ゼロからわかる!音声認識精度(音声認識率)の測り方

 安藤章悟
安藤章悟
みなさま、こんにちは。
「音声認識精度の測り方」を詳しく説明します。
こちらのコンテンツは以下より動画でもご覧いただけます。
▶【動画】音声認識開発者が教える ゼロからわかる!音声認識率の測り方
1.そもそも音声認識精度とはなにか
音声認識精度は音声認識の「正確さ」を示す定量指標です。
式はこうなります。
音声認識精度 = (正解文の文字数 – 誤認識した文字数)÷ 正解文の文字数
具体例で見てみましょう。
- 例1)
正解文 「いつもお世話になっています」
音声認識結果「いつもお世話になっています」
この例1の場合は、正解文と音声認識結果が完全に一致してます。なので誤認識は0文字ですね。
誤認識が0文字なら常に音声認識精度は100%になりますが、一応計算すると、正解文が13文字あるので、(13-0)÷13=100% となります。
- 例2)
正解文 「いつもお世話になっています」
音声認識結果「いつもお世話になっております」
この例2では、正解文の「なっています」の部分が音声認識結果では「なっております」となっています。誤認識した文字数の数え方は以下のようになり、誤認識文字数は2文字になります。
- 「い」が「お」に置き換わってしまった(置換誤りが1文字)
- 「り」が挿入されてしまった(挿入誤りが1文字)
正解文は13文字ですので、(13-2)÷13 ≒ 84.62% が音声認識精度になります。
ちなみに誤認識には以下の3種類があります
- 置換誤り:喋ったことと違うことが音声認識されてしまった(置換されてしまった)
- 挿入誤り:喋ってないのに音声認識されてしまった(挿入されてしまった)
- 削除誤り:喋ったのに音声認識されなかった(削除されてしまった)
補足です
- ここでは音声認識精度を「文字単位」で計測していますが「単語単位」で計算することもあります。英語では単語単位が一般的ですが、日本語の場合、形態素解析が必要になるため、文字単位で計算されることが多いです。
- 「音声認識精度」ではなく「音声認識率」という表現をすることもあります。AmiVoiceでは慣例としてこの2つを同じ意味として使うことが多いです。一般的な論文等では下記のように意味を区別することが多いです。
- 音声認識精度:誤認識は「置換誤り」「挿入誤り」「削除誤り」の3種類(上述の説明通り)
- 音声認識率:誤認識は「置換誤り」「削除誤り」の2種類(挿入誤りは含めない)
2.どんな時に音声認識精度を使うか
音声認識精度を使うシーンはいろいろあると思います。僕は以下のような場合によく使います
2-1.複数の音声認識エンジンの比較
音声認識エンジンはいろいろなメーカーが出しているので、どれを使うべきか悩みます。その時に、音声認識精度を計測することで、正確さを定量的に比較することができます。
2-2.音声認識の環境を変えた時の評価
音声認識の精度を良くするために、マイクを変える、登録単語を変える、設定を変えるなど、環境を変えることがあります。これを闇雲にやると良くなったのか悪くなったのかよく分からなくなるので、音声認識精度を定量的にウォッチすることで何が効果的なのかを見極めることができます。
2-3.音声認識によって課題が解決可能かの評価
音声認識を使う時は、何かしらの課題を解決したい時が多いです。音声認識精度が高くなるほど改善効果は高くなりがちですが、音声認識精度がそこまで高くなくてもいい場合もあれば、とんでもなく高くないと意味をなさない場合などもあります。音声認識精度と改善効果を見ながら、どのくらいまで注力するべきかを評価します。
2-4.音声認識エンジンの弱点を見つける
音声認識はどうしても聞き間違える(誤認識する)ことがあります。ですが、誤認識した箇所をよく観察すると、同じ単語を何回も間違えていたりなど、何らか傾向があるものです。誤認識した箇所を満遍なくチェックして対応しようとすると時間がかかりすぎますし、そもそも全ての誤認識を無くすことは(今のところ)できません。重要な箇所や、頻発する箇所に注力することが大事だったりします。
ぶっちゃけ最後の弱点探しは音声認識精度を計測しなくてもできるのですが、「ひと発言ごと」など細かめに音声認識精度を出して、数値が悪いところに着目すると捗るので、僕はできるだけやるようにしています。
3.音声認識精度の測り方
では実際に音声認識精度を測るときのステップをご紹介します。計測の流れは以下の図のようになります。
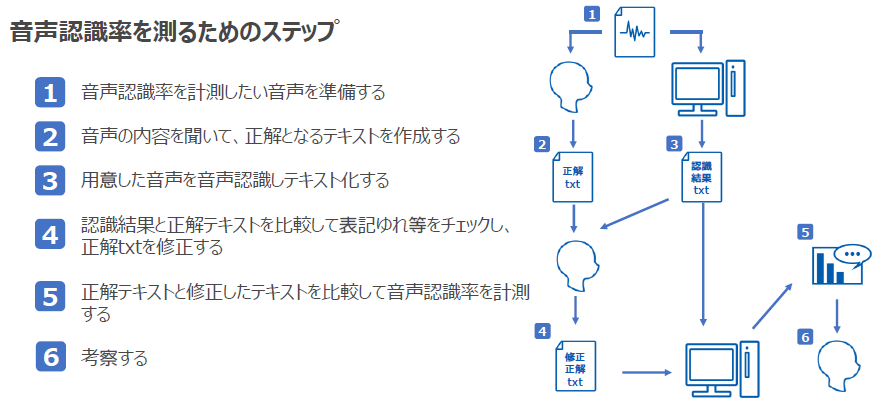
ステップ① 音声認識精度を計測したい音声を準備する
まず計測用の音声を準備します。下記に注意してください。
