【初心者向け】Perlを駆使して音声認識APIを使ってみた

 ひしばゆり
ひしばゆり
はじめまして、ひしばゆりと申します。
株式会社アドバンスト・メディア(以下AMI)所属の「超初心者」エンジニアです。AMI入社時はアルバイトで、未経験からのスタートでした。
今回はそんなわたしが、初心者でも弊社の音声認識API「AmiVoice Cloud Platform(以下ACP)」のサービスを使えるのか挑戦してみます!
そして、音声認識やプログラミングに興味はあれど、難しそうなので挑戦したことがないという方にも、「自分もちょっとチャレンジしてみようかな」と思っていただけるよう、初心者向けに様々な情報をこれでもかと噛み砕いて書いていこうと思います。
はじめに
- プログラミング言語はPerlを使用します。
- 今回のコードはWindows10でのみ動作確認をしています。
- 2021年3月現在のACPの公開情報やサンプルプログラムを使った説明です。
- 記事内で「ディレクトリ」という単語が出てきます。もし耳慣れない言葉だなと思ったら、この記事では一般的な「フォルダ」と同じ意味の単語だと思ってください。
まずはACPのオススメポイントをご紹介
ACP は AmiVoice Cloud Platformの略です。アドバンスト・メディアの音声認識APIで、従量課金制のクラウドサービスです。
★様々な魅力がありますが、ひしば的オススメポイントはここ★
- プログラムを書くことで、音声をテキストに変換する様々なアプリケーションが自分で開発できる
- 課金対象は、認識させる『音声の長さ』ではなくノイズや無音部分を省いた『発話部分』のみで、1秒単位で計算してくれる
- シーンや利用用途にあわせて13種類の音声認識エンジン(普通の会話向け・医療向け・金融向けなど)を選べる
- 単語登録もできる
- ログあり(データが保存され品質向上に利用される)と、ログなし(データが保存されない)が選べて安心
- 「会話_汎用」エンジンの場合で、ログありは0.0275 円 / 秒(税込)、ログなしは0.044 円 / 秒(税込)とリーズナブル
- 「会話_汎用」「英語_汎用」「中国語_汎用」は、それぞれ毎月60分無料
- マニュアル内にチュートリアル・サンプルプログラム完備で分かり易い
このサービス内容と価格で弊社の高い精度の音声認識を使用できるのは、とてもお得なのでは?と思います。
今回はcurlというコマンドを使用してACPを試します
後ほど書きますが、ACPは様々なプログラミング言語に対応していて、多様な形で利用することができます。
その中でも初心者でも気軽にACPを試せる方法として先輩たちにお勧めされたのが、「curl」というコマンドを使用する方法でした。
★ざっくり解説★
curlとは、コマンド(PCに出す命令文)のひとつで、通信を使ってサーバーやAPIなどとデータの送受信ができるものです。
普段インターネットでWebサイトを見たりするときに使用しているhttpも通信規格のひとつですが、curlはその他にも様々な通信規格に適応していて使いやすいものです。また、非常にシンプルなコマンドで扱えるので比較的簡単に使用できます。
お持ちのPCにインストールする必要がある場合もありますが、Windows10では何もしなくても元から入っています。
ちなみにこの時点でもし、そもそもサーバーとかAPIとかよくわかんない、聞いたことない(!?)と思ったとしても、今回は大丈夫です。「curlというものを使うらしい」くらいの理解でもいいので、安心してこのまま進んでみてください。
次はACPを使用するのに必要そうな情報を知ろう
利用には登録が必要です。初めての利用登録の流れはこちらの記事にありますので、ぜひご参照ください。
AmiVoice Cloud Platform-Tech Blog
では、マニュアル内のチュートリアルから、とりあえずこれさえ知っておけば試せそうな情報を拾ってみます。
ACPには、音声認識を行う方式が、以下の2種類あります。
1.HTTP音声認識API(非ストリーミング )
- とても簡単
- curlが使用できるのはこちらで、他にも、C++、C#、java、JavaScript、PHP、Pythonと様々なプログラミング言語での使用ができる
- すでに録音済みの音声ファイルがある場合にのみ使える
- 1回でアップロードした音声データに含まれるすべての発話の認識処理が終了するまで、認識結果を受け取ることができない
