【HttpClient】C#でAmiVoiceの話者ダイアライゼーションを利用する方法

 林政樹
林政樹
こんにちは。林です。
株式会社アドバンスト・メディアにて、iOS/iPadOS/WatchOSアプリの開発を担当しています。
はじめに
今年2月、弊社のAmiVocie Cloud Platform(以下、ACP)の非同期HTTP音声認識APIにおいて、話者ダイアライゼーションという機能が無料オプションとして追加されました。話者ダイアライゼーションとは、複数人が話している音声に対して、話者ごとに発話区間を推定する機能のことを言います。詳しくは下記にて紹介しておりますので、良ければご覧ください。
AmiVoice Cloud Platform-Tech Blog
そこで今回は、
「C#でAmiVoiceの話者ダイアライゼーションを利用する方法」
というテーマで、非同期APIの話者ダイアライゼーションをC#で実装する方法をご紹介いたします。
良ければご一読お願いします。
また記事作成にあたって、図1のような話者ダイアライゼーションを利用できる簡単なWindowsアプリ(APPENDIX: アプリの使い方)を開発してみました。こちらからダウンロードできます。ご興味ある方はお試しください。
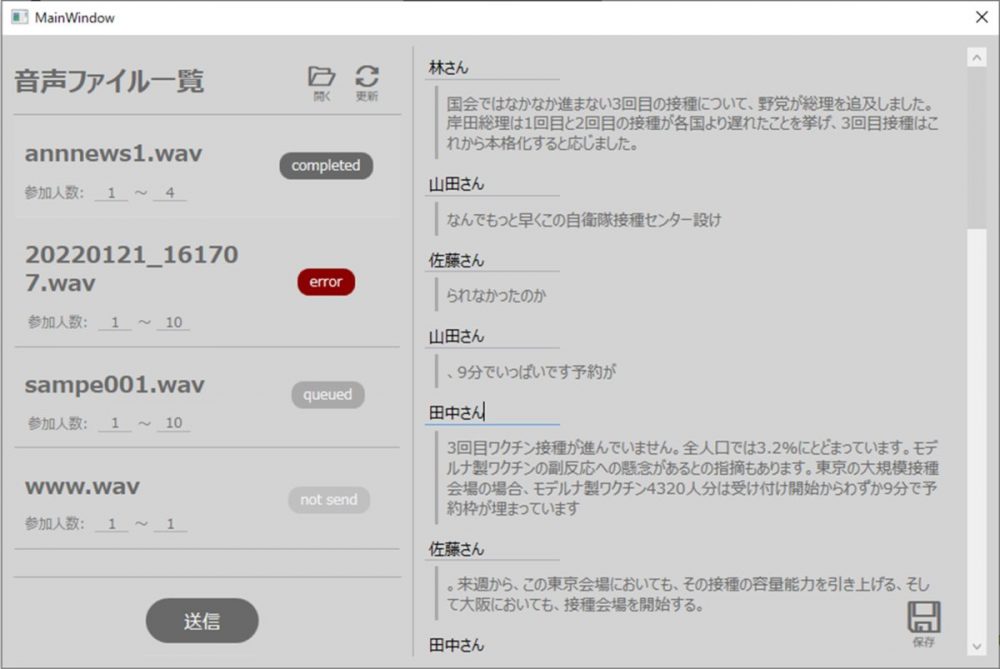
開発したWindowsOSアプリ
話者ダイアライゼーションの実装
○開発環境
- Windows 10 Pro
- Visual Studio 2019
- .NET 5.0
○ソースコード
○実装
「はじめに」でご紹介した通り、非同期APIの話者ダイアライゼーションをC#で実装する方法についてご紹介していきます。
※非同期APIとアプリケーションの基本的な連携に関しては、下記にてご紹介していますので、割愛させていただきます。
AmiVoice Cloud Platform-Tech Blog
また本記事では、HTTP通信を実現するために、System.Net.Http内のHttpClientクラスを利用します。
HttpClientを利用するにあたっての注意点として、
HttpClientは 1 回インスタンス化され、アプリケーションのライフ ライフを通して再使用することを意図しています。 要求ごとに HttpClient クラスをインスタンス化すると、負荷の高い状態で使用可能なソケットの数が使い果たされます。
( Microsoft Docs – HttpClientより )
とあるため、下記のように、利用するクラス内で静的にインスタンス化します。
public class AmiHTTP
{
// -> HttpClientのインスタンス化
private static HttpClient _client = new(); // 枯渇対策
}
では上記記事と同様に、
①音声認識のリクエスト(POST)
②ジョブの状態を取得(GET)
という流れでご紹介していきます。
①音声認識のリクエスト(POST)
まず音声認識ジョブをPOSTする部分を実装します。
話者ダイアライゼーションを利用するには、リクエストのdパラメータ内で、下の表のspeakerDiarization=Trueを追加する必要があります。
| パラメータ | 型 | デフォルト | 説明 |
|---|---|---|---|
| speakerDiarization | boolean | False | 話者ダイアライゼーションの有効無効の指定 |
| diarizationMinSpeaker | int | 1 | 最小推定話者人数 |
| diarizationMaxSpeaker | int | 10 | 最大推定話者人数 |
そのため、リクエストのイメージとしては下記の通りになります。(赤文字部分の追加)
POST https://acp-api-async.amivoice.com/v1/recognitions Content-Type: multipart/form-data;boundary=some-boundary-string-- some-boundary-stringsome-boundary-string Content-Disposition: form-data; name="u" (自分のAPPKEY ) -- some-boundary-string Content-Disposition: form-data; name="d" grammarFileNames=-a-general speakerDiarization=True diarizationMinSpeaker=1 diarizationMaxSpeaker=10 -- 音声データ Content-Disposition: form-data; name="a" Content-Type: application/octet-stream ( some-boundary-string ) -- --
上記リクエストのイメージを考慮して、音声認識のリクエスト(POST)は、RequestSpeechRecog(string filePath, string appKey, Action<AmiHTTPResult> action)として実装します。
public class AmiHTTP
{
// -> const
private const string urlPath = "https://acp-api-async.amivoice.com/v1/recognitions";
private static readonly Encoding encoding = Encoding.UTF8;
