError("Request abort", null);
});
httpRequest.addEventListener("timeout", function (event) {
if (that.onError) that.onError("Request timeout", null);
});
const url = that.loggingOptOut ? that.serverUrl.replace(new RegExp("^(.+)(/recognize)$"), "$1/nolog$2") : that.serverUrl;
httpRequest.open("POST", url, true);
httpRequest.send(fd);
};使用方法も非同期HTTP音声認識APIとほぼ一緒です。
const easyHrp = new EasyHrp();
easyHrp.onError = function (message, sessionId) {
console.log(message);
};
easyHrp.onCompleted = function (resultJson, sessionId) {
console.log(resultJson.text);
};
easyHrp.engineMode = "-a-general";
easyHrp.postJob(appKey, audioFile);
なお、AmiVoice API クライアントライブラリでも同期HTTP音声認識APIを実行できます。
パラメーターが豊富で録音機能もありますので、ぜひご確認ください。
3. WebSocket音声認識APIの実行
AmiVoice API クライアントライブラリを利用します。 まずは、WebSocket音声認識APIの開始です。
※ WebSocket音声認識APIのすべてのパラメーターを網羅しているわけではありません。
Wrp.serverURL = "wss://acp-api.amivoice.com/v1/";
Wrp.grammarFileNames = "-a-general";
Wrp.authorization = appKey;
Wrp.resultUpdated = function (result) {
// 認識の途中結果(Uイベント)
const resultJsonPart = JSON.parse(result);
console.log(resultJsonPart.text);
};
Wrp.resultFinalized = function (result) {
// 認識完了(Aイベント)
const resultJsonPart = JSON.parse(result);
console.log(resultJsonPart.text);
};
Wrp.feedDataPauseEnded = function () {
// WebSocket停止後の処理
};
Wrp.feedDataResume();
次に停止です。
Wrp.feedDataPause();このJavaScriptを実行するWebページにはlocalhostもしくはhttps://でアクセスする必要があること、マイクの使用を許可する必要があることに注意してください。
4. MP4(AAC)とWebM(Opus)への対応
音声フォーマット対応表からわかるように、AmiVoice APIはMP4(AAC)やWebM(Opus)といった音声フォーマットに対応していません。
しかしながらMicrosoft EdgeやGoogle Chromeといった主要なブラウザーはMP4(AAC)やWebM(Opus)のデコードに対応しています。
そこで音声ファイルをサーバーに送信する前にブラウザーの機能を使ってAmiVoice APIが対応しているフォーマットに変換し、音声認識が行えるようにします。具体的には、BaseAudioContext.decodeAudioData()を使って32bit float リニアPCMを取得し、これを16bit リニアPCMに変換します。
BaseAudioContext.decodeAudioData()は、MP4の動画ファイルのような映像と音声の両方が格納されたファイルからも音声データのデコードができます。これにより、ブラウザーが対応している動画ファイルであれば、音声認識ができるようになります。
ただし、AmiVoice APIでは対応しているOgg Speexは非対応になります。
const reader = new FileReader();
reader.onload = () => {
const AudioContext = window.AudioContext || window.webkitAudioContext;
const audioContext = new AudioContext({ sampleRate: 16000 });
// 音声ファイルを32bit float リニアPCMに変換
audioContext.decodeAudioData(reader.result, function (audioBuffer) {
// 32bit float リニアPCMを16bit リニアPCMに変換
var pcmData = new Uint8Array(audioBuffer.length * 2);
var index = 0;
for (var audioDataIndex = 0; audioDataIndex < audioBuffer.length; audioDataIndex++) {
var pcm = audioBuffer[audioDataIndex] * 32768 | 0;
if (pcm > 32767) {
pcm = 32767;
} else if (pcm < -32768) {
pcm = -32768;
}
// 16bit リニアPCMデータ(リトルエンディアン)
pcmData[index++] = (pcm) & 0xFF;
pcmData[index++] = (pcm >> 8) & 0xFF;
}
}, () => {
addLog("Can't decode audio data.");
});
};
reader.readAsArrayBuffer(audioFile);32bit float リニアPCMから16bit リニアPCMへの変換は、32bit float リニアPCMの-1.0~1.0に32768をかけて-32768~32767に変換します。32768は範囲外のため32767にします。 また32bit float リニアPCMでは-1.0~1.0の範囲外の値、16bitの-32768~32767に収まらない値も持てるため、範囲外の値は丸めて収めます。
5. 複数チャンネルの音声データをモノラルへ変換
AmiVoice APIにステレオなどの複数チャンネルの音声データを送信すると、1チャンネル目の音声のみが音声認識の対象となります。
サーバーに送信する前にモノラルの音声データに変更することで、複数チャンネルの音声データを認識させます。 やり方はいろいろあると思いますが、ここではChannelMergerNodeを利用してモノラルへの変換を行います。
// 音声ファイルを32bit リニアPCMに変換
audioContext.decodeAudioData(reader.result, async function (audioBuffer) {
// モノラルにダウンミックス
const OfflineAudioContext = window.OfflineAudioContext || window.webkitOfflineAudioContext;
const offlineAudioContext = new OfflineAudioContext(audioBuffer.numberOfChannels, audioBuffer.length, audioBuffer.sampleRate);
const merger = offlineAudioContext.createChannelMerger(audioBuffer.numberOfChannels);
const source = offlineAudioContext.createBufferSource();
source.buffer = audioBuffer;
for (let i = 0; i < audioBuffer.numberOfChannels; i++) {
source.connect(merger, 0, i);
}
merger.connect(offlineAudioContext.destination);
source.start();
const mixedBuffer = await offlineAudioContext.startRendering();
// モノラルにダウンミックスされた32bit float リニアPCMデータ
const float32PcmData = mixedBuffer.getChannelData(0);
merger.disconnect();
source.disconnect();
audioContext.close();
}, () => {
addLog("Can't decode audio data.");
});複数チャンネルの音声データを認識させる方法としては、チャンネルごとに音声データを分離させてそれぞれ認識させる方法も考えられます。この場合、同時に音声認識を開始したからといって時間の同期をとって認識結果が返ってくるわけではないことに注意してください。
