WebSocket + AVAudioEngineを駆使してApple Watchでリアルタイム音声認識してみた

 林政樹
林政樹
みなさま、初めまして。林政樹と申します。
株式会社アドバンスト・メディアにて、iOSやWatchOSのアプリ開発を担当しています。
はじめに
以前、業務用アプリとして WatchOSアプリの開発に携わった際に、WatchOSで実装できることが少ないと嘆いていました。しかし最近になって、それは自分の不勉強なだけでないか、Watchでもいろいろできるのではないかと思い始めてきました。そこで今回は題名にある通り、WebSocketとAVAdudioEngineを使って、リアルタイムで音声認識ができるようなWatchOSアプリの開発に挑戦してみます。音声認識サービスは、当社サービスのAmiVoice Cloud Platformを利用いたします。
完成形
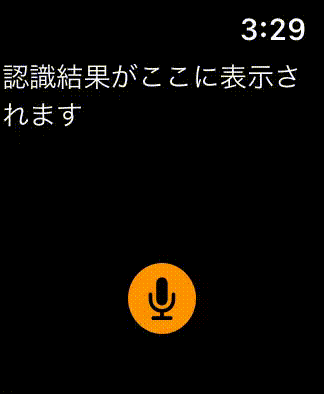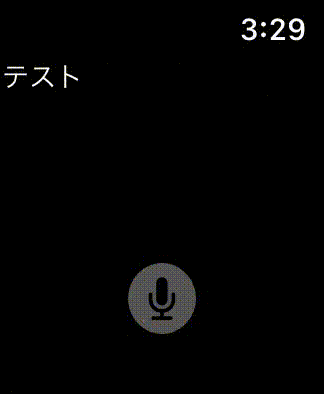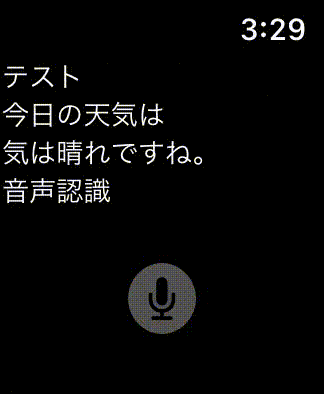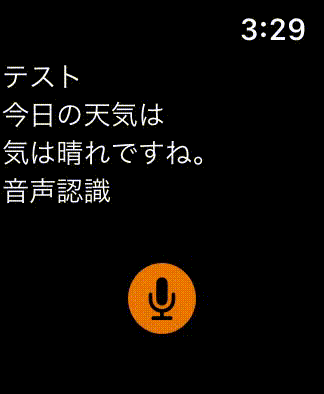
開発環境
- Xcode 12.4
- Swift 5.0
- WatchOS 7.3
実装
流れ
STEP1:AmiVoice Cloud Platform(ACP)への登録
STEP2:プロジェクトの立ち上げ
STEP3:画面構成
STEP4:端末から音声データの取得
STEP5:ACPを利用してWebSocketを介した音声認識
STEP1:AmiVoice Cloud Platform(ACP)への登録
リアルタイムで音声認識をするために、まずはACPに登録します。
登録方法に関しては、下記記事をご覧ください。
AmiVoice Cloud Platform-Tech Blog
STEP2:プロジェクトの立ち上げ
Xcodeを開き、Watch Appを選択してプロジェクトを立ち上げます。
STEP3:画面構成
画面は、下図のようにマイクボタンと認識された結果を表示するラベルで構成します。
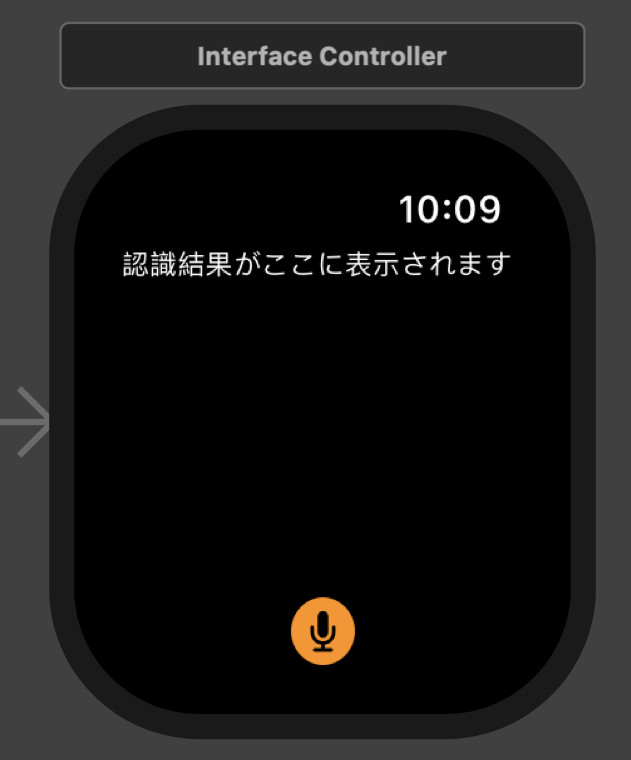
Interface.storyboardにボタンとラベルの部品を設置した後は、InterfaceController.swiftに紐つけます。