private static HttpClient _client = new(); // 枯渇対策
public class AmiHTTPResult
{
public string success = null;
public string error = null;
}
// -> POST (音声認識のリクエスト)
public static async Task RequestSpeechRecog(string filePath, string appKey, Action<AmiHTTPResult> action)
{
using MultipartFormDataContent content = new();
// -> u
content.Add(new StringContent(appKey, encoding), "\"u\"");
// -> d
string dvalue = "grammarFileNames=" + Uri.EscapeDataString("-a-general");
dvalue += " speakerDiarization=" + Uri.EscapeDataString("True");
dvalue += " diarizationMinSpeaker=" + Uri.EscapeDataString("1");
dvalue += " diarizationMaxSpeaker=" + Uri.EscapeDataString("10");
content.Add(new StringContent(dvalue, encoding), "\"d\"");
// -> a
using FileStream fs = new(filePath, FileMode.Open, FileAccess.Read);
StreamContent streamContent = new(fs);
streamContent.Headers.ContentDisposition = new ContentDispositionHeaderValue("form-data")
{
Name = "\"a\"",
};
streamContent.Headers.ContentType = new MediaTypeHeaderValue("application/octet-stream");
content.Add(streamContent);
HttpRequestMessage request = new(HttpMethod.Post, urlPath);
request.Content = content;
await DoRequest(request, action);
}
// -> Request
private static async Task DoRequest(HttpRequestMessage request, Action<AmiHTTPResult> action)
{
HttpStatusCode statusCoode = HttpStatusCode.NotFound;
string bodyStr;
AmiHTTPResult result = new();
try
{
HttpResponseMessage response = await _client.SendAsync(request);
bodyStr = await response.Content.ReadAsStringAsync();
statusCoode = response.StatusCode;
}
catch (HttpRequestException e)
{
Debug.WriteLine("e: " + e.Message);
result.error = "ERROR: " + e.Message;
action(result);
return;
}
if (!statusCoode.Equals(HttpStatusCode.OK))
{
result.error = "ERROR: StatusCode = " + statusCoode;
action(result);
return;
}
if (string.IsNullOrEmpty(bodyStr))
{
result.error = "ERROR: Response body is empty";
action(result);
return;
}
result.success = bodyStr;
action(result);
}
}
実際の使い方としては、下記の通りです。
// -> 音声認識のリクエスト 第一引数には音声ファイルのパス
_ = AmiHTTP.RequestSpeechRecog("./sample.wav", "自分のAPPKEY", (result) =>
{
if (result.error != null) {
// -> エラーがあった場合
return;
}
// -> 音声認識のリクエストに成功した場合
// -> result.successをjsonに変換し、sessionidを保持する
});
RequestSpeechRecog(string filePath, string appKey, Action<AmiHTTPResult> action)の第一引数に音声ファイルのパスを、第二引数に自分のAPPKEYを代入して利用します。
②ジョブの状態を取得(GET)
次に音声認識ジョブの状態をGETで取得するには、GetJobState(string session_id, string appKey, Action<AmiHTTPResult> action)を実装します。
public class AmiHTTP
{
.