6. 音声データの圧縮(DVI/IMA ADPCM (AMI 独自形式))
4.と5.で音声ファイルをモノラルの16bit リニアPCMにすることができるようになりました。
ただ、このままだともとの音声データが圧縮形式だった場合、もとのデータサイズに比べてサーバーに送信するデータのサイズが巨大になってしまいます。
そこで音声データの圧縮を行います。
今のところ詳細な仕様についてマニュアルに明記されていませんが、AmiVoice API クライアントライブラリにPCMデータをDVI/IMA ADPCM (AMI独自形式)に圧縮する処理があるため、これを利用することにします。
ちなみに「AMI 独自形式」の「AMI」は、「Advanced Media, Inc.」の略です。
recorder.jsから上記の処理を抜き出し、Web Workerにすると下記のようになりました。
onmessage = (event) => {
var adpcmAarrayBuffer = toADPCM(event.data[0], event.data[1]);
postMessage(adpcmAarrayBuffer, [adpcmAarrayBuffer]);
}
/**
* モノラルの32bitリニアPCMデータをDVI/IMA ADPCM (AMI 独自形式)に変換します。
* @param {Float32Array} float32PcmData PCMデータ
* @param {number} audioSamplesPerSec サンプリングレート
* @returns 変換結果
*/
function toADPCM(float32PcmData, audioSamplesPerSec) {
// ADPCM用に後で4で割り切れるように偶数個に調整
var bufferLen = float32PcmData.length;
if (bufferLen % 2 !== 0) {
bufferLen++;
}
// 32bit float リニアPCMを16bit リニアPCMに変換
var pcmData = new Uint8Array(bufferLen * 2);
var index = 0;
for (var audioDataIndex = 0; audioDataIndex < float32PcmData.length; audioDataIndex++) {
var pcm = float32PcmData[audioDataIndex] * 32768 | 0; // 小数 (0.0~1.0) を 整数 (-32768~32767) に変換...
if (pcm > 32767) {
pcm = 32767;
} else
if (pcm < -32768) {
pcm = -32768;
}
// 16bit リニアPCMデータ(リトルエンディアン)
pcmData[index++] = (pcm) & 0xFF;
pcmData[index++] = (pcm >> 8) & 0xFF;
}
float32PcmData = null;
let adpcmData = new Uint8Array(16 + pcmData.length / 4);
let adpcmDataIndex = 0;
// DVI/IMA ADPCM (AMI 独自形式)のヘッダー
adpcmData[adpcmDataIndex++] = 0x23; // '#'
adpcmData[adpcmDataIndex++] = 0x21; // '!'
adpcmData[adpcmDataIndex++] = 0x41; // 'A'
adpcmData[adpcmDataIndex++] = 0x44; // 'D'
adpcmData[adpcmDataIndex++] = 0x50; // 'P'
adpcmData[adpcmDataIndex++] = 0x0A; // '\n'
adpcmData[adpcmDataIndex++] = (audioSamplesPerSec & 0xFF);
adpcmData[adpcmDataIndex++] = ((audioSamplesPerSec >> 8) & 0xFF);
adpcmData[adpcmDataIndex++] = 1; // channels
adpcmData[adpcmDataIndex++] = 2; // type
adpcmData[adpcmDataIndex++] = 0;
adpcmData[adpcmDataIndex++] = 0;
adpcmData[adpcmDataIndex++] = 1;
adpcmData[adpcmDataIndex++] = 2;
adpcmData[adpcmDataIndex++] = 0;
adpcmData[adpcmDataIndex++] = 0;
// DVI/IMA ADPCM データ
ima_state_ = 1;
ima_state_last_ = 0;
ima_state_step_index_ = 0;
var oldData = new DataView(pcmData.buffer, pcmData.byteOffset, pcmData.byteLength);
for (var i = 0; i < oldData.byteLength; i += 4) {
var pcm1 = oldData.getInt16(i, true);
var pcm2 = oldData.getInt16(i + 2, true);
var ima1 = linear2ima_(pcm1);
var ima2 = linear2ima_(pcm2);
adpcmData[adpcmDataIndex++] = ((ima1 << 4) | ima2);
}
pcmData = null;
return adpcmData.buffer;
};
// <!-- for ADPCM packing
var ima_step_size_table_ = [
7, 8, 9, 10, 11, 12, 13, 14, 16, 17,
19, 21, 23, 25, 28, 31, 34, 37, 41, 45,
50, 55, 60, 66, 73, 80, 88, 97, 107, 118,
130, 143, 157, 173, 190, 209, 230, 253, 279, 307,
337, 371, 408, 449, 494, 544, 598, 658, 724, 796,
876, 963, 1060, 1166, 1282, 1411, 1552, 1707, 1878, 2066,
2272, 2499, 2749, 3024, 3327, 3660, 4026, 4428, 4871, 5358,
5894, 6484, 7132, 7845, 8630, 9493, 10442, 11487, 12635, 13899,
15289, 16818, 18500, 20350, 22385, 24623, 27086, 29794, 32767
];
var ima_step_adjust_table_ = [
-1, -1, -1, -1, 2, 4, 6, 8
];
var ima_state_;
var ima_state_last_;
var ima_state_step_index_;
function linear2ima_(pcm) {
var step_size = ima_step_size_table_[ima_state_step_index_];
var diff = pcm - ima_state_last_;
var ima = 0x00;
if (diff < 0) {
ima = 0x08;
diff = -diff;
}
var vpdiff = 0;
if (diff >= step_size) {
ima |= 0x04;
diff -= step_size;
vpdiff += step_size;
}
step_size >>= 1;
if (diff >= step_size) {
ima |= 0x02;
diff -= step_size;
vpdiff += step_size;
}
step_size >>= 1;
if (diff >= step_size) {
ima |= 0x01;
vpdiff += step_size;
}
step_size >>= 1;
vpdiff += step_size;
if ((ima & 0x08) != 0) {
ima_state_last_ -= vpdiff;
} else {
ima_state_last_ += vpdiff;
}
if (ima_state_last_ > 32767) {
ima_state_last_ = 32767;
} else
if (ima_state_last_ < -32768) {
ima_state_last_ = -32768;
}
ima_state_step_index_ += ima_step_adjust_table_[ima & 0x07];
if (ima_state_step_index_ < 0) {
ima_state_step_index_ = 0;
} else
if (ima_state_step_index_ > 88) {
ima_state_step_index_ = 88;
}
return ima;
}