- なるべく音声認識を使う実環境と同じ音声を準備する方が好ましいです。音声には話者・喋り方・喋る内容・マイク・録音設定・周囲の雑音などいくつかの要素がありますが、これらが実環境と変わってしまうとあまり良い計測にならないです
- なるべく多人数の音声を準備する方が好ましいです。ある特定の人だけの音声だとあまり良い計測にならないです。AmiVoiceでは目安のようなものは設けていませんが、僕はできれば男女合計7人以上になるようにしています
- なるべくたくさんの音を集める方が好ましいです。ほんの数回喋っただけだとあまり良い計測にならないです。AmiVoiceでは合計の発話時間で2時間以上くらいを目安にすることが多いです。
僕がたまに見かけて「それで音声認識精度を判断しないでぇー」と思っちゃいがちなアンチパターンをいくつか紹介しましょう
- 早口言葉を喋ってみて音声認識できるか確認した → 音声認識エンジンの想定外のフレーズだと性能が全く発揮されない場合があります。実際に使うときに喋る内容を喋った方がいいです。
- 少人数が数回喋った音声だけで判断した → 偶然音声認識率が高かったり、低かったりしてしまいます。
- 実際はヘッドセットマイクを使うが、計測時はICレコーダーで録音した音を使用した → ICレコーダーだと周囲のノイズを比較的拾いやすく実際よりも精度が低く計測されてしまうことがあります。
- 実際は雑踏の中で使うが、計測時は会議室で収録した → 雑音が少なく、実際よりも高い音声認識精度になってしまいます
- あらかじめ喋る原稿を作成し、それを読み上げた → 読み上げだと明瞭に喋ることになりやすく実際よりも高い音声認識精度になってしまいます
ステップ②音声の内容を聞いて、正解となるテキストを作成する
次に、準備した音声が何と喋られたものかを聞き起こしして、正解となるテキストを作成します。下記に注意してください。
- 人間は意外と聞き間違いをするので、できるだけ注意深く聞き起こすようにしましょう。可能であればダブルチェックできるとより良いですが、コストもかかるので厳密な計測を目指さなければナシでもOKでしょう。
- 音声認識精度の計測対象となる箇所だけを聞き起こししましょう。不要な箇所も正解テキストにしてしまうと一体何を計測しようとしているのか分からなくなってしまいます。
- 何と喋っているか聞き取れない音が出てくることもあります。これはなんとかして聞き起こすしかないのですが、もしも録音環境等の不備などが原因であれば計測対象から外したり再収録することも検討しましょう。
また、このステップですが、音声認識をしてその結果を見ながら手直しをして正解を作ってもよいでしょう。音声認識精度がそれなりに高ければ結構楽になります。ただしその場合、音声認識結果を見ながら聞くとさもそれが正解であるように音声を空耳することが結構あります。意識をちゃんと保って正解を聞き起こすようにしましょう。
下記は気を付けたいアンチパターンです。
- 発話者の横にあったテレビの音も聞き取れたので書き起こした→ その音は認識対象なのか?をよく考える必要があります
- 音量が小さすぎて何を言ってるのか分からないので、テキトーに勘で書き起こした → 音量が改善可能なら再収録を検討しましょう
- 聞き起こしした内容よりも、音声認識結果の方が正しい気がしてきた → 聞き起こしのミスの可能性があります
ステップ③ 用意した音声を音声認識しテキスト化する
実際に使っている音声認識システムで、用意した音声データを音声認識します。
ここは音声認識システムによってやり方が異なりますので手順は省略します。
(手順外)ここで一度音声認識率を計測してみる
まだステップは残っていますが、この段階で音声認識精度を計測することが可能ですので、先に手順外ですが音声認識精度の計測をしてみます。Python の JiWER というライブラリを使用します。詳しい手順はこちらをご覧ください。
- サンプルコードはこちらです
import jiwer
reference = "お世話になっております"
hypothesis = "お世話んなっとりますー"
output = jiwer.process_characters(reference, hypothesis)
print(f"正解文の文字数: {output.hits + output.substitutions + output.deletions}")
print(f"正解した文字数: {output.hits}")
print(f"置換誤り文字数: {output.substitutions}")
print(f"挿入誤り文字数: {output.insertions}")
print(f"削除誤り文字数: {output.deletions}")
print(f"エラー率: {output.cer*100}")