.
.
// -> GET (ジョブの取得)
public static async Task GetJobState(string session_id, string appKey, Action<AmiHTTPResult> action)
{
string path_ = urlPath + "/" + session_id;
HttpRequestMessage request = new(HttpMethod.Get, path_);
request.Headers.Add("Authorization","Bearer " + appKey);
await DoRequest(request, action);
}
}
実際の使い方としては下記の通りで、第一引数に特定の音声ファイルと紐ついたsessionidを、第二引数に自分のAPPKEYを代入して利用します。
// -> 音声認識ジョブの状態を取得
_ = AmiHTTP.GetJobState("特定のsessionid", "自分のAPPKEY", (result) =>
{
if (result.error != null) {
// -> エラーがあった場合
return;
}
// -> 取得したjson内のstatusが"completed"の時に認識結果を取得できる
});
ここで話者ダイアライゼーションの場合、取得できる”results”内には、下記のようにlabelキー(黄色線)が追加されています。(推定話者ごとにspeaker0, speaker1, …とラベル分けされます)
"segments": [
{
"results": [
{
"confidence":0.999,
"endtime":16400,
"rulename":"",
"starttime":0,
"tags":[],
"text":"国会では...",
"tokens":[
{
"confidence":1,
"endtime":736,
"label":"speaker0",
"spoken":"こっかい",
"starttime":272,
"written":"国会"
},
{
"confidence":1,
"endtime":1120,
"label":"speaker0",
"spoken":"では",
"starttime":736,
"written":"では"
},
...
]
},
}
以上より、非同期APIの話者ダイアライゼーションをC#で実装する方法の紹介を終わります。話者ダイアライゼーションはdパラメータにspeakerDiarization=Trueを指定するだけで利用できるようになります。簡単に実装できますので、ぜひお試しください。
