音声認識に必要なサンプリングレートはどのくらいか?

 安藤章悟
安藤章悟
みなさま こんにちは。
今日は、音声認識に必要なサンプリングレート(サンプリング周波数)のお話をします。
音声認識におけるサンプリングレートのよくある誤解として「サンプリングレートが高ければ高いほど高音質になるので音声認識率も高くなる」というものがあります。ですが、実は多くの音声認識エンジンではサンプリングレートは16kHzが最適であることが多いです。
今回はなぜ多くの音声認識エンジンで16kHzが最適なのか?について解説します。
サンプリングレートとは何か?
サンプリングレートは、音声をデータにする時に、1秒間を何個の点に分割するか、という値のことです。例えば16kHzの場合は1秒間を16000個の点にしてデータ化するということになります。
ちなみに、下記は16kHzでサンプリングした音声波形の例です*1。横軸が時間・縦軸が音の大きさを表現しています。数えてみると0.0000秒~0.0010秒(1/1000秒)の間に16個の点があり、つまり1秒間では16000個の点があることになります。
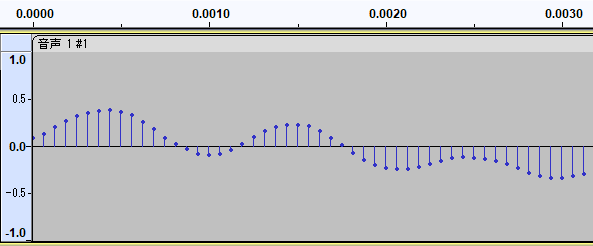
サンプリングレートは通常は高くなるほど詳細にデータを表現できるのでより高音質になります。音楽CDだと44.1kHzです。ハイレゾと呼ばれる高音質の音源だと96kHz~192kHzくらいのものが主流のようです。
なぜ多くの音声認識エンジンで16kHzが最適なサンプリングレートなのか?
サンプリングレートは高ければ高いほど高音質になりますが、ある一定以上サンプリングレートを高くしても音声認識率は上がらなくなります。