- 受付可能な音声データの最大容量:16MB よってサイズの小さい短い音声ファイルを簡単に認識させたいケース向き
2.WebSocket音声認識API (ストリーミング)
- HTTPに比べると、ちょっと難しく感じる方もいるかも
- こちらの方式ではcurlは使用できないので、C++、C#、java、JavaScript、PHP、Pythonのいずれかを使用する
- すでに録音済みの音声はもちろん、リアルタイムに録音しながらでも、どんどん投げれて、認識結果もどんどん受け取れる
1と2に共通すること
- ACPの利用にはマイページ⇒接続情報で確認できるAppKeyが必要
- 非音声区間による強制切断時間:50秒ということで、最初に無音とかノイズとかが長く続くと強制切断されちゃうので、注意が必要です
- 認識結果は、JSONというフォーマットで返却される
- 注意点として16kHz未満(8kHz/11kHz)のサンプリングレートの音声データを受け付けて認識可能なエンジンは、現時点(2021年3月)では日本語の「会話_汎用」エンジン(-a-general)のみなので、それ以外の音声認識エンジンを指定して認識させたい場合は16kHz以上のフォーマットの音声データで送信する必要がある。
※音声ファイルにはサンプリングレートというものがあり、1秒間に何回記録するかを表すものです(サンプルレート・サンプリング周波数などとも呼ばれます)。例えば16kHzは1秒間に16000回記録をしていて、この数が多ければ多いほど、滑らかな音になり音質が良くなったと感じることができます。
※詳細はこちらのページに記載がありますので、詳しく知りたい方はご確認ください。
他にも情報が丁寧かつたくさん書かれていますが、このぐらいの理解でも使えるのか、試しに先に進んでみます。
ACPサンプルプログラムに挑戦
マニュアル内のサンプルプログラムを試しにダウンロードします。
ダウンロードした『sample_1.1.5』というディレクトリの中の、『Hrp』というディレクトリの中に、『curl』の名を持つディレクトリがあります。中にはファイルが2つありますが、使用するのは『run.bat』というファイル。バッチファイルなどと呼ばれるもので、ダブルクリックすると予め設定されている命令を実行してくれるという便利なファイルです。
ダブルクリックすると下記のような黒い画面が立ち上がります。Windowsに入っている〔コマンドプロンプト〕という名前のアプリケーションです。PCにキーボードでコマンド(命令)を打って、送るための画面です。
※PCの設定によっては「WindowsによってPCが保護されました」というポップアップが立ち上がるかもしれませんが、これに関しては詳細表示→実行を押して大丈夫です。
「Please enter AppKey:」と書いてあるので、ここにACPのマイページ⇒接続情報で確認できる自分専用のAppKeyをコピペしてエンタ―キーを押下します。
すると今度はぶわーと数字やアルファベットが大量に表示されます。
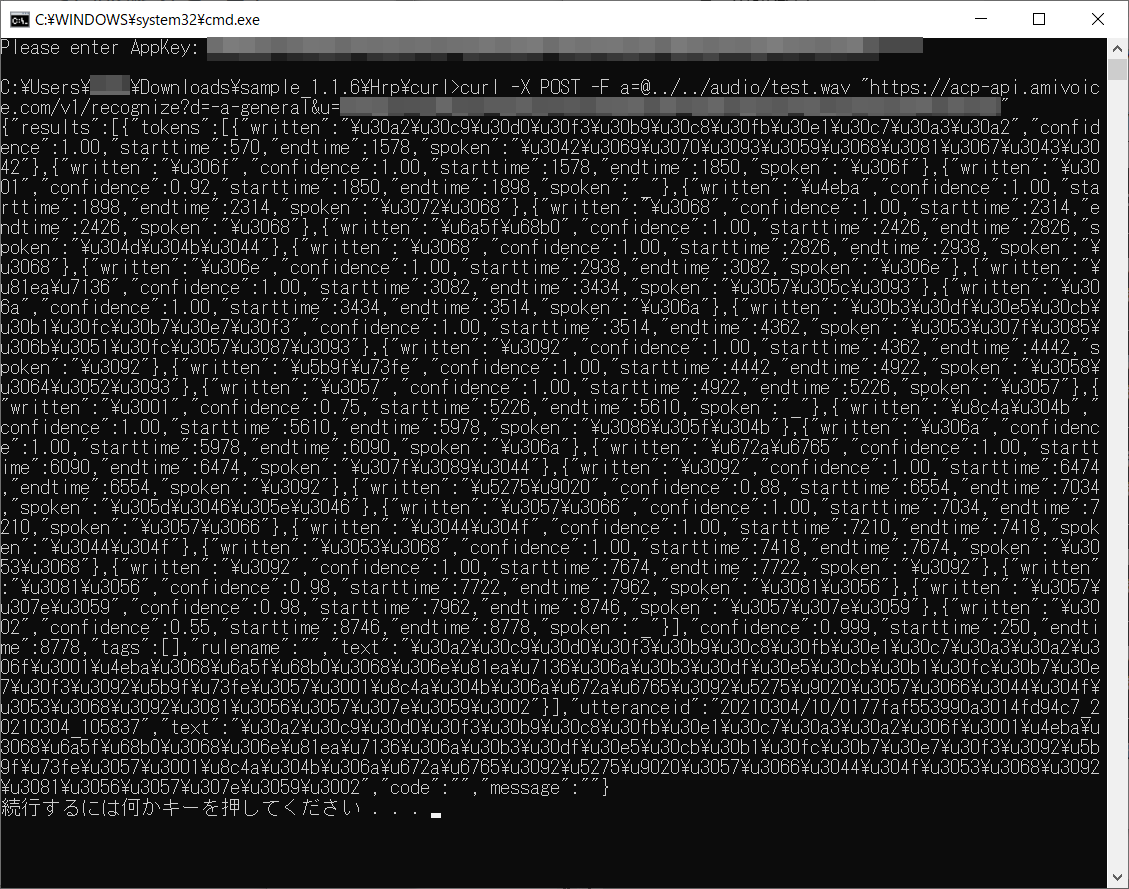
※「続行するには何かキーを押してください…」と表示されますが、押すと画面が終了するので、ちょっと待ってね。
これが、「JSON形式で書かれた、認識結果」です。
JSON形式で書かれたものを読める形に変換するには様々な方法がありますが、今回はただ結果を見たいだけなので、以下のページを使います。
『jq』というJSON形式を読みやすく整形してくれるツールのお試しページです。
上記のページの左側に先ほどのコマンドプロンプトに表示された結果をコピペしたら以下が表示されました。
“results”: [
{
“tokens”: [
{
“written”: “アドバンスト・メディア”,
“confidence”: 1,
“starttime”: 570,
“endtime”: 1578,
“spoken”: “あどばんすとめでぃあ”
},
{
“written”: “は”,
“confidence”: 1,
“starttime”: 1578,
“endtime”: 1850,
“spoken”: “は”
},
{
“written”: “、”,
“confidence”: 0.97,
“starttime”: 1850,
“endtime”: 2010,
“spoken”: “_”
},
{
“written”: “人”,