APPENDIX: アプリの使い方
これからご紹介するWindowsアプリは、
「複数音声ファイルから話者が分離された状態の音声認識結果」
を取得することができるアプリです。
こちらからダウンロードできますので、ぜひ使ってみてください。
操作の主な流れとしては、
①設定ファイルにAPPKEYを記載
②音声ファイルの話者数を設定し、送信
③認識結果の話者名を変更し、テキストファイルに保存
となっております。
下記詳しくご紹介していきます。
①設定ファイルにAPPKEYを記載
まずアプリを使用する前に、exeファイル直下のappSettings.jsonを開き、自分のAPPKEYを”appKey”キーの値に記載してください。
{
"appKey" : "ABCD...", // 自分のAPPKEY
"grammarFileNames" : "-a-general" // ポーリング間隔 [sec] ※その他は下記の通りです。
“grammarFileNames” => 契約中の接続エンジン名
“pollingTime” => 音声認識ジョブの状態をACPに問い合わせる頻度
②音声ファイルの話者数を設定し、送信
設定ファイルでAPPKEYを記載した後に、SpeakerDiarizationSampleApp.exeを起動します。
起動後は、「開く」ボタンから任意の数の音声ファイルを選択します。選択した音声ファイルはアプリ左側のリストに表示されます。
その際に、各々の音声ファイル内で登場する話者の数を設定します(3人であれば参加人数:3~3, 4人から6人であれば参加人数:4~6)。
話者の数を設定後、「送信」ボタン押下で、ACPに音声ファイルを送信します。
※一連の操作は図2のようになります。
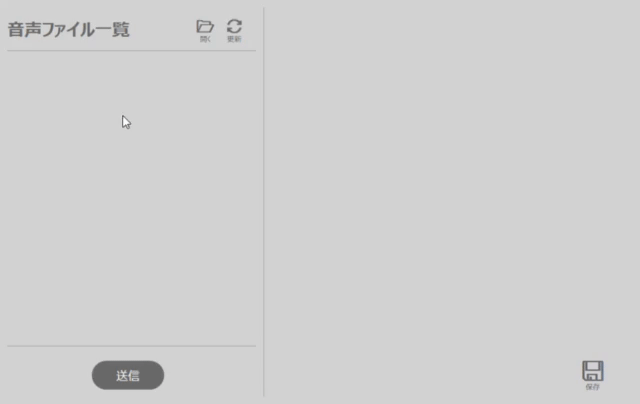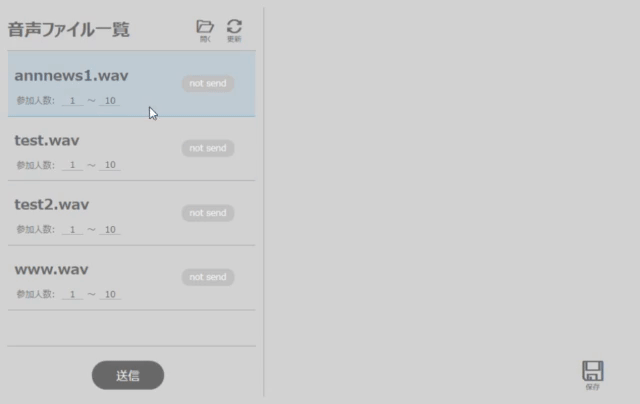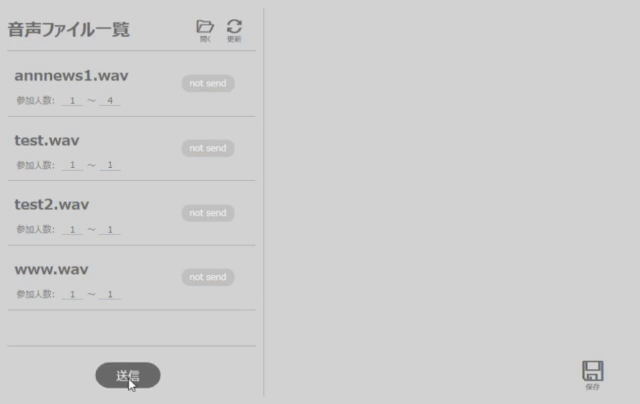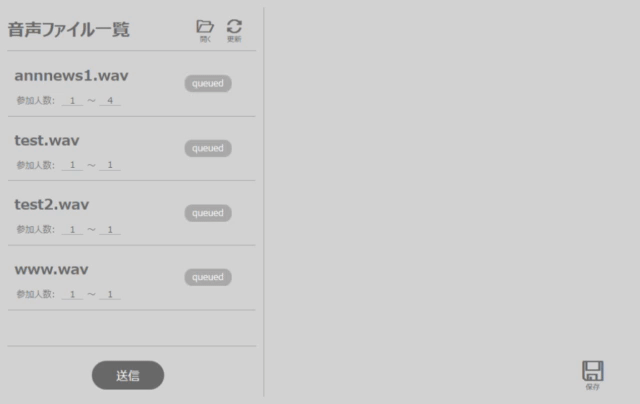
音声ファイルの選択から送信までの操作例
③認識結果の話者名を変更し、テキストファイルに保存
ACPで音声認識が完了すると、特定の項目が”completed”状態に遷移します。その項目を選択すると、アプリ右側に、話者が分離(speaker0, speaker1, …)されている認識結果が表示されます。