print(f"音声認識精度: {(1-output.cer)*100}")referenceが正解文、hypothesisが音声認識結果です。この2つをjiwer.process_characters()に入力し、結果をprintで表示しています。
実行すると次のような結果が出力されます。
正解文の文字数: 11
正解した文字数: 8
置換誤り文字数: 2
挿入誤り文字数: 1
削除誤り文字数: 1
エラー率: 36.36363636363637
音声認識精度: 63.63636363636363このサンプルプログラムだと1行の音声認識精度計測しかできませんので、処理したい音声認識結果に合わせて複数行を処理できるようにするなどコードを変える必要があります。
さて、この手順で音声認識精度を計測することができますが、実はこのステップで計測してしまうと表記の揺れが問題になることがあります。以下のようなものです。
- 音声認識結果と正解で送り仮名が違う
- 音声認識結果と正解で全角・半角が違う
- 音声認識結果と正解で英単語の表記(アルファベット・カタカナ)が違う
- 音声認識結果と正解で数字の表現(漢数字・算用数字)が違う
- など
例えば、音声認識結果が「ウィンドウズ」で正解が「Windows」だと音声認識精度は0%になっちゃうんですね。こういった「意味と読みが同じだけど表記が違う」という箇所は、音声認識結果と正解を見比べて統一した方が好ましいです。
ステップ④認識結果と正解テキストを比較して表記揺れ等をチェックし、正解テキストを修正する
さて、上記で手順外ですが音声認識精度を計測しました。このままだと表記揺れがあって、実態よりも音声認識精度が低く出てしまうかもしれません。下記の観点でチェックして、もしも揺れている場合は表記が一致するように正解文を修正するといいでしょう。
- 重要な表記ゆれ:以下は音声認識結果全体に対して大きな影響があるので要注意です
- 記号やアルファベットの全角・半角が揺れていないか
- 英単語の表記(アルファベット・カタカナ)が揺れていないか
- 数値の表現(算用数字・漢数字)が揺れていないか
- 頻出する単語の揺れがないか
- 軽微な表記ゆれ:厳密な計測でなければ誤差扱いしてもいいと思います
- 頻出しない単語の揺れがないか
また、音声認識精度の計算から除外した方がよい文字もあります。下記は状況に応じて文章から削除するなどしましょう。
- 句読点(、。)
- 疑問符(?)や感嘆符(!)
- その他、発音しない記号等
ステップ⑤正解テキストと修正したテキストを比較して音声認識精度を計測する
テキストが修正し終わったら、(手順外)で説明した通りJiwerで音声認識精度を計測します。
ステップ⑥考察する
音声認識率が計算できたら、認識率の数字を見て考察します。
- 音声認識結果全体の音声認識精度を見る
- 他エンジンとの比較や、マイクを変えた時の比較などでは、全体の音声認識精度の値を見て比較します。
- 話者ごと・性別ごと・喋る内容ごと、などある程度分類をして音声認識精度を比較するとその属性ごとにどの程度ばらつきがあるか等がわかります。
- 音声認識の弱点を探したい時は、挿入誤りと削除誤りに注目することがあります。通常は同数程度発生することが多いのですが、挿入誤りが顕著に多いと、雑音を認識してしまっている可能性があります。また、削除誤りが顕著に多いと、音量が不十分で結果が出⼒されていないなどの可能性があります。
- 余談ですが、Whisper(OpenAI社の音声認識エンジン)では喋った内容が要約されて出力されることがよくあります。このケースでは削除誤りが非常に多くなります。
- (可能ならば)発言ごとなど、細かい単位で音声認識精度を見る
- 発言ごとに音声認識精度を見ることがあります。音声認識精度が顕著に低いところに着目することで、効率よく弱点探しをすることができます。
- 何度も同じ単語や決まったフレーズを誤認識していたり「専門用語が間違いがち」「名前を間違えがち」などある程度傾向が見えてくると思います。この傾向を見ながら、音声認識を使う用途にとって重要な誤認識があれば、そこを重点的に対応(単語登録など)するとよいでしょう
いかがでしたでしょうか。こちらのコンテンツは以下より動画でもご覧いただけます。
▶【動画】音声認識開発者が教える ゼロからわかる!音声認識率の測り方

この記事を書いた人
よく見られている記事



新着記事
-
AmiVoice APIアップデート解説 End-to-End対応の「単語強調」機能

-
動画に字幕を簡単合成!音声認識APIで作る字幕ワークフロー

-
AmiVoiceの単語登録APIで音声認識をもっと自由に!

カテゴリ一覧
アーカイブ