サンプリングレートがより高くなると、音の高さが高い音も録音することが可能になるのですが、人間の発声による音の高さには限界があるので、そこまで高いサンプリングレートは必要としないからです。
いくつか実例で見てみましょう。こちらの画像は私が「いつも大変お世話になっております」と発話した音声です*2。横軸が時間・縦軸が音の高さという表示方法でスペクトログラムと呼ばれるものです*3。いわゆる声紋です。
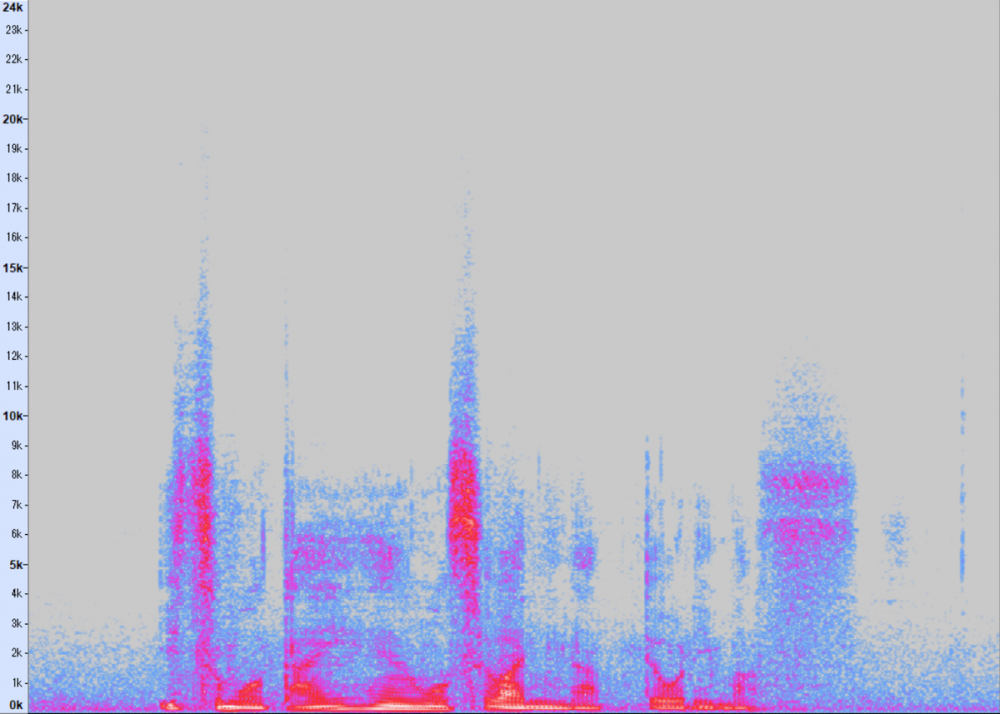
全体的に画像の下のほうに紫や赤の色が多く見えますが、これは「この音声には比較的低い高さの音が多く含まれている」ということを意味します。
画像の左・中央・右にそれぞれ縦の帯状の部分がありますが、これは「いつも」の「つ」の部分、お世話にの「せ」の部分、「おります」の「す」の部分です。これらの音は摩擦音や破擦音と言って比較的高い音になりやすいものですが、それでもサンプリングレート16kHzあれば音声認識に必要な情報はほぼ記録できるものです。
もう1つ例を見てみましょう。こちらは、ソニー・ミュージックソリューションズが運営する mora という音楽配信サイトの中にある、無料ダウンロードコンテンツのページ(※現在こちらのページは存在しません 2024.3)から選んだ、VOICES tilt-six Remix feat. Miku Hatsuneという楽曲の一部をスペクトログラムで表示したものです。
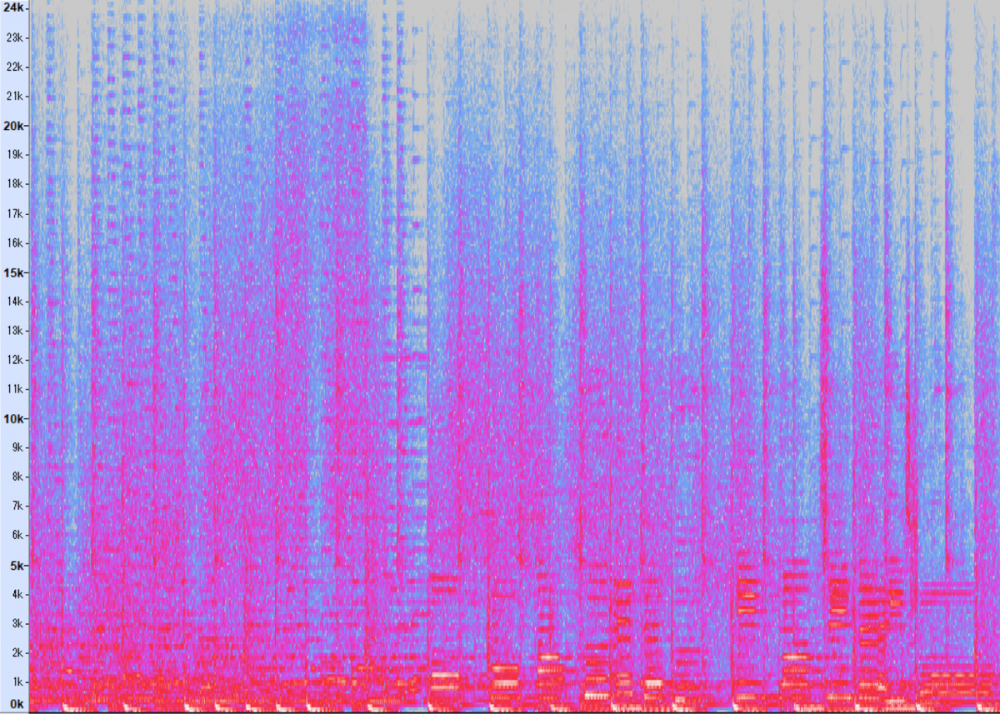