また端末のマイクを利用しますので、info.plistにPrivacy – Microphone Usage Descriptionを追加してます。
import WatchKit
import Foundation
class InterfaceController: WKInterfaceController {
@IBOutlet weak var recordButton: WKInterfaceButton!
@IBOutlet weak var resultLabel: WKInterfaceLabel!
override func awake(withContext context: Any?) {
// Configure interface objects here.
}
// マイクボタンタップで呼ばれる
@IBAction func tapRecord() {
}
}
STEP4:端末から音声データの取得
リアルタイム音声認識をWatchOSアプリで実現するには、まず端末のマイクから音声データを取得する必要があります。ここでは音声を取得するためにAVAudioEngineを使用します。
まずはAVFoundationをインポートしてます。さらにAVAudioEngineの変数をInterfaceControllerクラス内に追加します。
import WatchKit
import Foundation
import AVFoundation
class InterfaceController: WKInterfaceController {
・
・
var engine: AVAudioEngine!
・
・
}
次にボタンの押下で、端末のマイク入力から音声データの供給の開始と停止を実行するために下記のコードを追加します。
// start record
func start() {
self.engine.prepare()
do {
try engine.start()
} catch {
return
}
}
// stop record
func stop() {
self.engine.stop()
}
start()とstop()をボタンのアクションと連動させるためにtapRecord()にコードを追加します。
class InterfaceController: WKInterfaceController {
@IBOutlet weak var recordButton: WKInterfaceButton!
@IBOutlet weak var resultLabel: WKInterfaceLabel!