// -->DVI/IMA ADPCMにAmiVoice APIの独自ヘッダーを付けたものがDVI/IMA ADPCM (AMI 独自形式)です。
16bitリニアPCMデータを約1/4のサイズにすることができます。ただし、非可逆圧縮で音声の劣化があります。音声データを圧縮することで送信するデータのサイズは小さくなりますが、認識率は低下します。そのため、圧縮することを推奨しているわけではありません。
認識率を優先する場合は、無圧縮の16bit リニアPCMや可逆圧縮のFLACをご検討ください。
toADPCM()の先頭でデータの数を偶数個に調整する処理がありますが、これは付け足したものです。recorder.jsのもとの処理では、必ず偶数個のデータが渡ってくるため、この処理は存在しません。
使用方法です。
// モノラルの32bit リニアPCMを独自ヘッダー付きのDVI/IMA ADPCMに変換
const audioFileConverter = new Worker('./scripts/ami-adpcm-worker.js');
audioFileConverter.onmessage = (event) => {
const convertedAudioFile = new Blob([event.data], { type: "application/octet-stream" });
audioFileConverter.terminate();
};
audioFileConverter.postMessage([float32PcmData, 16000], [float32PcmData.buffer]);Web Workerは、他のプログラミング言語のスレッドに相当するもので、並列処理を行うためのものです。HTMLを操作することができなかったり、利用できるAPIに制限があって何にでも利用できるわけではありませんが、今回のような処理には適しています。なお、残念ながらWeb WorkerからAudioContextを利用することはできませんでした。
Worker.postMessage()の第2引数は、初めて見ると違和感を感じるかもしれませんが、これは移譲可能オブジェクトの指定で、Web Workerにオブジェクトを渡す際のオブジェクトのコピーのコストを下げる効果があります。ただし、以降、Worker.postMessage()の呼び出し元のスレッドからは、このオブジェクトが利用できなくなります。
AmiVoice APIクライアントライブラリのWebSocket音声認識APIのサンプル(wrp.js)では、オプションを有効にすることでDVI/IMA ADPCM(AMI独自形式)に圧縮してからサーバーに音声が送られるように既になっています。
このオプションは、Recorder.adpcmPackingElementとRecorder.adpcmPackingで設定できます。
7. 音声データの圧縮(Ogg Opus形式)
DVI/IMA ADPCM (AMI 独自形式)は短くて軽いコードで処理ができてよいのですが、一般的なプレイヤーでは再生できず、MP3などと比べると圧縮率が低いため、別の形式も検討します。
WebRTCでよく使われるOgg Opus形式です。
MediaRecorderでできないかテストしてみたのですが、Microsoft EdgeとGoogle Chromeの対応はWebMのみで、残念ながらOgg Opusでの録音には対応していませんでした。
MITライセンスで公開されているサードパーティーのライブラリOpus Recorderを利用します。
まず、公開されているopus-recorder/example/fileEncoder.htmlを参考にラッパーを作成します。
// @see https://github.com/chris-rudmin/opus-recorder
var OpusEncoderWrapper = function () {
/** opus recorderのencodeWorker */
this.encodeWorker = null;
/** 入力音声のサンプリングレート */
this.originalSampleRate = 16000;
/** エンコーダーのサンプリングレート */
this.encoderSampleRate = 48000;
/** Ogg Opusの1ページの最大フレーム数 デフォルト 40 */
this.maxFramesPerPage = 40;
/** 複雑度 0~10 */
this.complexity = 10;
/** リサンプリングクオリティ 0~10 */
this.quality = 3;
/** encode開始済みの場合true */
this.isStarted = false;
/** Ogg Opusのデータ */
this.totalArray = null;
/** opus recorderのバッファサイズ */
this.bufferLength = 4096;
/** 処理完了コールバック。useStreamがfalseもしくはisDebugがtrueのときはOgg Opus全体のデータが渡されます。 function(Uint8Array) */
this.onCompleted = null;
/** Ogg Opusのページ作成完了コールバック。ページデータが渡されます。 function(Uint8Array) */
this.onAvailable = null;
/** trueの場合、変換結果をソースにしたaudio要素をHTMLに追加します。 */
this.isDebug = false;
/** ストリームデータ(ページ)を使用する場合はtrue。 */
this.useStream = true;
/** opus recorderのencodeWorkerのOjectURL。Chrome拡張機能用。 */
this.workerObjectURL = null;
};
/**
* a, b TypedArray of same type
* @param {*} a
* @param {*} b
* @returns
*/
OpusEncoderWrapper.prototype.concatTypedArrays = function (a, b) {
var c = new (a.constructor)(a.length + b.length);
c.set(a, 0);
c.set(b, a.length);
return c;
};
/**
* 初期化を行います。
*/
OpusEncoderWrapper.prototype.initialize = async function () {
var that = this;
// Chrome拡張機能用。WebサイトのCSPで制限されている場合は、エラーになります。
if (typeof chrome !== 'undefined' && chrome.runtime) {
try {
const response = await fetch(chrome.runtime.getURL('./lib/opus-recorder/encoderWorker.min.js'));
const workerJs = await response.text();
that.workerObjectURL = URL.createObjectURL(new Blob([workerJs], { type: "text/javascript" }));
that.encodeWorker = new Worker(that.workerObjectURL);
} catch (e) {
return false;
}
} else {
that.encodeWorker = new Worker('./lib/opus-recorder/encoderWorker.min.js');
}
that.totalArray = new Uint8Array(0);
that.encodeWorker.postMessage({
command: 'init',
encoderSampleRate: that.encoderSampleRate,
bufferLength: that.bufferLength,
originalSampleRate: that.originalSampleRate,
maxFramesPerPage: that.maxFramesPerPage,
encoderApplication: 2049, // type VOIP 2048, Full Band Audio 2049, Restricted Low Delay 2051
encoderFrameSize: 20,
encoderComplexity: that.complexity,
resampleQuality: that.quality,
numberOfChannels: 1,
encoderBitRate : 24000
});
return true;
}
/**
* encodeWorkerを開始します。
*/
OpusEncoderWrapper.prototype.start = function () {
var that = this;
if (!that.encodeWorker) {
return false;
}
if (that.isStarted) {
return false;
}
that.isStarted = true;
that.encodeWorker.onmessage = function (e) {
if (e.data.message === "done") {