“confidence”: 1,
“starttime”: 2010,
“endtime”: 2314,
“spoken”: “ひと”
},
{
“written”: “と”,
“confidence”: 1,
“starttime”: 2314,
“endtime”: 2426,
“spoken”: “と”
},
{
“written”: “機械”,
“confidence”: 1,
“starttime”: 2426,
“endtime”: 2826,
“spoken”: “きかい”
},
{
“written”: “と”,
“confidence”: 0.93,
“starttime”: 2826,
“endtime”: 2938,
“spoken”: “と”
},
{
“written”: “の”,
“confidence”: 1,
“starttime”: 2938,
“endtime”: 3082,
“spoken”: “の”
},
{
“written”: “自然”,
“confidence”: 1,
“starttime”: 3082,
“endtime”: 3434,
“spoken”: “しぜん”
},
{
“written”: “な”,
“confidence”: 1,
“starttime”: 3434,
“endtime”: 3514,
“spoken”: “な”
},
{
“written”: “コミュニケーション”,
“confidence”: 1,
“starttime”: 3514,
“endtime”: 4362,
“spoken”: “こみゅにけーしょん”
},
{
“written”: “を”,
“confidence”: 1,
“starttime”: 4362,
“endtime”: 4442,
“spoken”: “を”
},
{
“written”: “実現”,
“confidence”: 1,
“starttime”: 4442,
“endtime”: 4922,
“spoken”: “じつげん”
},
{
“written”: “し”,
“confidence”: 1,
“starttime”: 4922,
“endtime”: 5242,
“spoken”: “し”
},
{
“written”: “、”,
“confidence”: 0.98,
“starttime”: 5242,
“endtime”: 5626,
“spoken”: “_”
},
{
“written”: “豊か”,
“confidence”: 1,
“starttime”: 5626,
“endtime”: 5978,
“spoken”: “ゆたか”
},
{
“written”: “な”,
“confidence”: 1,
“starttime”: 5978,
“endtime”: 6090,
“spoken”: “な”
},
{
“written”: “未来”,
“confidence”: 1,
“starttime”: 6090,
“endtime”: 6490,
“spoken”: “みらい”
},
{
“written”: “を”,
“confidence”: 1,
“starttime”: 6490,
“endtime”: 6554,
“spoken”: “を”
},
{
“written”: “創造”,
“confidence”: 0.88,
“starttime”: 6554,
“endtime”: 7034,
“spoken”: “そうぞう”
},
{
“written”: “して”,
“confidence”: 1,
“starttime”: 7034,
“endtime”: 7210,
“spoken”: “して”
},
{
“written”: “いく”,
“confidence”: 1,
“starttime”: 7210,
“endtime”: 7402,
“spoken”: “いく”
},
{
“written”: “こと”,
“confidence”: 0.97,
“starttime”: 7402,
“endtime”: 7674,
“spoken”: “こと”
},
{
“written”: “を”,
“confidence”: 1,
“starttime”: 7674,
“endtime”: 7706,
“spoken”: “を”
},
{
“written”: “めざ”,
“confidence”: 0.96,