// マイクボタンのフラグ
var isStart = true
・
・
// マイクボタンタップで呼ばれる
@IBAction func tapRecord() {
if isStart {
start()
} else {
stop()
}
isStart = isStart ? false : true
}
}
最後にAVAudioEngineのセットアップを追加します。
func setup() {
//
self.engine = AVAudioEngine()
// Convert AVAudioPCMBuffer to Data
//
func toData(buffer: AVAudioPCMBuffer) -> Data {
let channelCount = 1 // Given PCMBuffer channel count is 1
let channels = UnsafeBufferPointer(start: buffer.int16ChannelData, count: channelCount)
let ch0Data = NSData(bytes: channels[0], length: Int(buffer.frameCapacity * buffer.format.streamDescription.pointee.mBytesPerFrame)) as Data
return ch0Data
}
// 出力フォーマット
guard let outputFormat = AVAudioFormat(commonFormat: .pcmFormatInt16, sampleRate: 16000, channels: AVAudioChannelCount(1), interleaved: true) else {
return
}
// 入力フォーマット
let inputFormat = self.engine.inputNode.outputFormat(forBus: 0)
// 変換器
let converter = AVAudioConverter(from: inputFormat, to: outputFormat)
//
self.engine.inputNode.installTap(onBus: AVAudioNodeBus(0), bufferSize: AVAudioFrameCount(3200), format: inputFormat) { (pcmBuffer, time) in
//
let inputBlock: AVAudioConverterInputBlock = { inNumPackets, onStatus in
onStatus.pointee = .haveData
return pcmBuffer
}
let sampleRateRatio = 16000/inputFormat.sampleRate
let outputFrameCapacity = AVAudioFrameCount(Double(pcmBuffer.frameCapacity) * sampleRateRatio)
guard let outputBuffer = AVAudioPCMBuffer(pcmFormat: outputFormat, frameCapacity: outputFrameCapacity) else {
return
}
var error: NSError? = nil
// convert input format to output format
converter?.convert(to: outputBuffer, error: &error, withInputFrom: inputBlock)
toData(buffer: outputBuffer)
}
}
setup()のinstallTap(onBus:bufferSize:format:block:)のブロック内では、Apple Watchのマイク入力のサンプリングレートが44100Hzであるため、ACPの規格に合うように16000Hzへダウンサンプリングしています。さらにinstallTap(onBus:bufferSize:format:block:)のブロック内で取得した音声は、toData(buffer:)を介して、バッファからDataを取り出します。
このsetup()はWatchOSアプリが起動時に呼び出したいため、awake(withContext context:)の中に置きます。
STEP5:ACPを利用してWebSocketを介した音声認識
STEP4では、端末のマイク入力で音声データを取得するところまで実装しました。次はその音声データを逐一送信して、WebSocketを介して認識結果を受信する必要があります。WatchOSでは、URLSessionWebSocketを利用しますが、まずはどこにどのような形式で音声データを送信する必要があるかを確認します。
ACPのサイトの「I/F仕様 WebSocket音声認識API 概要」によると、クライアントとサーバ間でのやりとりは、下記3つのパケットによって行われます。
- コマンドパケット
- コマンド応答パケット
- イベントパケット
「コマンドパケット」は、クライアントからサーバーに何らかの要求を送るためのパケットであり、その要求に対する応答として「コマンド応答パケット」をサーバーがクライアントに返却します。また「イベントパケット」は、サーバーが何らかの情報をクライアントに伝達するために使用されます。
ではどのようにして、STEP4で取得した音声データをACPに送信すれば良いでしょうか。「コマンドパケット」とその対になる「コマンド応答パケット」のルールをみてみましょう。下図は音声データを共有する際の「コマンドパケット」と「コマンド応答パケット」の状態遷移図です。
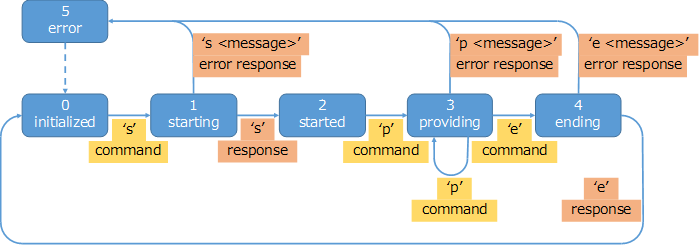
では状態遷移図に従って実装していきます。基本的な流れとしては、ACPとの接続を確立 => ‘s’コマンドを送信 => ‘s’コマンドに対する応答を受信 => ‘p’コマンド+音声データを送信 => ‘e’コマンドを送信 =>’e’コマンドに対する応答を受信 となります。
まずはURLSessionWebSocketの変数をInterfaceControllerクラス内に追加します。
import WatchKit
import Foundation
import AVFoundation
class InterfaceController: WKInterfaceController {
・
・
var engine: AVAudioEngine!
var webSocketTask: URLSessionWebSocketTask!