もしここで、話者の名前を変更したい場合は、図3のように変更可能です。(※speaker0の話者名を山田さんに変更した場合は、全てのspeaker0が山田さんに変更されます。)
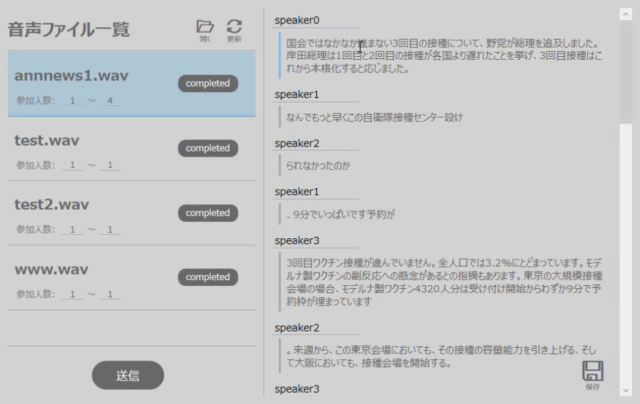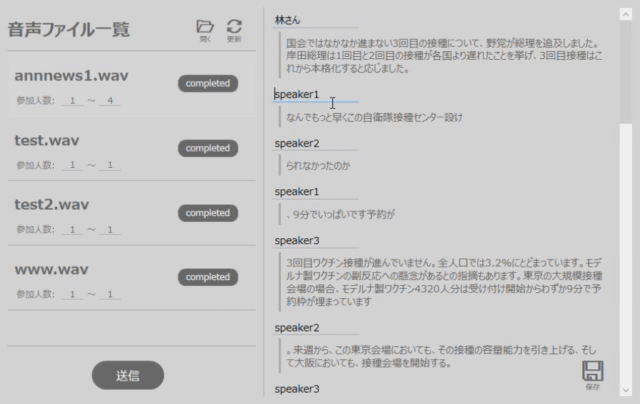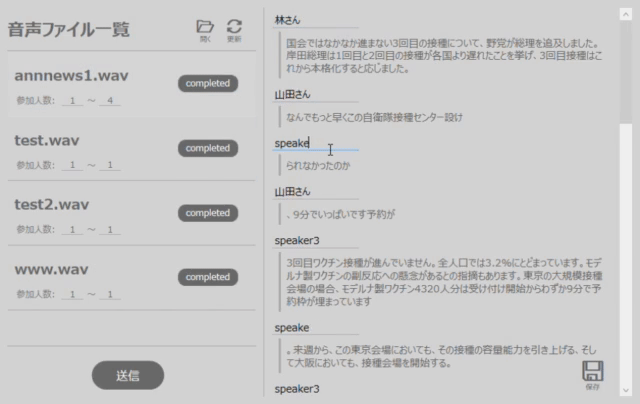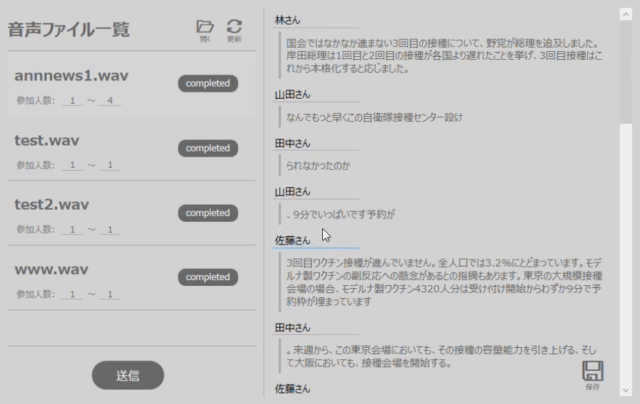
図3 話者の名前を変更する際の操作例
またこの際、認識したテキストも修正可能です。
全ての修正が終わりましたら、「保存」ボタンを押下して、テキストファイル(図4)として任意の場所に保存します。
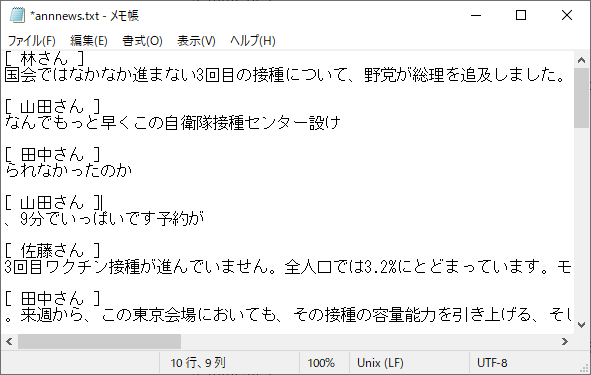
図4 保存されるテキストファイル
以上でアプリの使い方は終了です。話者ダイアライゼーションをアプリでどう表現できるかの一例となれば幸いです。
こちらから自由にダウンロードできます。ぜひ使ってみてください。
何かありましたらコメントいただけると幸いです。
おわりに
今回は、非同期HTTP音声認識APIの新たな機能である話者ダイアライゼーションをC#で実装してみました。様々なシーンで利用可能であると想定されます。実装方法も簡単ですので、ぜひ皆さんもお試しください。
参考
AmiVoice Cloud Platform関連
マニュアル Archive – AmiVoice Cloud Platform
HttpClient関連
HttpClient Class – Microsoft Docs
Multipart Form Post in C# – Brian Grinstead
HttpClient でファイルアップロード – WebSurfer’s Home
【C#】System.Net.Http.HttpClientを使ってWeb APIとHTTP通信してみよう – Rのつく財団入り口
【C#】HttpClientを使ってみる(POST) – HUSKING – kotteri
この記事を書いた人
-
林政樹
Swift/Objective-Cで、iOS/iPadOS/WatchOSアプリの開発をしています。
よく見られている記事



新着記事
-
音声認識が生成AIに与える影響とは?品質評価の新基準

-
AmiVoice APIを安全に使おう!APIキー発行&接続元IPアドレス制限実践ガイド

-
音声認識API「AmiVoice API」を使ってみよう

カテゴリ一覧
アーカイブ
