音声認識がうまくできない時の、音声波形チェックのコツとポイント

 安藤章悟
安藤章悟
みなさま、こんにちは。
私は「音声認識がうまくできないなー」という時に音声波形をチェックすることがあります。そのやり方を説明します。
音声波形をチェックするツール
まずはツールが必要です。私はAudacityをよく使います。
(2024年8月時点)トップページの黄色いボタンからダウンロードすると「Muse Hub」という、プラグインや素材が買えるアプリが最初インストールされて、そこからAudacityをダウンロードすることになるようです。音声波形のチェックだけでよければ、ボタンの下にある「Download without Muse Hub」をクリックするといいでしょう。

音声波形を見てみる
Audacityをインストールし起動したら、音声ファイルを開いてみましょう。以前の記事(https://acp.amivoice.com/blog/2024-8-30/)の抜粋ですが、下記のような音声波形が表示されると思います。
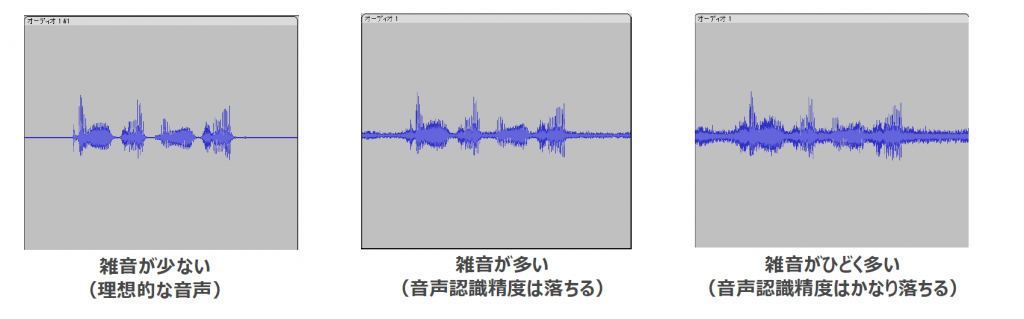
例えば上記だと、左の音声波形は雑音が少なく音声認識もやりやすそうです。しかし中央や右のような音声波形だと雑音が入っていることが分かるので、その原因を探ったり何かしら改善の手を打つ必要がありそうです。
他にも音声波形を見て音声認識精度への悪影響が分かるパターンはいくつかあります。
例えば下記音声波形です。
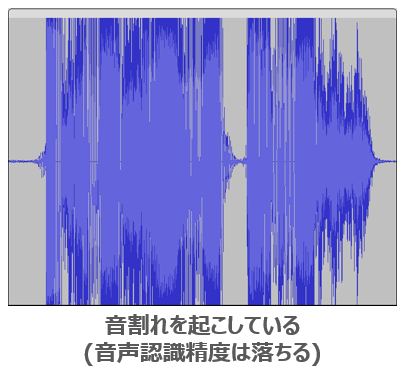
この音声波形は音圧の上限を振り切っている、いわゆる「音割れ」をしているパターンです。音割れをすると音声データの特徴が歪んでしまうため音声認識に悪影響が出ます。多少の音割れなら問題ありませんが、この音声波形くらい音割れをしていると音声認識精度はかなり落ちてしまうかもしれません。マイク音量を見直すなどの対策が必要になります。
続いて一見音割れをしていないように見えて音割れをしているケースです。

