音声認識がうまくいかないのはネットのせい?音声認識がスムーズに動く通信環境の作り方

 安藤章悟
安藤章悟
みなさま、こんにちは。
音声認識の精度を上げるコツをテーマに連載してきた本連載も、今回で最終回になります。最後のテーマは「音声認識に適切な通信環境」について説明していきます。
音声認識はCPU/GPUやメモリーなどのリソースを大量に消費するため、多くの場合、PCやスマートフォン上での処理ではなく、クラウドのサーバー上で処理を行います。そのため、ネットワークの通信環境が重要になります。
今回は、音声認識サーバーを使用する際のネットワークや、Bluetoothなどの無線通信の環境について詳しく解説していきます。
音声認識には「適切な通信環境」が必須!
まず初めに音声認識に必要な通信データ量について説明します。
・送信(クライアント→サーバー)
・音声データは1チャネルあたり非圧縮で 32kBytes/秒 が必要です
・リクエスト時に音声認識の設定情報を送信することもあります
・受信(サーバー→クライアント)
・音声認識結果が返送されます
・その他
・プロトコルのヘッダ等によるオーバーヘッドが発生することがあります
上記はAmiVoice APIを使用する際にやり取りされる主要なデータですが、他の音声認識エンジンではそれ以外の情報が送受信される可能性もあります。
ポイントは、通信データの大半がクライアントからサーバーに送信される音声データであることです。音声データ以外は主にテキスト情報であり、通常はデータ量が大きくないことが一般的です。
音声データは、サンプリングレート16kHz、量子化ビット数16bitが音声認識では一般的で、これによる1秒あたりのデータ量は次のように計算されます。
- 16kHz×16bit = 256kbit/秒 = 32kB/秒
また、下記の要因で音声データ量は変動しますので注意が必要です
- 複数チャンネルの音を同時に処理する場合(例えば2チャンネルの場合、データ量は1チャンネルの倍になります)
- より高音質な音声データを送信する場合(例えばサンプリングレートが24kHzの場合、データ量は16kHzの1.5倍になります)
- 固定電話の音声など低音質な音声データを送信する場合(サンプリングレートを8kHzにすることが多く、データ量は16kHzの半分になります)
- 圧縮形式に対応している場合(圧縮した分だけデータ量が削減されます)
音声データ以外は通常そこまで大きくありませんが、特定の条件下では大きなデータを送受信することがあります。例えばAmiVoice APIではリクエスト時に大量の単語登録リストを送ったり、音声認識用の文法定義(ルールグラマ)を送ることが可能です。このあたりのデータサイズは必要に応じて見積もりを行ってください。
これを踏まえて、適切なネットワーク環境で十分な帯域を確保することが音声認識を使用する際に必要になります。もしもネットワーク環境が悪く帯域が不十分な場合に発生する影響として、以下の2点が挙げられます。
- ストリーミングの場合
音の送信が遅延したり、場合によっては欠落、あるいはタイムアウトでエラーになることも考えられます。 - ファイル送信の場合
音声の送信に時間がかかり、音声認識結果が返ってくるまでの時間が長くなります。また場合によってはタイムアウトでエラーになることも考えられます。
また、ネットワーク通信以外にも、無線マイクやBluetoothマイクの通信環境が悪い場合、音声認識精度が低下することがあります。この原因としては、混線や電波干渉、障害物などが考えられえます。音が途切れたり、音声が正しく伝わらない場合は、一度マイクと受信デバイス間の通信環境を確認、改善を試みてください。
