Pythonでマイク入力の音声認識してみた
 いちかわちゃん
いちかわちゃん
こんにちは【いちかわちゃん】です。
アドバンスト・メディアという会社で開発をしています。
自分用にPythonの音声認識プログラムを作ったので、ついでに公開します。

ちょっと作りが雑な面があるので、参考程度にするようお願いします。
以下の環境で動かしています。
| OS | Ubuntu18.04 |
| アーキテクチャ | AMD64 |
| GCC | 7.5.0 |
手順
1.AmiVoice APIに登録
2.プログラムをダウンロード&実行
動かし方
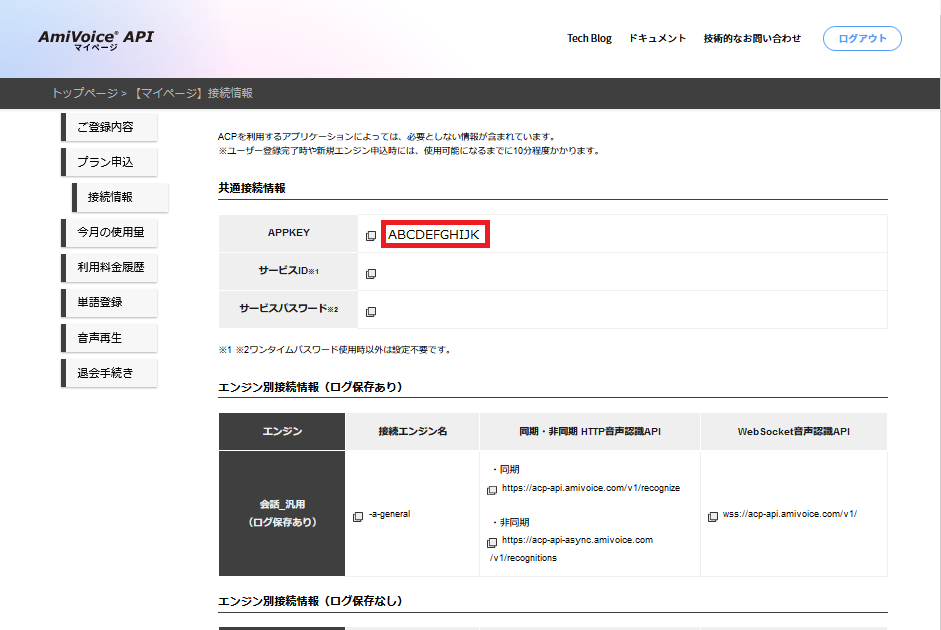
1.AmiVoice APIに登録する。
登録したらAPPKEYをコピー
2.プログラムをダウンロード&実行
以下のコマンドで音声認識を開始出来ます。 XXXの部分は1の作業でコピーしたAPPKEYを貼り付けしてください。
$ git clone https://github.com/r-ichikawa-amivoice/ami_speechrecognizer_py
$ bash run.sh a=XXX
そのあと適当にしゃべると結果が出ます。

解説
main.pyは以下のパラメーターをサポートしています。
| a | AmiVoice APIサイトのAPPKEYを指定。 |
| r | 入力の形式を指定。 “mic”を指定するとマイクから入力。 それ以外の文字列は音声ファイル名として扱い、ファイル認識になる。 |
| o | ログの出力形式を指定。 “console”を指定するとコンソールにログを出力。 “date”を指定すると、yyyy-MM-dd.txtのファイルとしてログを出力。 それ以外の文字列はファイル名として扱い、その名前のファイルにログを出力。 |
| l | ログレベルを指定。指定された値以上のログレベルもものを出力。 “0”:DEBUG-デバック用のログ “1”:INFO-通常のログ “2”:WORN-注意のログ “3”:ERROR-エラーのログ |
マイクを変えたい場合
現状はpulseというマイクから情報を取ってくるようになってます。
変えたい場合はrec.audio_sourceらへんの数値を弄ってください。
指定するデバイスを選ぶときはrec.get_device()をして、使いたいもののindexを指定してください。
チャンネル数を変えたい場合
rec.audio_format[“CHANNELS”]の値を変えてください。
とは言え、AmiVoice APIは現状で1chしか対応していないので、変えないのが無難です。
チャンネル分解して渡したいときは以下みたいなソースを入れとくといいかも。
from functools import partial def parse(audio, length, obj, amivoice): data = obj.channnel_parse(audio) amivoice.write(data[0], int(length/obj.audio_format["CHANNELS"])) rec.recorder_write_func = partial(parse, obj = rec, amivoice = stt)
検討すること
/amivoiceフォルダは最新のソースか分かりません。
更新したいときは以下から取ってくるといいかも。
まとめ
Pythonで音声認識をすることが出来るようになりました。
この記事を書いた人
-
いちかわちゃん
世の中には2種類の人間しかいない。 俺か、俺以外か。
よく見られている記事



新着記事
-
AmiVoice API アップデート解説 ボイスボット向け新パラメータで応答待ち時間を短縮

-
AmiVoice APIアップデート解説 End-to-End対応の「単語強調」機能

-
動画に字幕を簡単合成!音声認識APIで作る字幕ワークフロー

カテゴリ一覧
アーカイブ