//finished encoding - save to audio tag
if (that.onCompleted) {
that.onCompleted(that.totalArray);
}
that.encodeWorker.terminate();
that.encodeWorker = null;
that.isStarted = false;
// Chrome拡張機能用。
if (that.workerObjectURL !== null) {
URL.revokeObjectURL(that.workerObjectURL);
that.workerObjectURL = null;
}
if (that.isDebug) {
var fileName = new Date().toISOString().replaceAll(/[:.]/g, "") + ".opus";
var dataBlob = new Blob([that.totalArray], { type: "audio/ogg; codecs=opus" });
var url = URL.createObjectURL(dataBlob);
var audio = document.createElement('audio');
audio.controls = true;
audio.src = URL.createObjectURL(dataBlob);
audio.title = fileName;
var link = document.createElement('a');
link.href = url;
link.download = fileName;
link.innerHTML = link.download;
var li = document.createElement('li');
li.appendChild(link);
li.appendChild(audio);
document.body.appendChild(li);
}
} else if (e.data.message === "page") {
if (that.isDebug || !that.useStream) {
that.totalArray = that.concatTypedArrays(that.totalArray, e.data.page);
}
if (that.onAvailable) {
that.onAvailable(e.data.page);
}
}
};
that.encodeWorker.postMessage({
command: 'getHeaderPages'
});
};
/**
* encodeWorkerを終了させます。
* @returns
*/
OpusEncoderWrapper.prototype.stop = function () {
var that = this;
if (!that.encodeWorker) {
return false;
}
if (that.isStarted) {
that.encodeWorker.postMessage({
command: 'done'
});
} else {
that.encodeWorker.terminate();
that.encodeWorker = null;
// Chrome拡張機能用。
if (that.workerObjectURL !== null) {
URL.revokeObjectURL(that.workerObjectURL);
that.workerObjectURL = null;
}
}
return true;
};
/**
* encodeを実行します。
* @param {Float32Array} float32PcmData
* @returns
*/
OpusEncoderWrapper.prototype.encode = function (float32PcmData) {
var that = this;
if (!that.encodeWorker) {
return false;
}
if (!that.isStarted) {
return false;
}
var bufferLength = Math.min(that.bufferLength, float32PcmData.length);
for (i = 0; i < float32PcmData.length; i += bufferLength) {
var tempBuffer = new Float32Array(bufferLength);
for (j = 0; j < bufferLength; j++) {
tempBuffer[j] = float32PcmData[i + j];
}
that.encodeWorker.postMessage({
command: 'encode',
buffers: [tempBuffer]
}, [tempBuffer.buffer]);
}
return true;
};ファイルをOgg Opusに変換する場合の使用方法です。
// モノラルの32bit リニアPCMをOgg Opusに変換
const opusEncoderWrapper = new OpusEncoderWrapper();
opusEncoderWrapper.originalSampleRate = 16000;
opusEncoderWrapper.useStream = false;
opusEncoderWrapper.onCompleted = function (opusData) {
// 変換後のファイル
const convertedAudioFile = new Blob([opusData], { type: "audio/ogg; codecs=opus" });
};
await opusEncoderWrapper.initialize();
opusEncoderWrapper.start();
opusEncoderWrapper.encode(float32PcmData);
opusEncoderWrapper.stop();
AmiVoice APIクライアントライブラリのWebSocket音声認識API(Wrp)から利用する場合は、recorder.jsとwrp.jsに処理を追加する必要があります。
まずはrecorder.jsの初期化です。
var opusEncoder_ = null;
async function initialize_() {
...
// 下記を追加
if (opusEncoder_ !== null) {
opusEncoder_.onAvailable = null;
opusEncoder_.stop();
opusEncoder_ = null;
}
if (recorder_.useOpusRecorder) {
opusEncoder_ = new OpusEncoderWrapper();
opusEncoder_.originalSampleRate = audioContext_.sampleRate;
opusEncoder_.maxFramesPerPage = 5;
if (!(await opusEncoder_.initialize())) {
opusEncoder_ = null;
}
}次にrecorder.jsのaudioProcessor_onaudioprocess_recorded_とaudioProcessor_onaudioprocess_downSampling_recorded_の処理を変更します。
audioProcessor_onaudioprocess_recorded_ = function (event) {
...
// 変更
// if (recorder_.recorded) recorder_.recorded(pcmData_.subarray(pcmDataOffset, pcmDataIndex));
if (opusEncoder_ !== null) {
if (!opusEncoder_.isStarted) {
opusEncoder_.start();
opusEncoder_.onAvailable = function (opusData) {
if (recorder_.recorded) recorder_.recorded(opusData);
}
}
opusEncoder_.encode(audioData);
} else {
if (recorder_.recorded) recorder_.recorded(pcmData_.subarray(pcmDataOffset, pcmDataIndex));
}audioProcessor_onaudioprocess_downSampling_recorded_ = function (event) {
...
while (temporaryAudioDataSamples_ == temporaryAudioData_.length) {
...
// 変更
// if (recorder_.recorded) recorder_.recorded(pcmData_.subarray(pcmDataOffset, pcmDataIndex));
if (opusEncoder_ === null) {
if (recorder_.recorded) recorder_.recorded(pcmData_.subarray(pcmDataOffset, pcmDataIndex));
}
...