“starttime”: 7706,
“endtime”: 7962,
“spoken”: “めざ”
},
{
“written”: “します”,
“confidence”: 0.96,
“starttime”: 7962,
“endtime”: 8506,
“spoken”: “します”
},
{
“written”: “。”,
“confidence”: 0.84,
“starttime”: 8506,
“endtime”: 8778,
“spoken”: “_”
}
],
“confidence”: 1,
“starttime”: 250,
“endtime”: 8778,
“tags”: [],
“rulename”: “”,
“text”: “アドバンスト・メディアは、人と機械との自然なコミュニケーションを実現し、豊かな未来を創造していくことをめざします。”
}
],
“utteranceid”: “20201222/11/0176883ceb6f0a30116494c1_20201222_111742”,
“text”: “アドバンスト・メディアは、人と機械との自然なコミュニケーションを実現し、豊かな未来を創造していくことをめざします。”,
“code”: “”,
“message”: “”
}
これなら何が書いてあるかわかります。このバッチファイルでは最初にダウンロードした『sample_1.1.5』というディレクトリの中の、『audio』というディレクトリの中の、『test.wav』という音声ファイルをサーバーに投げて、結果を受け取っています。
返ってくるJSONの中身ですが、主なものとしては下記のようなことが書いてあります。
- “written” :音声認識結果の単語の表記
- “confidence” :この単語の信頼度(0~1の間の値で、数値が高いほど信頼度が高い)
- “starttime” :この単語の開始時間(音声データの先頭の時間を0として)
- “endtime” :この単語の終了時間(音声データの先頭の時間を0として)
- “spoken” :この単語の読み(ひらがな)
※詳細はこちらのページに記載がありますので、詳しく知りたい方はご確認ください。
上記のような細かい情報の後に、最後のほうに音声の発話内容と同様の「”アドバンスト・メディアは、人と機械との自然なコミュニケーションを実現し、豊かな未来を創造していくことをめざします。”」という結果が書かれています。
サンプルプログラムをまずは使ってACPに触れてみようというだけなら、驚くほど簡単に動かすことはできました。ダウンロードして、ダブルクリックして、 AppKeyコピペして、エンターキー押しただけです。すごい。
でも、なにも音声認識の知識がない人が気軽にやったとしたら、ちょっと返ってくる情報量が多くて尻込みしちゃうかも…とも思いました。ということで、今度はわたしが唯一自力で書けるプログラミング言語Perlと、先程手に入れたcurlのサンプルプログラムを組み合わせて、シンプルな認識結果文のみ吐き出してくれるものをちょっと作ってみようと思います。
Perlを使用したことない方向けのご案内
★用意してほしいもの★
- テキストエディタをダウンロードする。
コードなどを書いたり表示したりするのに使います。ぶっちゃけメモ帳とかでも表示はできますが、なにかと機能が限られてくるので、使い勝手のよいものを探しましょう。サクラエディタなどが無料で、簡単だと思われます。
- Perlをインストールする
Perlにはいくつか種類があるのですが、わたしは初期に教わったままActivePerlを使用しています。
ここでは詳しい説明は割愛しますが、なにかをネット上からダウンロード&インストールしたことがあれば特に難しいことはないと思うので、がんばってみてください。「Perl ダウンロード」などでネット検索すると、ダウンロードやインストール方法を説明したいろんな方のページも見つかります。


★その他ちょっとだけ基礎情報を補足★
- 先程登場した、コマンドプロンプトで「perl -v」(perlと-vの間は半角スペース)と打って、バージョン情報的なものが表示されれば使えます。
- テキストエディタで書いたPerlスクリプトは拡張子[.pl]で保存します。
- Perlスクリプトの中で文頭に「#」をつけて記述いるのは説明書きなど、スクリプトとしては無効にしたい部分です。
ここまで理解したら、難しいことはあまり考えずLet’s Go!
