AmiVoice Cloud Platformの認識結果に表示される「confidence(信頼度)」とは?

 大倉尭
大倉尭
皆さん、こんにちは!
AmiVoice Cloud Platform(ACP)で音声認識を行うと、認識結果は以下のようなJSON形式で返却されます。よく見ると、「written(表記)」や「spoken(読み)」の他にもいくつかの情報が出力されていますね。
{
“results”: [
{
“tokens”: [
{
“written”: “アドバンスト・メディア”,
“confidence”: 1,
“starttime”: 570,
“endtime”: 1578,
“spoken”: “あどばんすとめでぃあ”
},
{
“written”: “は”,
“confidence”: 1,
“starttime”: 1578,
“endtime”: 1850,
“spoken”: “は”
},
{
“written”: “、”,
“confidence”: 0.94,
“starttime”: 1850,
“endtime”: 2026,
“spoken”: “_”
},(中略)
{
“written”: “めざ”,
“confidence”: 0.94,
“starttime”: 7722,
“endtime”: 7962,
“spoken”: “めざ”
},
{
“written”: “します”,
“confidence”: 0.94,
“starttime”: 7962,
“endtime”: 8490,
“spoken”: “します”
},
{
“written”: “。”,
“confidence”: 0.85,
“starttime”: 8490,
“endtime”: 8778,
“spoken”: “_”
}
],
“confidence”: 0.999,
“starttime”: 250,
“endtime”: 8778,
“tags”: [],
“rulename”: “”,
“text”: “アドバンスト・メディアは、人と機械との自然なコミュニケーションを実現し、豊かな未来を創造していくことをめざします。”
}
],
“utteranceid”: “20211130/17/017d6ffb057f0a301cca94c9_20211130_173421”,
“text”: “アドバンスト・メディアは、人と機械との自然なコミュニケーションを実現し、豊かな未来を創造していくことをめざします。”,
“code”: “”,
“message”: “”
}
この中で利用者の皆さまから多くお問い合わせをいただくのが、「confidence(信頼度)って何?」という点です。ACPのサイトでは、以下のリンクに説明があります。
confidence 信頼度(0~1の値。 0:信頼度低, 1:信頼度高)
もちろんこの通りなのですが、この記事ではAmiVoiceにおける「confidence(信頼度)」について、もう少し詳しく解説したいと思います。
※信頼度の具体的な計算方法は社外秘となります。ご了承ください。
音声認識結果の「信頼度が高い・低い」とはどういうことか?
音声認識の処理では、入力された音声から出力されるテキストの候補を推測し、その中で最も確率が高いと判断したものを認識結果として出力しています。すなわち、音声認識システムの内部には、「認識結果以外の候補の情報」が含まれているということになります。
例えば、「天気」という認識結果が出力されたとしましょう。その場合、「認識結果以外の候補」としては、同じ音である「転機」、似たような音である「電気」「元気」などがあり、これらが候補として音声認識システムの内部で検討されます。
この検討の中で、例えば「音は『げんき』に近いけど、前後の文脈からすると『天気』かな…?」というように、音声認識システムも判断に迷うことがあります。このような場合、「ひとまず認識結果として『天気』を出したが自信がない」ということで、信頼度は低くなります。
一方、「音も『てんき』だし、前後の文脈を見ても『天気』で間違いない」と音声認識システムが判断すれば、自信を持って「『天気』だ!」と言えるので、信頼度は高くなります。ただし、音声認識システム自体は音声からテキストを予測しているだけで、正解のテキストを知っているわけではありません。人間が自信満々で間違えることもあるのと同じで、信頼度が高いからといってその認識結果が正しいとは限りません。その点はご注意ください。
なお、認識結果の信頼度が全体的に低い場合は、発話が曖昧・ノイズが大きいといった要因の可能性もあります。音声認識率が低い時の対策と同じですが、はっきり喋ったり、発話の環境を確認したりするとよいかもしれません。