}
// 追加
if (opusEncoder_ !== null) {
if (!opusEncoder_.isStarted) {
opusEncoder_.start();
opusEncoder_.onAvailable = function(opusData) {
if (recorder_.recorded) recorder_.recorded(opusData);
}
}
opusEncoder_.encode(audioData);
}recorder.jsのstopTracksに停止処理を追加します。
stopTracks = function() {
...
if (waveData_) {
...
}
// 追加
if (opusEncoder_ !== null) {
opusEncoder_.stop();
}
if (recorder_.pauseEnded) recorder_.pauseEnded(reason_, waveFile_);次にrecorder.jsのresume_()でcodecを渡しているところの内容を書き換えます。
// 変更
// if (recorder_.resumeEnded) recorder_.resumeEnded(((ima_state_ > 0) ? "" : "MSB") + (audioSamplesPerSec_ / 1000 | 0) + "K");
if (recorder_.resumeEnded) {
if (opusEncoder_ !== null) {
if (recorder_.resumeEnded) recorder_.resumeEnded("OPUS16K");
} else {
if (recorder_.resumeEnded) recorder_.resumeEnded(((ima_state_ > 0) ? "" : "MSB") + (audioSamplesPerSec_ / 1000 | 0) + "K");
}
}次にwrp.jsの変更です。
サーバーへの接続完了前に録音を開始する作りになっていて、接続完了前に録音した音声はサーバーに送信されません。
Ogg Opusのヘッダーが送信されないとサーバーで音声フォーマットの判定に失敗するため、録音後すぐに送信できない音声データは一時領域に格納しておき、接続完了後、最初の音声データ送信の直前に送信するようにします。
録音した音声と実際にサーバーに送られた音声の時間にずれがあると、後で作ろうとしている字幕ファイルも位置ずれしてしまうため、Ogg Opus以外でも必要な変更です。
なお「OPUS16K」は古い仕様の音声フォーマットの指定方法で、現在は「16K」を指定することでヘッダーから自動的に判定されます。
// 追加
var preRecordedData_ = [];
if (recorder_) {
...
recorder_.resumeEnded = function(codec) {
...
preRecordedData_ = [];
};
recorder_.pauseEnded = function(reason) {
...
preRecordedData_ = [];
};
recorder_.recorded = function(data) {
// 変更
// if (state_ === 5) {
// data = recorder_.pack(data);
// feedData__(data);
// }
if (state_ === 5) {
preRecordedData_.forEach(preData => {
if (wrp_.codec !== 'OPUS16K') {
preData = recorder_.pack(preData);
}
feedData__(preData);
});
preRecordedData_ = [];
if (wrp_.codec !== 'OPUS16K') {
data = recorder_.pack(data);
}
feedData__(data);
} else {
preRecordedData_.push(data);
}
};Ogg Opusの圧縮率ですが、AmiVoice APIのマニュアルのガイドラインでは「10分の1程度」となっているため、encoderBitRateに24000を設定し、約10分の1になるようにしています。Ogg Opusは可変ビットレートのため、24000ぴったりになるわけではなく、平均するとだいたいこれくらいの値になるということのようです。
ビットレートは、16bit リニアPCMでサンプリングレートが16000Hzの場合、16000(Hz)×16(bit)=256kbpsになり、24kbpsで約10分の1になります。ちなみにこの「bps」の「b」はバイトではなくビットで、24kbpsは、1秒のデータ量が24キロビットということになります。kB/sのようなバイトの値が欲しい場合は、1バイト=8ビットなので、8で割ります。24kbpsの場合、3kB/sです。
Ogg Opusも非可逆圧縮で音声の劣化があり、音声データを圧縮することで送信するデータのサイズは小さくなりますが、認識率は低下します。そのため、圧縮することを推奨しているわけではありません。
認識率を優先する場合は、無圧縮の16bit リニアPCMや可逆圧縮のFLACをご検討ください。
なお、Ogg Opusのファイルの内容を確認したい場合は、OpusEncoderWrapperのisDebugをtrueにすると、HTMLにOgg Opusのaudio要素が追加されるようになり、確認することができます。
8. ブラウザータブの音声またはシステムの音声の取得
AmiVoice
APIクライアントライブラリのWebSocket音声認識API(Wrp)のrecorder.jsで、getUserMedia()のかわりにmediaDevices.getDisplayMedia()を呼ぶことでブラウザータブの音声やシステムの音声を取得し、音声認識に利用することができます。
注意点は、Microsoft EdgeやGoogle Chromeなどの一部のブラウザーでしかサポートされていないこと、videoもtrueにする必要があること、実行時に表示されるタブなどの選択画面で「音声(オーディオ)の共有」にチェックを入れ、録音の対象を選択する必要があることです。
サンプルでは下記のパラメーター設定を行っています。
navigator.mediaDevices.getDisplayMedia(
{
video: true,
audio: {
audioGainControl: false,
channelCount: 1,
echoCancellation: false,
googAutoGainControl: false,
latency: 0.1,
noiseSuppression: false,
sampleRate: 16000,
sampleSize: 16,
volume: 1,
},
selfBrowserSurface: "include",
}getUserMedia()とgetDisplayMedia()を両方の音声を認識させたい場合は、2つの音声をミックスします。やり方はいろいろありますが、このサンプルでは以下のようにしています。
let audioStream = await navigator.mediaDevices.getUserMedia(
{
audio: {
audioGainControl: false,
channelCount: 1,
echoCancellation: false,
googAutoGainControl: false,
latency: 0.1,
noiseSuppression: true,
sampleRate: 16000,
sampleSize: 16,
volume: 1,
},
video: false
}
);
let displayStream = await navigator.mediaDevices.getDisplayMedia(
{
video: true,
audio: {
audioGainControl: false,
channelCount: 1,
echoCancellation: false,
googAutoGainControl: false,
latency: 0.1,
noiseSuppression: false,
sampleRate: 16000,
sampleSize: 16,
volume: 0.7,
},
selfBrowserSurface: "include",
}
);
// マイク音声とシステム音声のミックス
const audioCtx = new AudioContext({ sampleRate: 16000 });
const dest = audioCtx.createMediaStreamDestination();