最初は「#」のついている説明書きを読みながら、意味はわからずとも写し書きをしてみるだけでも十分です◎
PerlでACPを使うプログラムを書いてみた
今回はPerlで「ACPに複数の音声ファイルを一つずつ投げて結果を受け取り、認識結果文だけを取り出して一つのテキストファイルにまとめる」という内容のプログラムに挑戦してみました。
プログラムの中でも少し説明書きを書いていますが、詳細な説明は後述します。音声ファイルはどなたでも聞けるようにサンプルプログラムに同梱されていた、<test.wav>、<test2.wav>、<www.wav>の三つを使用します。
#1. #!c/perl64からuse Encode;はおまじない #!c/perl64 # perlのパス use strict; # エラーを教えてくれるおまじない use warnings; # use strictより詳細な警告をしてくれるおまじない use utf8; # 文字コードをutf8に設定 use JSON; # JSONデータを解析することができるようになるおまじない use Encode; # 日本語などマルチバイト文字をあつかえるようになるおまじない # 使用方法の記載→コマンドプロンプトにperl acptest.plと入力するとこのスクリプトが動く #perl acptest.pl #2. コマンドプロンプトに「"」と「"」の間の文字や文章を表示する print "Please enter your AppKey: "; #2. コマンドプロンプトに使用者が直接AppKeyを入力する<STDIN>という方式で入力されたAppKeyを$AppKeyという箱(スカラー変数)に格納する my $AppKey = <STDIN>; #2. chomp関数で$AppKey末尾の改行を削除 chomp($AppKey); #3. 音声ファイルの格納されたディレクトリ名の宣言 my $dir = 'audio'; #3. 結果を入れる箱(配列)の名前の宣言 my @result = (); #4.『audio』ディレクトリを開く、開けなかったらエラーを出してねという命令 opendir (my $audio, $dir) or die("error :$!"); #5. while文でaudioディレクトリ内の音声ファイルを一つずつを読み込んで$audio_fileという箱(スカラー変数)に格納して{…}内の処理を繰り返す while (my $audio_file = readdir $audio) { #6. audioディレクトリの中身として、カレントディレクトリを表す「.」と一つ上の階層のディレクトリを表す「..」が含まれてしまうので飛ばす処理 next if ($audio_file eq '.' || $audio_file eq '..'); #7. ユーザーの入力したAppKeyを使用して読み込んだ音声ファイルをACPに投げる my $return = `curl -X POST -F a=@"audio/$audio_file" "https://acp-api.amivoice.com/v1/recognize?d=-a-general&u=$AppKey"`; #8. ACPから返ってきたJSONをPerlのデータ構造として扱えるようにする my $data = decode_json($return); #9. 受け取った結果はハッシュという箱に入っているので、その中から認識結果textのみを取り出して@resultという箱(配列)に格納する push @result, $data->{'text'}; #10. audioディレクトリの中身のファイルをすべて処理し終わるまで、ここまでの{…}内を繰り返す } #11. 結果を出力するためのresult.txtというテキストファイルを作成して開く、開けなかったらエラーを出してねという命令 open(OUT, "> result.txt") or die("error :$!"); #12. 結果を格納した@resultから一つずつ結果を取り出し$outという箱に格納して{…}内の処理を繰り返す foreach my $out (@result) { #13. result.txtに認識結果テキストを文字コードUTF-8に変換して出力、末尾に改行を2つつける print OUT encode('UTF-8', $out), "\n\n"; #14. 全部出力し終わるまで{…}内を繰り返す } #15. 出力したファイルを閉じる close(OUT); #終わり
さっぱりわからない人向けに、ざっくり解説。
★使用方法★
- 任意の名前のディレクトリを作成
- 1.のディレクトリの中に『audio』というディレクトリを作成、認識したい音声ファイルを格納
- 同じく1.のディレクトリの中にテキストエディタで上記のスクリプトをコピペしたファイルを作成、<acptest.pl>という名前でを文字コードUTF-8にして保存