上記は音圧の上限には達していないのですが、音声波形の上限下限が直線的になっています。おそらくこれは、音声が伝わる経路のどこかで一度音割れを起こしているケースで、音割れと同じように悪影響が出るものです。経験談ですが、コールセンターなどの複雑な電話系音声システムでたまに目撃することがあります。このようなケースでは、音声の経路を調べていき、音割れをしている箇所が無いか調べることになります。
次は、音割れの逆で、音量が小さすぎるケースです。
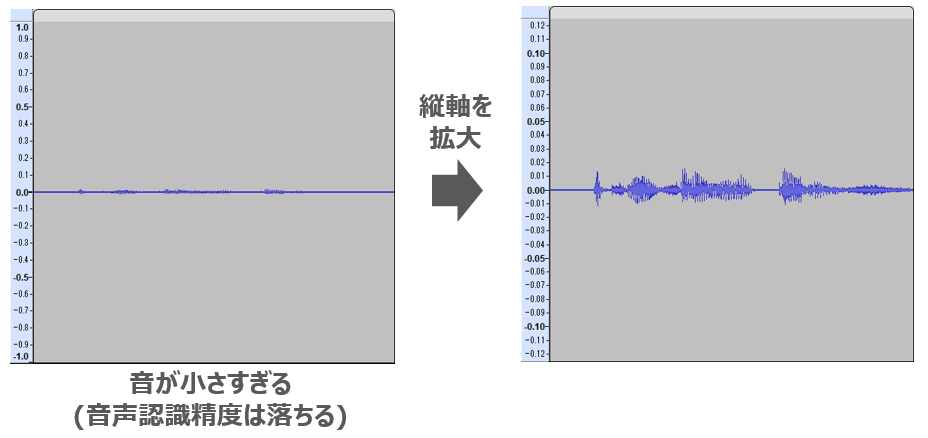
左の音声波形だとよく見えないので右の音声波形では縦軸(音圧)方向を拡大しています。Audacityで表示される音圧の最大値は1.0ですが、この音声波形はだいたい0.01周辺くらいの音圧でしか録音されていません。音声認識エンジンにもよるかもしれませんが、AmiVoiceではここまで音が小さいと音声認識がうまくされないことが多くなります。
どのくらいの音量があればいいのか
どのくらいの音量が音声認識に必要かは、基準のようなものは無いため言及しにくいのですが、参考にMicrosoftのAzure AI Speechのドキュメントでは下記の記述があります。
For human speech 13 bits are needed, which is rounded up to a 16 bit sample.
https://learn.microsoft.com/ja-jp/azure/ai-services/speech-service/concepts/audio-concepts
これは、人の声には16bit中13bit以上の情報量が必要ということだと思います。16bit(2の16乗で65536階調)中13bit(2の13乗で8192階調)となるので、Audacityの音量表現(最大が1.0)に合わせると8192÷65536=0.125の音量が必要ということになりそうです。
AmiVoiceの場合は音量が0.125より多少小さくても音声認識可能ですが、0.01だと小さすぎます。概ね0.03~0.05程度以上の音量は最低限確保したいところです。そのためにマイクに近づいて喋ったり、大きな声で喋ったり、マイク音量を大きくするなどの対策が必要になります。