・
・
}
次にURLSessionWebSocketを利用して、ACPとのWebScoket接続を確立します。
let session = URLSession(configuration: .default)
// ACPに接続するためのURL生成
guard let url = URL(string: "wss://acp-api.amivoice.com/v1/") else { return }
webSocketTask = session.webSocketTask(with: url)
// ACPとの接続を確立する
webSocketTask.resume()
接続確立に成功した後、音声供給の開始の合図として’s’コマンドパケットをWebSocketを介して送信します。’s’コマンドパケットの形式としては、
s <audio_format> <grammar_file_names> authorization=(AppKey) ...
となります。<audio_fomat>は送信する音声フォーマットで、こちらで確認します。また、<grammar_file_names>とAppKeyはACPのトップページ->【マイページ】接続情報から確認します。
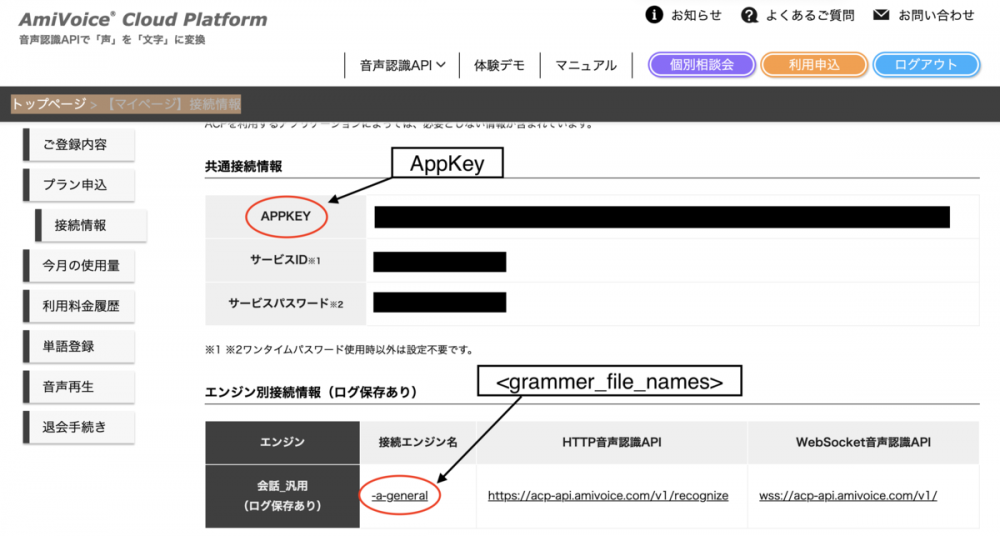
実装では下記のようになります。
// 's'コマンド
let sendText = "s LSB16K -a-general authorization=(AppKey)"
// 's'コマンドの送信
webSocketTask.send(.string(sendText)) { error in
if let error = error {
print("WebSocket sending error: \(error)")
}
}
さらに、送信したメッセージに対してのレスポンスを受け取る必要があるため、下記のような実装をします。エラーがなければ、String型のテキストを受信します。
// 送信したデータに対してのレスポンスを受ける
webSocketTask.receive { [self] result in
switch result {
case .failure(let error):
print("Failed to receive message: \(error)")
case .success(let message):
switch message {
// 受信に成功した場合
case .string(let text):
@unknown default:
fatalError()
}
}
}
また送信した’s’コマンドパケットのレスポンスとしては、下記のようなTEXT型データを受信します。
s
s <error_message>
レスポンスにエラーがある場合、’s’コマンドに半角スペースで隔てられてエラーメッセージが付与されます。成功と失敗を区別するために、受信したTEXT型データに対して下記のような実装が必要です。
var command = text
var body = ""
// 受信したテキストをコマンドとボディに分ける
if let targetIdx = text.firstIndex(of: " ") {
command = String(text[text.startIndex..<targetIdx])
body = String(text[text.index(targetIdx, offsetBy: 1)..<text.endIndex])
}
switch command { // コマンドが's' case "s":
if body != "" {
print("s error: ",body)
} break
以上の実装を下記のようにInterfaceController内に纏めます。 音声の供給を開始する際には、まずresume()を呼びます。
let session = URLSession(configuration: .default, delegate: self, delegateQueue: OperationQueue.main)
guard let url = URL(string: "wss://acp-api.amivoice.com/v1/") else { return }
webSocketTask = session.webSocketTask(with: url)
webSocketTask.resume()
// 's'コマンド
let sendText = "s LSB16K -a-general authorization=(AppKey)"
// 's'コマンドの送信
webSocketTask.send(.string(sendText)) { error in
if let error = error {
print("WebSocket sending error: \(error)")
}
}
receiveWebSocket()
}
func receiveWebSocket() { // 送信したデータに対してのレスポンスを受ける