先程の私の声と違って、この画像からは低い音から高い音まで万遍なく含まれていることが分かります。人の音声を録音する時はそんなに高い音は入っていないのでサンプリングレート16kHzで十分なのですが、こういう楽器の音などを含む楽曲ではもっと高いサンプリングレートが必要になるため、例えばCDでは44.1kHzなど高いサンプリングレートを採用しているわけです。こちらのmoraの音声はハイレゾで96kHzです。*4
音楽を聞くためには44.1kHzやそれ以上のサンプリングレートが求められることがありますが、音声認識ではそこまでの高音質は必要なく、16kHzあれば十分ということになります。
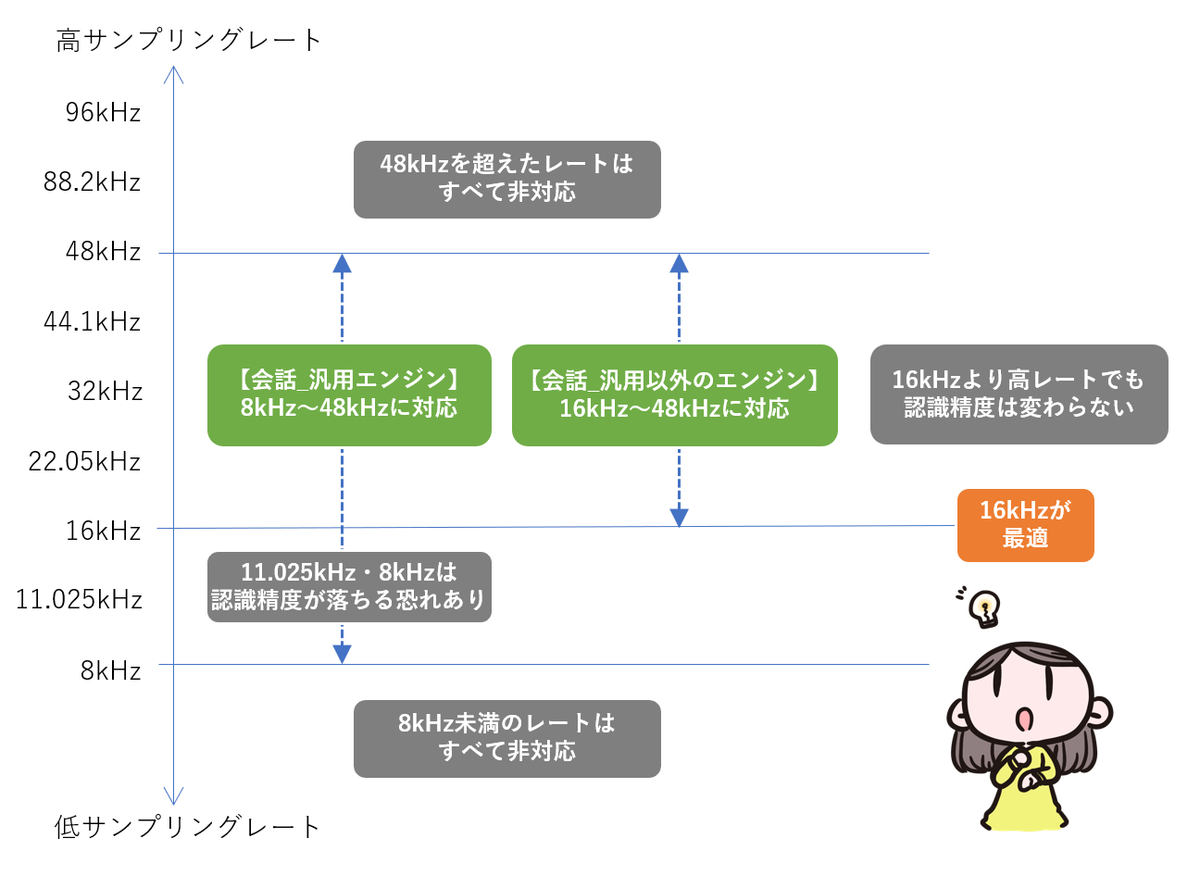
AmiVoice APIのサンプリングレート対応状況
AmiVoice API でのサンプリングレートの対応をまとめました。
- サンプリングレートは16kHzが最適です
- 16kHzより高いサンプリングレートでも音声認識精度は変わりません。
- 会話_汎用エンジンでは 8kHz~48kHzの音声に、それ以外のエンジンは16kHz~48kHzの音声に対応しています。
- ただし、会話_汎用エンジンに8kHz・11.025kHzの音声を入力した場合、16kHzの音声に比べて認識精度が低下する可能性があります。
- 48kHzを超えたサンプリングレート、および8kHz未満のサンプリングレートは非対応です。
図にまとめると以下のようになります。
AmiVoice APIに16kHzより高いサンプリングレートの音声を入力するとどうなるか?