また、音量は録音する時点で十分な値を確保しなくてはいけません。不十分な音量の音声を、後からプログラム等で増幅することはできますが、これはデジカメのデジタルズームと同じで情報量は増えません。録音する時に十分な音量を確保するよう注意してください。
スペクトログラムを見てみる
Audacityでは、音声を波形だけでなく、スペクトログラムという表現で見ることもできます。スペクトログラムを見ると、音声波形を見たり音を聞いても気づきにくい音声の問題に気づくことがあります。
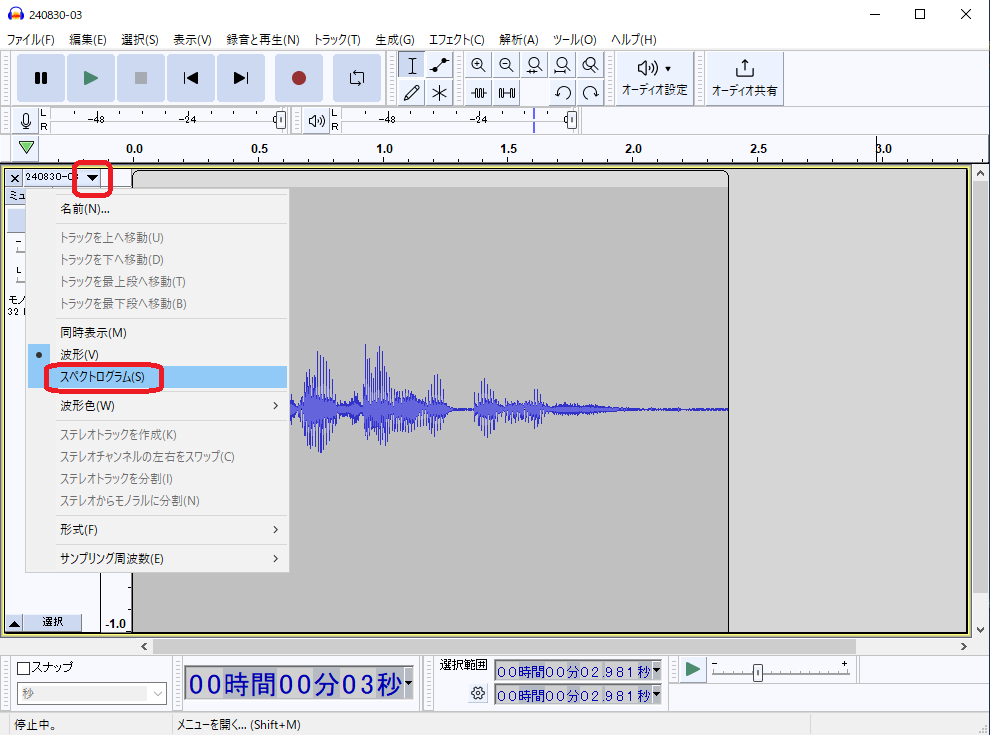
上記画面の▼をクリックして「スペクトログラム」を選択することで表示できます。
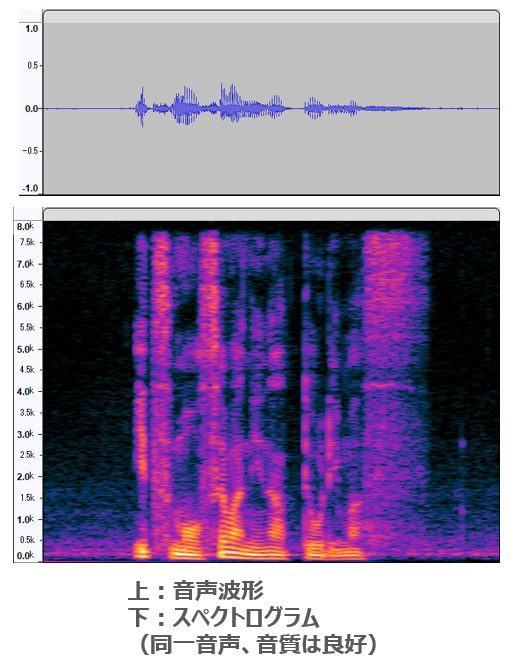
上記は、音声波形(上)とそのスペクトログラム(下)を並べて表示したものです。スペクトログラムは、横軸が時間なのは音声波形と同じですが、縦軸が周波数になっていてどんな高さの音がどのくらい含まれているかを色で表現しています。スペクトログラムは模様のように見えますがこれがいわゆる「声紋」です。
この音声はノイズが少なく音質も高いので、スペクトログラムにも特に問題はありません。では、次に「音声認識に良くないと分かるスペクトログラム」の例を1つ挙げましょう。
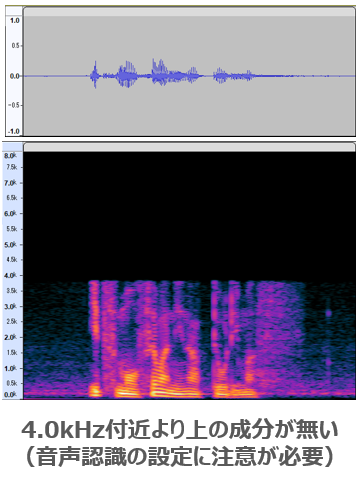
上記の音声は、上の音声波形を見ると雑音が少なく音声認識には問題なさそうに感じます。しかし、スペクトログラムを見てみると、声紋の上部が真っ黒(4.0kHz以上の周波数成分が無い)になっています。このような音声では音声認識精度が低下する恐れがあります。
これはどういうことかというと、音声に含まれる周波数成分が十分に記録されていないということです。具体的にはスペクトログラムの縦軸を見ると分かるのですが、音声フォーマットは8kHzまでの音を収録できるのに、中身の音には4kHz付近までしか収録されていません。人間の声には4kHz~8kHzの周波数成分も含まれていますが、それらが欠けてしまっています。
以下のような場合に、このような現象が見られます。
- 音声が固定電話の回線を通った場合
- Bluetoothで音質の低いプロファイルやコーデックを使用した場合
