音声認識を使ったシステム開発の前提条件<後編>ー開発ノウハウシリーズ2ー

みなさま、こんにちは。
音声認識システムの開発者視点から音声認識導入前に知っておくと役に立つ知識について解説している本連載。今回は「音声認識の前提条件 後編」です。
本記事は、過去にウェビナーにてお話した内容を記事にしたものです。
以下より動画でもご覧いただけます。
▶【動画】【開発者向け】 これだけは押さえたい!音声認識導入で失敗しないシステム開発のノウハウ(1) ー要件定義とUI・UX編ー
音声認識の前提条件 後編
1.どんなシーンで音声認識するか
前回音声認識のメリット・デメリットや音声認識をしたい内容に難易度があること、音声認識エンジンのカバー範囲について解説しました。後半は音声認識しやすいシーンや話し方から解説していきます。
はじめに難易度が低いものから紹介します。
まず、キーボードの代わりに音声で操作をする「口述筆記」「音声コマンド」です。
身近なものだと、スマホの音声入力(OKGoogle、ヘイsiriなど)が当てはまります。文字入⼒や操作が目的のため、もし誤動作や誤認識しても、ユーザーの方で認識しやすく話し直すので、比較的音声認識の難易度は低くなります。
次に難易度レベル中のシーンとして、「音声対話システム」があげられます。
人が機械に話しかける際に、自然と聞き取りやすい話し方をするユーザーが多いので音声認識の難易度は低い傾向にあります。ただ最近は技術の進化で、音声対話システムが人間のようにスムーズな会話を実現させることで、ユーザー側も少し砕けた話し方になってシステムが聞き取りにくくなり、音声認識の難易度が上がってしまっています。
そしてもっとも高い難易度のシーンは、「会話(会議や通話など)」です。
会議や電話で話している人は音声認識されてることを意識していないことが多いので、相手の人間に伝わるぎりぎり伝わる、砕けたしゃべり方をします。なので難易度が高くなります。
話し方の違いに対してAmiVoice APIでは、利用シーン(話し方)に応じて異なる種類のエンジンを提供し対応しています。例えば、「音響モデル」という音を分析するエンジンを「会話用」と「音声入力用」の2つ用意しています。
2.外部サービス利用の可否
続いて、外部サービスが使えるかどうかも、音声認識の精度を左右します。
インターネットが使えない環境やセキュリティ的な観点で音声を外部に送信できない現場で音声認識を利用したいというケースもあります。
<外部サービスが利用できる場合>
インターネット上に公開された音声認識APIを利用できる
・多くのメーカーは音声認識APIを公開しており、これらをすべて利用可能
・簡単に使える一方、細かい設定や調整などができない場合が多い
・障害発生時に利用できなくなる
・セキュリティに関して注意が必要な場合がある
まず、インターネットが使える外部サービスが利用できる場合について、世の中の大半の音声認識エンジンはインターネット上のAPIで提供されてるものが多いと思います。
インターネットが使えれば使える音声認識エンジンの選択肢が広がり、簡単に操作するものが多いです。その一方で、あまり細かい設定ができず、音声認識エンジンのカスタマイズできないという点があります。
変わって、外部サービスが利用できない場合、あるいは内部会議、内部環境を構築する場合だと、ローカルネットワーク上にサーバーを構築する場合についてです。
<外部サービスが利用できない場合(内部環境構築)>
ローカルネットワーク(オンプレミス・プライベートクラウド)にサーバー構築する
・利用可能な音声認識エンジンメーカーは限られる
・細かい設定や、独自の音声認識エンジンの学習などができるものもある
・障害発生時は自⼒で対応が必要
・セキュリティレベルは自由自在にできるが、自己責任