もしも、AmiVoice APIにサンプリングレートが16kHzより高い音を入力するとどうなるかというと、内部でサンプリングレート16kHz相当の音質に変換(ダウンサンプリング)されて音声認識処理がされます。つまり16kHzより高い音を入れてもあまり意味が無いということになります。
16kHzより高いサンプリングレートの音声を入力しても動作上特に問題はありませんが、通信データ量が増えるなどの弊害もありますので可能ならばちょうど16kHzのサンプリングレートの音声を使用するのがよいでしょう。
AmiVoice APIに16kHz未満のサンプリングレートの音声を入力するとどうなるか?
サンプリングレート16kHz未満の音は音声認識に必要な情報が不足することがあり、音声認識精度が低下する可能性があるため、基本的には非対応となっています。ただし、電話回線を通じた会話音声など、どうしても高い音質で音声を送信できないケースも考慮し「会話_汎用」エンジンでは8kHz音声対応の音声認識エンジンも用意しております(入力された音声のサンプリングレートに応じて自動的に選択されます)。
ただし、16kHzの音声を入力した場合と比べると認識率が低下する可能性があるので、可能ならは16kHz以上の音声を送るべきでしょう。
音声のアップサンプリングについて
8kHzや11.025kHzで録音された音声データを、16kHzなどより高いサンプリングレートにする「アップサンプリング」という手法があります。ですが、アップサンプリングをしても元の音声に無い音が生まれるわけではないので、音質は改善しません。
むしろ「会話_汎用」エンジン使用時には、本来8kHz対応の音声認識エンジンで処理されるべきものが16kHz対応の音声認識エンジンで処理されてしまうことになり、逆に音声認識精度が低下する恐れもあります。
音声認識においてはアップサンプリングは基本的に無意味ですので、ご注意ください。
まとめ
今回は音声認識する際に必要なサンプリングレートについての説明と、AmiVoice APIでのサンプリングレートの対応について解説しました。
繰り返しになりますが、AmiVoice APIでの要点は以下のようになります
- サンプリングレートを16kHzに設定可能な場合はできるだけ16kHzにしたほうがよいです。
- 16kHzより高くても音声認識精度への影響はありません。
- 16kHzを下回ると非対応、もしくは音声認識精度が低下する可能性があります。
この記事を書いた人
*1:録音や波形表示はAudacity ( https://www.audacityteam.org/ ) というオープンソースのツールを使用しました
*2:こちらの録音やスペクトログラムの表示もAudacity ( https://www.audacityteam.org/ ) というオープンソースのツールを使用しました
*3:ちなみに画像では縦軸の最大値は24kHzになっていますが、この高さの音を収録しようとした場合、サンプリングレートは倍の48kHz以上が必要になります。今回詳しい説明は省きますが興味のあるかたは「ナイキスト周波数」などで調べるといいでしょう。
*4:サンプリングレート96kHzだとスペクトログラムの上限は48kHzになるのですが、画像では見やすくするために24kHz付近までに拡大して表示しています
よく見られている記事



新着記事
-
AmiVoice APIアップデート解説 End-to-End対応の「単語強調」機能

-
動画に字幕を簡単合成!音声認識APIで作る字幕ワークフロー

-
AmiVoiceの単語登録APIで音声認識をもっと自由に!

カテゴリ一覧
アーカイブ