通信環境が悪い場合はどうすればよいか
通信環境が悪い場合の対策について、いくつかの方法をご紹介します。
まず、ネットワークの環境が不安定な場合は、インターネット上のクラウドサーバーを使用せず、ローカルネットワーク内に音声認識サーバーを構築する方法があります。これによりネットワークの遅延や不安定さを軽減/解消することが可能です。ただし、この対策が可能な音声認識エンジンは限られます。AmiVoiceの場合では「AmiVoice API Private」というプランで提供しています。その他、例えばOpenAIの「Whisper」を使用すれば、自前でサーバーを構築することも可能です。
次に、サーバーを使用せずにPCやスマートフォン上で音声認識を行う方法もあります。この場合、ローカルネットワークすら必要とせず、完全にオフラインで音声認識が実行できます。AmiVoiceの場合では「AmiVoiceSDK」を使うことで、このオフライン音声認識が可能です。
ネットワーク通信環境が悪い場合
・ローカルネットワーク内での音声認識サーバー構築
▶AmiVoice API Private で利用可能
▶Whisper など自身でサーバー構築可能なエンジンも存在
・端末内でのオフライン音声認識
▶AmiVoice SDK で可能
続いて、無線マイクやBluetoothマイクの通信環境が悪い場合の対策について説明します。
まず、できるだけ有線マイクや端末内蔵のマイクを使用することが最も確実な方法です。しかし、無線やBluetoothを使用する必要がある場合、以下のような対策が考えられます。
- 電波の混線を避ける
他の無線・Bluetoothデバイスや電子レンジなどの電波を発する機器から離れ、混線を避けることが重要です。人混みでは混線をしやすいので、そういった環境から離れることも有効です。 - 障害物の影響を減らす
壁や家具などの障害物があると通信が途切れる可能性が高まります。障害物を減らしたり、またはデバイスの送信機と受信機を近づけることで通信環境を改善できます。 - 電波のチャネルを変更する
使用しているデバイスによっては、電波のチャネルを変更できるものもあります。これにより他の機器と干渉しないチャネルに切り替えられる場合があります。 - メーカーへの問合せ
マイクによっては上記以外の対策があるかもしれませんので、詳細な対応方法をマイクのメーカーに問い合わせることも検討するといいでしょう。
無線マイク、Bluetooth マイクの通信環境が悪い場合
・有線マイクやオンデバイスのマイクを使用する
・電波が混線する環境から離れる
・障害物を減らす、または送信機と受信機の距離を短くする
・使用する電波のチャネルを変更する
・詳細はマイクメーカーに問い合わせる
音声認識の精度を上げるコツのまとめ
ここまで音声認識の精度を上げるコツについて5回に分けてお話をしてきました。改めてポイントをまとめてご紹介します。
音声認識率の高さに影響するポイント
①適切な喋り方をする
②適切なデバイスを選択する
③そのデバイスを適切に使う
④雑音が少ない環境で使う
⑤適切な通信環境で使う
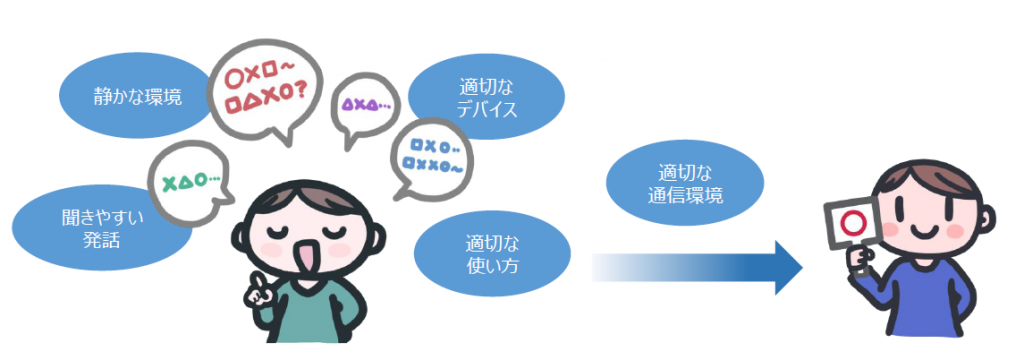
今回紹介したポイントを実践し、工夫してよりよい環境で音声認識をご活用していただければと思います。
この記事を書いた人
よく見られている記事



新着記事
-
AmiVoice API アップデート解説 ボイスボット向け新パラメータで応答待ち時間を短縮

-
AmiVoice APIアップデート解説 End-to-End対応の「単語強調」機能

-
動画に字幕を簡単合成!音声認識APIで作る字幕ワークフロー

カテゴリ一覧
アーカイブ