- コマンドプロンプトでcd [acptest.plのパス]と入力し、<acptest.pl>を格納しているディレクトリまで移動
- 『audio』と<acptest.pl>を格納しているディレクトリに移動をしたら、コマンドプロンプトに「perl acptest.pl」と入力、エンターキーを押下すると、<acptest.pl>が動きます
※「cd」というのは「チェンジディレクトリ」といって、「cd半角スペース」の後に打ったディレクトリに移動をするコマンドです。
(例)デスクトップに『test』というディレクトリ名で作成し、『audio』と<acptest.pl>を格納した場合、cd”C:\Users\ユーザー名\Desktop\test”と入力します。
※パスは指定したいディレクトリを選択した状態で、Shiftキー+右クリックを押下すると、パスのコピーというメニューが選べてコピーできます。
★ちょこちょこ出てくる「パス」とはなにか、ざっくり解説★
上記にも下記にもちょこちょこ「パス」という言葉が出てきます。この「パス」とは道などの意味を持つ英単語で、ITの分野では、コンピュータ内での所在を表す文字列のことです。主にディレクトリやファイルの在り処を示す時に使用します。
例えば”C:\Users\ユーザー名\Desktop\test\acptest.pl”でいうと、PCのCドライブの中の『Users』というディレクトリの中の『ユーザー名』というディレクトリの中の『Desktop』というディレクトリの中の『test』の中の<acptest.pl>というファイルの所在を示している記述になります。
★スクリプトの解説★
- 冒頭の#!c/perl64からuse Encode;までの6行はエラー表示や警告をしてもらったり、このスクリプトを動かしたりするのに必要な設定をするおまじないです。
#!c/perl64はperlのパス(在り処)で、先程紹介したActivePerlでは書かなくても動くのですが、一般的なperlのスクリプトではperlの在り処を示すパスの記載が必要なので書いておく癖がついていたほうがベターです。 - print “Please enter your AppKey: “;からchomp($AppKey);まででコマンドプロンプト上に「Please enter your AppKey:」と表示して、ユーザーにAppKeyの入力を求め、入力されたAppKeyの末尾の改行を削除して、使用しやすい形にしています。
- my $dir = ‘audio’;とmy @result = ();などは宣言といいます。
「処理対象のものを入れる箱を作って名前決めた」というようなイメージで「=」以降のものを格納します。「()」というのは中身が空という意味。
箱には種類があり、下記のようなイメージです。
・$…はスカラー変数。1つしかものを入れられない箱。他のものをいれると上書きされる。
・@…は配列。入れた順に番号をつけて順番に並べながら複数の物を入れれる箱。
・%…はハッシュ。配列同様複数の物を入れれる箱だが、番号ではなく名前つきの鍵(Key)のラベルが付いていて、配列のように順番には並んでいない。
そのためハッシュから中身(value)を取り出す際は、順番が毎回ランダムになってしまうので、鍵の名前で並べ替えたり名指しで指定したりしないと、毎回同じ順番で取り出したり、任意の一つを取り出すことができない。 - opendir (my $audio, $dir) or die(“error:$!”);で音声ファイルの格納されたディレクトリを開いています。なにかディレクトリやファイルを開く際は、開けなかった場合エラー表示をしてもらうよう命令します。
- while (my $audio_file = readdir $audio) {…}
ここからwhile文という書き方で音声を一つずつだとか、テキストファイルを一行ずつ読み込んで、それぞれに同じ処理{…}を繰り返していっています。繰り返しの処理はwhile文の他にも「for」文や「foreach文」などがあり、行いたい処理などによって使い分けます。 - next if ($audio_file eq ‘.’ || $audio_file eq ‘..’);
もし読み込んだ$audio_fileが「.」「..」だったら以下の処理は飛ばして次のファイルを読み込んでねという命令です。audioディレクトリの中身として、カレントディレクトリを表す「.」と一つ上の階層のディレクトリを表す「..」が含まれてしまうので、それは飛ばしてもらうために書いています。 - my $return = `curl -X POST -F a=@”audio/$audio_file” “https://acp-api.amivoice.com/v1/recognize?d=-a-general&u=$AppKey“`;