端末上で音声認識をする
・利用可能な音声認識エンジンメーカーはさらに限られる
・端末のOSやスペックによっては使えない場合もある
音声認識エンジンをローカルネットワークで使用する場合は、内部環境構築サーバーを作る必要があります。その場合、障害発生したときは自社で対応するという課題があります。
ローカルネットワークで使用できる音声認識エンジンの種類は限られますが、独自で細かい設定やカスタマイズが可能です。
スマホやPCの端末内で音声認識する方法もあります。使用できるエンジンや端末もかなり限られてきます。
3.リアルタイム性
音声認識エンジンの前提条件について解説してきましたが、これが最後の条件になります。最後は「リアルタイム性」についてです。
多くの音声認識エンジンは「ストリーミング」と「ファイル」の2種のインターフェースを持つという特徴があります。※メーカーによっては異なる場合もあります。
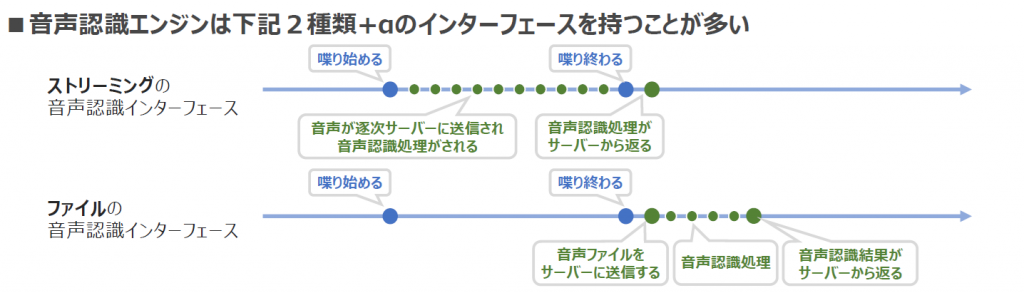
上記の図を参照にそれぞれの特徴を説明していきます。
ストリーミングは、話し始めたらすぐに話した音をサーバーに送って、話している途中でも音声認識を行います。なので話しの途中でも、経過の音声認識結果を見ることができます。話し終わった瞬間に音声認識処理も終わって、すぐに結果がわかるというのが特徴です。
ファイルは、話し始めてから終わるまでは、録音だけしてサーバーへの送信は行いません。その代わり話し終わって音声データをファイルに保存できたら、データをサーバーに送って音声認識をします。なので、話し終わってから音声認識結果が確認できるまでは少し時間がかかるのが特徴です。
| インターフェース | 特徴 | 典型的な用途 |
|---|---|---|
| ストリーミング | ・逐次処理のためリアルタイム性が高く、通常喋り終わったら速やかに音声認識結果が得られる ・音声認識の途中経過が得られる場合もある ・少し実装が難しい ・応答速度が求められるならストリーミングが良い | ・音声コマンド ・音声翻訳 ・音声による文字入⼒ ・音声対話システム |
| ファイル | ・喋り終わってから音声認識処理が開始されるので、リアルタイム性は低い ・音声認識処理にストリーミングよりも時間をかけることが可能なため、高精度になる場合がある →AmiVoice APIでは “非同期HTTPインターフェース” が他よりも高精度 ・応答速度が求められないならファイルが良い | ・会議や通話の内容の分析 |
ファイルはリアルタイム性は低いですが、音声認識に処理時間をかけられます。メーカーによりますが、ストリーミングよりも音声認識精度を上げることができます。実はAmiVoiceはほんの少しファイルの方が音声認識が高くなるような調整をしています。
用途としては反応速度が求められない。例えば分析などの用途にはファイルの方が向いていると思います。
音声認識の前提条件まとめ
音声認識の前提条件について前後編に分けて解説してきました。音声認識システムの導入の検討時に役立つような音声認識エンジンの基礎知識といった内容になっています。
企業や職種、現場によって抱えている課題は異なるように、音声認識システムの特性を最大限に生かして活用できるかは各シーンで異なってきます。今回解説しました前提条件を音声認識エンジンを選定、導入検討時に活用していただければと思います。
次回は音声認識のためのUI・UXについて解説します。
よく見られている記事



新着記事
-
運用データで見る「発話区間割合」

-
AmiVoice API アップデート解説 ボイスボット向け新パラメータで応答待ち時間を短縮

-
AmiVoice APIアップデート解説 End-to-End対応の「単語強調」機能

カテゴリ一覧
アーカイブ