let micSource = audioCtx.createMediaStreamSource(audioStream);
let systemSource = audioCtx.createMediaStreamSource(displayStream);
micSource.connect(dest);
systemSource.connect(dest);
let mixedStream = new MediaStream();
mixedStream.addTrack(dest.stream.getTracks()[0]);オプションパラメーターの値については、録音した音声を聞いてよさそうと感じたものを設定しており、主観的なものです。
オプション機能はなるべく無効にしたほうが音質はよさそうです。ただし、環境にもよると思いますが、マイクのノイズがひどかったので、getUserMedia()のnoiseSuppressionはtrueにしました。
ヘッドセットを利用しない環境で回り込みを避けたい場合は、getUserMedia()のechoCancellationはtrueにしたほうがよいかもしれません。
ただし、getUserMedia()のechoCancellationはtrueにすると、Google Chromeで録音デバイスをステレオミキサーにした場合に音声が取れなくなる問題が過去にありました。
selfBrowserSurface: “include”は、getDisplayMedia()の呼び出し元のブラウザータブを録音対象として選択できるようにするためのオプションです。
環境によって最適な設定は異なると思いますので、いろいろ試してみてください。
マイクの音とシステムの音(スピーカーの音)をミックスした場合は、発話が重なった部分の音声は認識率が低下するため、なるべく発話が重ならないようにする必要があります。
マイクの音とシステムの音(スピーカーの音)を音声認識させる方法としては、2つのWebSocketを使ってそれぞれWebSocket音声認識APIを実行する方法も考えられます。この場合、2つの接続の間で時間の同期を取って音声認識が行われるわけではないことに注意してください。認識結果が返ってくる順番が前後する可能性があります。
9. 音声ファイルの情報の取得
BaseAudioContext.decodeAudioData()で音声ファイルのサンプリングレートが取れそうに見えますが、実際に取れるのは、AudioContextのサンプリングレートで音声ファイルのサンプリングレートではありませんでした。
MediaStreamTrackProcessorとAudioDataを使ってHTMLVideoElementのストリームからであればサンプリングレートが取れたのでこれを利用します。
ただし、MediaStreamTrackProcessorとAudioDataは実験的なAPIとなっています。
/**
* 音声ファイルの情報を取得します。
* @param {File} audioFile 音声ファイル
* @returns 音声ファイルの情報
*/
async function getAudioInfo(audioFile) {
const getAudioInfo_ = function (audioFile) {
return new Promise((resolve, reject) => {
if (typeof MediaStreamTrackProcessor !== 'undefined') {
const videoElement = document.createElement("video");
videoElement.width = 0;
videoElement.height = 0;
videoElement.volume = 0.01;
videoElement.autoplay = true;
document.body.appendChild(videoElement);
videoElement.onplay = function () {
videoElement.onplay = null;
const stream = videoElement.captureStream();
const audioTrack = stream.getAudioTracks()[0];
const processor = new MediaStreamTrackProcessor({ track: audioTrack });
const processorReader = processor.readable.getReader();
processorReader.read().then(function (result) {
if (result.done) {
return;
}
videoElement.pause();
videoElement.currentTime = 0;
stream.getAudioTracks().forEach((track) => {
track.stop();
});
try {
processorReader.cancel();
} catch (e) { }
const audioDuration = videoElement.duration;
URL.revokeObjectURL(videoElement.src);
videoElement.src = "";
document.body.removeChild(videoElement);
resolve(
audioFile.type + " "
+ result.value.sampleRate + "Hz "
+ result.value.numberOfChannels + "ch "
+ Math.floor(audioDuration) + "sec"
);
});
};
videoElement.src = URL.createObjectURL(audioFile);
} else {
resolve(null);
}
});
};
return await getAudioInfo_(audioFile);
}なお、Ogg Opusのサンプリングレートは、Ogg OpusのIDヘッダーにある入力サンプリングレートではなく、48000Hzが返ってきます。
AmiVoice APIは、IDヘッダーの入力サンプリングレートでサンプリングレートを判断するため、違いがあることに注意してください。
10. WebVTT形式の字幕ファイルの作成
音声認識の結果からWebVTT形式の字幕ファイルを作成します。
WebVTTは専用のプレイヤーを用意しなくてもブラウザーが対応しています。
読みや時間情報、話者ダイアライゼーションの結果も使用したいため、音声認識結果のJSONのtokens(単語単位の結果)を使って作成することにします。
注意点は下記の通りです。
- 音声認識結果のtextには半角スペースが挿入されており、writtenを連結しても再現できません。
- 自動挿入された句読点には、written以外のキーが存在しない場合があります。
- 日本語エンジンの場合、spokenにはひらがな、カタカナ、「_」、「.」が含まれる可能性があります。ふりがなとして使用する場合は、「_」と「.」の扱いを決めておく必要があります。
- フィラー単語を残す設定の場合、writtenに「%えー%」のような単語の前後が「%」の単語が返ってくるので、writtenを認識結果のテキストとして使用する場合は前後の「%」を除去する必要があります。
- 話者ダイアライゼーションが有効であっても話者ラベルの推定に失敗してラベルがつかない単語がある場合があります。
上記を踏まえて作成したコードが下記になります。
onmessage = (event) => {
let vtt = "";
try {
vtt = jsonToWebVTT(event.data);
} catch (e) {
vtt = "WEBVTT\n";
}
postMessage(vtt);
}
/**
* 簡易的に音声認識結果のJSONをWebVTTに変換をします。
* @param {object} json
* @returns WebVTT
*/
function jsonToWebVTT(json) {
// 動作
// segmentsと句読点で分割してタイムスタンプとスタイルをつけます。(「、」と「。」は削ります。)
// 1つのsegmentを句読点で分割したときに1秒未満になる場合は、分割せずに半角スペースを入れます。
// ただし、前から順にしか見ないので、segmentの末尾は1.2秒未満になる可能性があります。
// ルビタグがあるところとないところがある場合、ないところにタイムタグの表示が反映されなかったため、すべてにルビタグをつけるようにしています。
// 話者ダイアライゼーションで付与されるlabelがある場合、ボイスタグとそのスタイルspeaker0~speaker9のみを出力します。