バッククォート演算子と呼ばれる「`」と「`」の間で挟む方法でcurlを呼び出し、実行してACPを叩いています。基本はサンプルプログラム「run.bat」から、そのままコピペして、”音声ファイルの在り処”とユーザーから入力された$AppKeyを使えるように直したcurlコマンドを「`」で挟んでいます。「`」で挟むことで外部コマンド(今回で言えばcurl)を実行できます。curlの部分は下記の情報が含まれています。
・my $return = →後述のcurlでACPに音声ファイルを投げて返ってきた結果を$returnに格納する。
・`curl -X POST -F a=@”音声ファイルの在り処”→curlを呼び出して-X POSTでその後記述するファイルを、更にその後記述するACPにアップロードする。
・”https://acp-api.amivoice.com/v1/recognize→ACPログ保存ありの設定。(ログ保存なしはhttps://acp-api.amivoice.com/v1/nolog/recognize)
・-a-general→接続エンジン名の設定(-a-generalは会話_汎用エンジン)。
・$AppKey→ユーザーが入力したAppKey。
・その他aやdやuなどは必須のリクエストパラメータ。※リクエストパラメーターに関しては詳細を書くと長くなりそうなので、ここでは割愛して、そのまま使ってねという形にしますが、ちゃんと知りたい場合は下記のページをご確認ください。
- my $data = decode_json($return);でACPから返ってきたJSONをPerlのデータ構造として扱えるようデコード(変換)して、$dataという箱に格納しています。
- push @result, $data->{‘text’};
$dataを出力しても、まだこの状態ではハッシュの箱に入っていて、その箱がどこにあるかというアドレスしか書いてもらえないので、push関数で、$dataの中から{‘text’}というラベルの付いた箱だけを取り出し、中身を@resultという箱に順番に格納していきます。 - while文の{…}の中の繰り返し処理はここまで。
- open(OUT, “> result.txt”) or die(“error:$!”);で結果を出力する用のresult.txtという名前のテキストファイルを作成して開いています。ディレクトリの時と同様開けなかった時はエラー表示してくれるよう命令。
- foreach my $out (@result) {…}で@resultの箱の中身(各音声ファイルの認識結果テキスト)を一つずつ取り出して$outという箱に入れて{…}内の処理をしています。ここでは先程のwhile文同様、繰り返し処理をするためのforeach文を使用しています。
- {print OUT encode(‘UTF-8’, $out), “\n\n”;}
foreach文の中の{print OUT encode(‘UTF-8’,$out),”\n\n”;}で先程$outに格納した各音声ファイルの認識結果テキストをUTF-8の文字コードに変換してresult.txtに出力、見やすいように末尾に\n(改行)を二つ加えています。 - すべての認識結果テキストを出力し終わるまで{…}内の⑬を繰り返します。
- close(OUT);でresult.txtを閉じます。
◆コマンドプロンプト上でスクリプトの実行が終わったら、『acptest.pl』を格納したディレクトリを開いて、『result.txt』というファイルができていていれば成功です。認識結果のテキストが出力されています。
おわりに
ここまで読んでいただき、本当にありがとうございます。
過去何度もわたし自身が「分からないことを調べると説明に他の分からない言葉が出てきて、自分にはまだ早いのかと尻込みしてしまう。」ということがよくあったので、この記事を読む方にはそうなって欲しくないという気持ちでこの記事を書かせていただきました。未経験の状態からだと、今回の内容でも説明が足りていないかもしれませんが、少しでも「わからないなりに挑戦してみたら案外こわくないのかも」と思っていただけたら幸いです。
このブログを書くにあたって、初歩的なところから何度も質問を受けてくださったN先輩、O先輩、T先輩ありがとうございました!
この記事を書いた人
-
ひしばゆり
未経験でアルバイトとしてAMIに入社。今は正社員として先輩のアシスタント的な立ち位置でデータ整備などを主にやっています。日々勉強中の身。
よく見られている記事



新着記事
-
音声認識が生成AIに与える影響とは?品質評価の新基準

-
AmiVoice APIを安全に使おう!APIキー発行&接続元IPアドレス制限実践ガイド

-
音声認識API「AmiVoice API」を使ってみよう

カテゴリ一覧
アーカイブ