信頼度には2種類ある
AmiVoiceにおける信頼度は、「単語単位」と「発話単位」の2種類があります。それぞれについて簡単に説明します。
①単語単位の信頼度
認識結果の単語ごとに出力される信頼度です。冒頭の出力例では、赤字のconfidenceが該当します。
②発話単位の信頼度
発話全体に対する信頼度です。冒頭の出力例では、最後の紫字のconfidenceが該当します。計算方法が異なるので、単語単位の信頼度とは独立の値です。
次節で詳しく説明しますが、発話単位の信頼度は、主にコマンド入力(数単語程度の音声認識)でコマンドを実行するかどうかの判断に使うことを想定したものになっており、長い文章などを音声認識させる際の利用には向いていません。発話単位の信頼度は「発話全体」を対象に計算される信頼度であり、無音区間や「あのー」「えーっと」といったフィラーの部分が計算に含まれ、信頼度の値に影響を与える可能性があるためです。
長い文章を音声認識させる場合など、無音区間やフィラーが入りやすい状況では、単語単位の信頼度を使用し、その平均を「発話全体の信頼度」とした方がよいかもしれません。
信頼度の活用方法
この「信頼度」ですが、音声認識結果を利用する上でどのような活用方法があるのでしょうか。AmiVoiceの製品で使われている事例も含めて紹介します。
①認識誤りの可能性が高い単語を目立たせる
単語単位の信頼度の活用例です。信頼度が一定値以下の単語の文字の色や大きさを変えることで、認識誤りの可能性が高い単語を目立たせることができます。
具体的な使用例としては、弊社が医療分野向けに提供しているAmiVoice Ex7における、認識誤りの可能性が高い単語を赤く表示する機能があります。この判定には、単語単位の信頼度が使用されています。
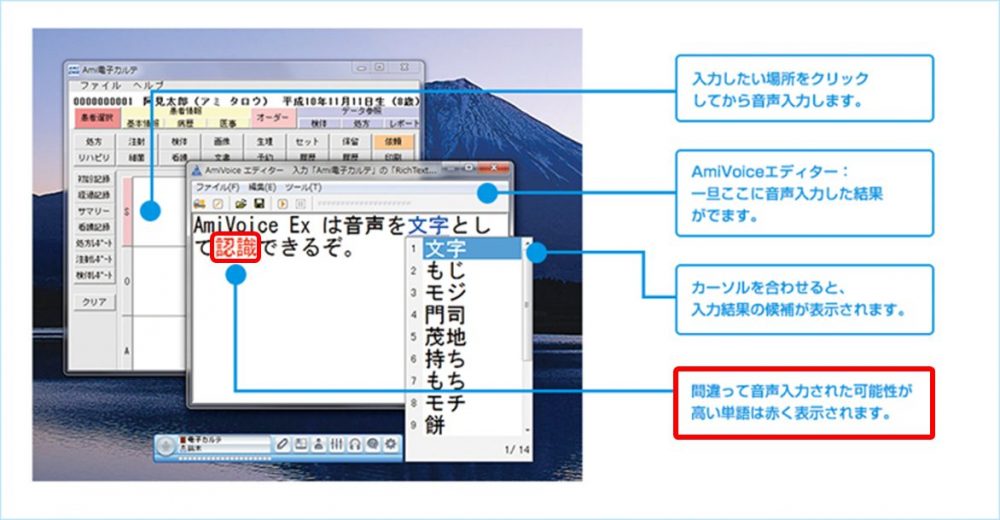
認識誤りの可能性が高い単語を目立たせることにより、後で認識結果を修正する場合に役立ちます。また、その部分をもう一度話してもらうようアプリケーション側で促す、といった活用法もあるかと思います。
②コマンド入力などでの活用
発話単位の信頼度の活用例としては、コマンド入力のように、特定の発話のみ音声認識する場合が挙げられます。スマートスピーカーのような使い方をイメージしてもらえると分かりやすいと思います。
コマンド入力の場合、何も発話していないのに、周囲の雑音に反応してコマンドが勝手に実行されてしまっては困ります。このような場合に、認識結果の発話信頼度が一定値以上でないとコマンドが実行されないようにすることで、誤作動を抑制することができます。
ただし、この境界値の設定には注意が必要です。境界値を高くすると誤作動のリスクは下がりますが、正しい発話を取りこぼしてコマンドが実行されない可能性が上がります。境界値を低くした場合はこの逆で、正しい発話の取りこぼしは少なくなりますが、誤作動のリスクが上がります。「正しい発話の取りこぼしやすさ」と「誤作動のリスク」はトレードオフの関係にあり、これは境界値の設定で決まる、ということになります。
なお、2022年4月時点では開発中ですが、ACPでこのようなコマンド入力などを簡単に行えるモード・プランのリリースを予定しています。今後のリリースにご期待ください!
おわりに
今回の記事では、ACPの認識結果に表示される「confidence(信頼度)」について説明しました。信頼度は「認識結果」と「認識結果以外の候補の情報」を使って計算しています。認識結果そのものと合わせて、信頼度の値も活用していただけると幸いです。
もしこの記事を見て音声認識技術やAmiVoice Cloud Platformに興味を持った開発者の方がいましたら、ぜひ https://acp.amivoice.com/ を試してみてください。毎月音声60分までは全エンジン無料で使えます。
ここまでお読みいただき、ありがとうございました!
この記事を書いた人
-
大倉尭
新卒でアドバンスト・メディアに入社。
現在の仕事は音声認識の精度向上のための研究開発がメインです。
趣味は旅行(主に鉄道)・読書(主に小説)・ボードゲームなど。
よく見られている記事



新着記事
-
AmiVoice API アップデート解説 ボイスボット向け新パラメータで応答待ち時間を短縮

-
AmiVoice APIアップデート解説 End-to-End対応の「単語強調」機能

-
動画に字幕を簡単合成!音声認識APIで作る字幕ワークフロー

カテゴリ一覧
アーカイブ