// 感情解析の結果がある場合、感情解析のみの字幕キューを出力します。
// メモ
// 自動挿入された句読点は、writtenしかない場合、spokenが"_"になっている場合があります。
// 話者ダイアライゼーションが有効でもlabelがつかない単語が存在する場合があります。
const WEBVTT_STYLE = `
STYLE
::cue(v[voice=speaker0]) {
color: #ffffff;
}
STYLE
::cue(v[voice=speaker1]) {
color: #ffd1d1;
}
STYLE
::cue(v[voice=speaker2]) {
color: #cbf266;
}
STYLE
::cue(v[voice=speaker3]) {
color: #b4ebfa;
}
STYLE
::cue(v[voice=speaker4]) {
color: #edc58f;
}
STYLE
::cue(v[voice=speaker5]) {
color: #87e7b0;
}
STYLE
::cue(v[voice=speaker6]) {
color: #c7b2de;
}
STYLE
::cue(v[voice=speaker7]) {
color: #66ccff;
}
STYLE
::cue(v[voice=speaker8]) {
color: #ffff99;
}
STYLE
::cue(v[voice=speaker9]) {
color: #87e7b0;
}
`;
// 字幕キューのスタイル
const CUE_STYLE = " line:0 align:left";
// 感情解析結果の字幕キューのスタイル
const SENTIMENT_CUE_STYLE = " align:right";
// 字幕キューの最短表示時間
const MIN_CUE_DISPLAY_TIME = 1200;
let vtt = "";
let segments = [];
if (typeof json.segments !== 'undefined') {
// 非同期HTTP音声認識APIの音声認識結果の場合
segments = json.segments;
} else if (Array.isArray(json)) {
// WebSocket音声認識APIの音声認識結果を配列にまとめたものの場合
segments = json;
} else {
// 同期HTTP音声認識APIの音声認識結果の場合
segments = [json];
}
let hasLabel = false; // labelがあるかどうか
let id = 1;
for (let segment of segments) {
let tokensByLabel = {};
let lastLabel = "";
// segmentをlabelごとに分類
for (let token of segment.results[0].tokens) {
// writtenは最低限必要
if (typeof token.written !== 'undefined') {
let label = "";
if (typeof token.label !== 'undefined') {
if (!hasLabel) hasLabel = true;
label = token.label;
} else {
// labelがない場合、前の単語と同じlabelであるとみなす。
if (lastLabel.length > 0) {
label = lastLabel;
} else {
label = "nolabel";
}
}
if (typeof tokensByLabel[label] === 'undefined') {
tokensByLabel[label] = [];
}
// 表記の末尾が「?」(全角)で読みの末尾が「_」の場合は、「?」(全角)を後の処理用に別のtokenに分ける。
if (/.+?$/.test(token.written) && typeof token.spoken !== 'undefined' && /.+_$/.test(token.spoken)) {
token.written = token.written.slice(0, -1);
token.spoken = token.spoken.slice(0, -1);
tokensByLabel[label].push(token);
tokensByLabel[label].push({ written: "?" });
} else {
// フィラー単語は表記の前後に「%」があり、この「%」は不要なので削除。
if (/^%.+%$/.test(token.written)) {
token.written = token.written.replace(/^%(.*)%$/, "$1");
}
tokensByLabel[label].push(token);
}
lastLabel = label;
}
}
// labelごとに処理
for (let label in tokensByLabel) {
let startTime = -1;
let endTime = -1;
let cueText = "";
let lastWritten = "";
for (let token of tokensByLabel[label]) {
if (typeof token.endtime !== 'undefined') {
endTime = token.endtime;
}
// 文の区切り文字の場合
// 日本語は、「、」「。」「?」。
// 英語の場合、文の区切りではない記号のときは無視したいため、自動挿入された可能性が高いもの(spokenがない、もしくはspokenが"_")。
if (token.written === "、" || token.written === "。" || token.written === "?"
|| ((typeof token.spoken === 'undefined' || token.spoken === '_') && /^[,.?!]$/.test(token.written))) {
// 次の単語の前にスペースを入れるかどうかの判定用に単語の表記を保存
lastWritten = token.written;
// 先頭でない場合
if (cueText !== "") {
// 削除せずに残す文字の場合
if (/^[,.?!?]$/.test(token.written)) {
cueText += ("<ruby>" + token.written + "</ruby>");
}
// segmentの途中で字幕キューを分けるケース。
if (startTime !== -1 && endTime !== -1 && (endTime - startTime >= MIN_CUE_DISPLAY_TIME)) {
if (cueText.indexOf("<v", 0) === 0) {
cueText = (cueText.trim() + '</v>');
}
vtt += toVttCue(id, startTime, endTime, cueText, CUE_STYLE);
id++;
cueText = "";
startTime = -1;
endTime = -1;
lastWritten = "";
}
} else {
// キューの先頭にある場合は無視
lastWritten = "";
}
} else {
// 句読点以外の場合は、starttimeとendtime必須にする
if (typeof token.starttime !== 'undefined' && typeof token.endtime !== 'undefined') {
// 末尾が数字またはアルファベット、,.?!:;の単語と先頭がアルファベットの単語の間にスペースを入れる
if ((lastWritten.length > 0) && /[a-zA-Z0-9,.?!:;]$/.test(lastWritten) && /^[a-zA-Z]/.test(token.written)) {
cueText += " ";
}
// 次の単語の前にスペースを入れるかどうかの判定用に単語の表記を保存
lastWritten = token.written;
// 字幕キューの開始
if (cueText === "") {
startTime = token.starttime;
if (label !== 'nolabel') {
// ボイスタグ付与
cueText += ("<v " + label + ">");
}
} else {
// タイムスタンプタグ追加
cueText += ('<' + msToVttTimestamp(token.starttime) + '>');