- アプリケーションやデバイスなどの設定で低音質にした場合
- など
このような場合にどうすればいいかというと、まずは上記原因を排除して、スペクトログラムで4kHz~8kHzの周波数成分も表示されるように録音することが第一です。
しかし、固定電話回線の音声など、どうしようもないものもあります。その場合は下記の対策を取るとよいでしょう
- AmiVoice API の場合:
サンプリングレート8kHzで録音してください。8kHzの音声をサーバーに送信すると内部で自動的に固定電話などの音質の低い音声を対象とした音声認識エンジンが選択されます。
※「会話_汎用」エンジンのみの動作です - その他:
メーカーによっては「電話用」などの音声認識エンジンが用意されていることがありますので、そのエンジンを使用するとよいでしょう。
補足
さて、最後に1点補足で、スペクトログラムの上部が真っ黒だと絶対にダメというわけではないです。例えば下記はCD音質である44.1kHzでサンプリングした音声のスペクトログラムです。この音は正常に録音されていて、音声認識精度も問題ないものです。
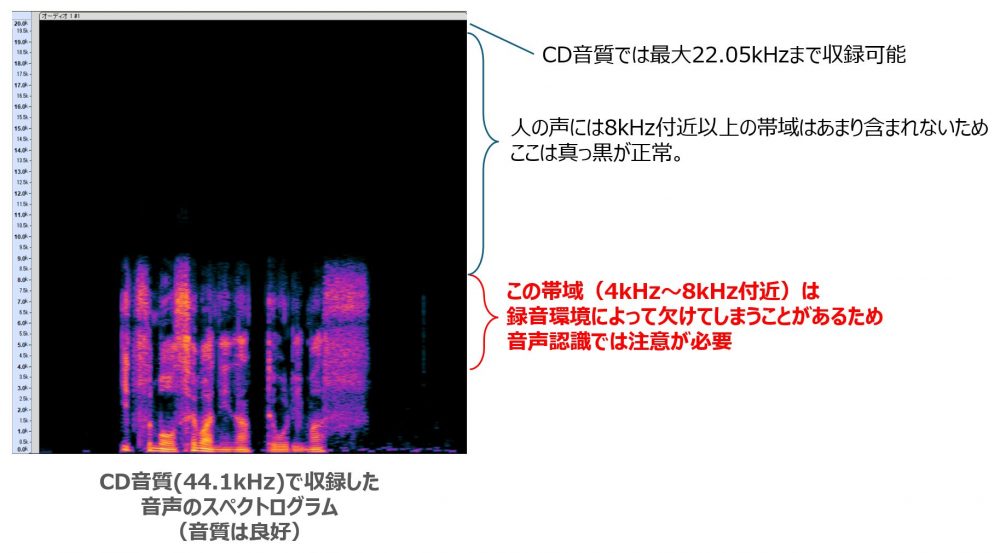
大事なのは、赤文字で書いた部分です。音声認識では人の声の周波数成分のうち数十Hz~8kHzまでを使うことが多いです。ですが、上述したような固定電話回線などの要因があると特に4kHz~8kHz付近が欠けることがあるので、この部分(4kHz~8kHz)が欠けないよう注意が必要になります。
繰り返しになりますが、4kHz~8kHzが欠けている場合は音声認識精度が低下するので、下記どちらかの対策を行いましょう。
- 4kHz~8kHzが欠けないようデバイスや通信経路などを確認する
- (どうしても欠ける場合は)4kHz~8kHzが欠けた音声を対象とした音声認識エンジン(電話音声用など)を使用する
この記事を書いた人
よく見られている記事



新着記事
-
AmiVoice APIを安全に使おう!APIキー発行&接続元IPアドレス制限実践ガイド

-
音声認識API「AmiVoice API」を使ってみよう

-
リアルタイムアプリケーションでレスポンス時間を調整する方法

カテゴリ一覧
アーカイブ