}
let ruby = "";
if (typeof token.spoken !== 'undefined') {
// ルビを整形
ruby = token.spoken.replaceAll(".", "").replaceAll("_", " ").replaceAll(/ {2,}/g, " ").trim();
}
let written = token.written.replaceAll("_", " ").replaceAll(/ {2,}/g, " ").trim();
// 読みがあり、読みと表記が異なっていて、表記がひらがな、カタカナ、「?」、半角スペース以外を含み、数字のみでない場合は、ルビを付与
if ((ruby.length > 0) && (written !== ruby)
&& (written.search(/[^\u3040-\u309f\u30a0-\u30ff? ]/) !== -1)
&& !(/^[0-9]+$/.test(written))) {
cueText += ('<ruby>' + escapeVTT(written) + '<rt>' + escapeVTT(ruby) + '</rt></ruby>');
} else {
// タイムスタンプタグが機能するように読みがない場合もrubyタグで囲む
cueText += ('<ruby>' + escapeVTT(written) + '</ruby>');
}
}
}
}
if (cueText !== "") {
if (cueText.indexOf("<v", 0) === 0) {
cueText = (cueText.trim() + '</v>');
}
if (startTime === -1) {
startTime = 0;
}
vtt += toVttCue(id, startTime, Math.max(endTime, startTime + MIN_CUE_DISPLAY_TIME), cueText, CUE_STYLE);
id++;
}
}
}
// 感情解析の結果
let starttimeTemp = 0;
if (typeof json.sentiment_analysis !== 'undefined') {
if (typeof json.sentiment_analysis.segments !== 'undefined') {
for (let segment of json.sentiment_analysis.segments) {
if (segment.starttime - starttimeTemp > 0) {
// 感情解析結果の隙間を補完
vtt += toVttCue(id, starttimeTemp, segment.starttime, "ENERGY:000 STRESS:000", SENTIMENT_CUE_STYLE);
id++;
}
const cueText = "ENERGY:" + segment.energy.toString().padStart(3, '0')
+ " " + "STRESS:" + segment.stress.toString().padStart(3, '0');
vtt += toVttCue(id, segment.starttime, segment.endtime, cueText, SENTIMENT_CUE_STYLE);
id++;
starttimeTemp = segment.endtime;
}
}
}
if (hasLabel) {
vtt = (WEBVTT_STYLE + vtt);
}
vtt = ("WEBVTT\n" + vtt);
return vtt;
}
/**
* WebVTTの1キューを返します
* @param {number} id
* @param {number} starttime
* @param {number} endtime
* @param {string} text
* @param {string} style
* @returns 文字列
*/
function toVttCue(id, starttime, endtime, text, style) {
return toVttTimestampLine(id, starttime, endtime, style) + text + "\n";
}
/**
* WebVTTのエスケープを行います
* @param {string} value
* @returns 文字列
*/
function escapeVTT(value) {
return value.replaceAll(/ {2,}/g, " ")
.replaceAll("&", "&")
.replaceAll("<", "<")
.replaceAll(">", ">").trim();
}
/**
* WebVTTのタイムスタンプ行を返します
* @param {number} id
* @param {number} starttime
* @param {number} endtime
* @param {string} style
* @returns WebVTTのタイムスタンプ行
*/
function toVttTimestampLine(id, starttime, endtime, style) {
return ("\n" + id + "\n" + msToVttTimestamp(starttime) + " --> " + msToVttTimestamp(endtime) + style + "\n");
}
/**
* 簡易的なmsec→hh:mm:ss.ttt(WebVTTのタイムスタンプ)変換を行います
* @param {number} duration 経過時間ミリ秒
* @returns hh:mm:ss.ttt形式の文字列
*/
function msToVttTimestamp(duration) {
const hour = Math.floor(duration / 3600000);
const minute = Math.floor((duration - 3600000 * hour) / 60000);
const hh = hour.toString().padStart(2, '0');
const mm = minute.toString().padStart(2, '0');
const ms = (duration % 60000).toString().padStart(5, '0');
return hh + ":" + mm + ":" + ms.slice(0, 2) + "." + ms.slice(2, 5);
}基本的な挙動は下記のとおりです。
- 発話区間、もしくは句読点で字幕のキューを分けます。
- 分けた結果、字幕のキューの表示時間が1.2秒未満になる場合は、分けずに半角スペースを挿入します。
- ひらがな、カタカナ、「?」以外を含み、数字のみで構成されていない単語の場合は、「読み」をつけます。
- 「表記」の「_」は、半角スペースの代替文字のため、半角スペースに置換します。
- 句読点「。」と「、」は字幕ファイルに出力しません。
- 話者ダイアライゼーションの結果のlabelは、WebVTTのボイスタグで出力します。
- 字幕のキューの2つ目以降の単語は、単語のstarttimeをタイムタグで出力します。
- 感情解析の結果は、音声認識の結果とは別に字幕のキューを出力します。ただし出力するのは、Stress、Energyのみです。
- 音声認識結果表示用の字幕のキューにスタイルを設定します。(左上)
- ボイスタグにスタイル(文字の色)を設定します。ただしspeaker0~speaker9までです。
- 上記をWebVTTサンプル1として正規表現による文字列の削除、置換処理を行ったサンプル2~4も作成します。
- WebVTTサンプル2: 表記と読みのみ。WebVTTサンプル3: 表記のみ。WebVTTサンプル4: 読みがあるところは表記のかわりに読みを表示し、読みの前後には半角スペースを挿入。
- WebVTTサンプル1~4は、Video要素のオプションで切り換えることができます。
以上です。最後まで読んでいただき、ありがとうございます。
この記事を書いた人
-
AmiVoice APIインフラチームメンバーD
駆け出しインフラエンジニア。猫派。
プログラマーからインフラエンジニアにクラスチェンジ。
「Webページ編」と「Chrome拡張機能編」を書きました。
よく見られている記事



新着記事
-
音声認識が生成AIに与える影響とは?品質評価の新基準

-
AmiVoice APIを安全に使おう!APIキー発行&接続元IPアドレス制限実践ガイド

-
音声認識API「AmiVoice API」を使ってみよう

カテゴリ一覧
アーカイブ