webSocketTask.receive { [self] result in
switch result {
case .failure(let error):
print("Failed to receive message: \(error)")
case .success(let message):
switch message {
case .string(let text):
classify(text: text)
@unknown default:
fatalError()
}
// .receiveは一度しか呼ばれないため、再起的に呼び出す必要がある
self.receiveWebSocket()
}
}
}
func classify(text: String) {
print("text: ", text)
var command = text
var body = ""
// 受信したテキストをコマンドとボディに分ける
if let targetIdx = text.firstIndex(of: " ") {
command = String(text[text.startIndex..<targetIdx])
body = String(text[text.index(targetIdx, offsetBy: 1)..<text.endIndex])
}
switch command {
// コマンドが's'
case "s":
if body != "" {
print("s error: ",body)
}
break
}
}
これで、接続確立に成功した後、音声供給開始の合図として’s’コマンドパケットをWebSocketを介して送信するところまでの実装が終わりました。次は、実際に’p’コマンドパケットによって音声供給する部分の実装を行なっていきます。’p’コマンドパケットは下記のバイナリ形式で送信します。
p<audio_data>
STEP4で取得した音声データの先頭に、0x70( ‘p’ のアスキーコード)を付け、バイナリフレームで順次送信していきます。実装としては下記のようになります。
// 端末のマイク入力から取得した音声データ
var data_ = data!
// 先頭にpのアスキーコードを挿入
data_.insert(0x70, at:0)// p
// データ型で送信
webSocketTask.send(.data(data_)) { error in
if let error = error {
print("WebSocket sending error: \(error)")
}
}
また ‘s’コマンド応答パケットと同様にして、’p’コマンド応答パケットととして下記のようなTEXT型データを受信します。
p <error_message>
‘p’コマンド応答パケットはエラーが発生した場合にのみ返ってきます。以上の実装を下記のようにInterfaceController内に纏めます。
func setup() {
//
self.engine = AVAudioEngine()
// Convert AVAudioPCMBuffer to Data
//
func toData(buffer: AVAudioPCMBuffer) -> Data {
・
・
return ch0Data
}
・
・
//
self.engine.inputNode.installTap(onBus: AVAudioNodeBus(0), bufferSize: AVAudioFrameCount(3200), format: inputFormat) { (pcmBuffer, time) in
・
・
// サーバーにデータを送信する
send(data: toData(buffer: outputBuffer))
}
func classify(text: String) {
print("text: ", text)
var command = text
var body = ""
// 受信したテキストをコマンドとボディに分ける
if let targetIdx = text.firstIndex(of: " ") {
command = String(text[text.startIndex..<targetIdx])
body = String(text[text.index(targetIdx, offsetBy: 1)..<text.endIndex])
}
switch command {
// コマンドが's'
case "s":
・
・
// コマンドが'p'
case "p":
if body != "" {
print("p error: ",body)
}
break
default:
break
}
}
func send(data: Data) {
// 端末のマイク入力から取得した音声データ
var data_ = data
// 先頭にpのアスキーコードを挿入
data_.insert(0x70, at:0)// p
// データ型で送信
webSocketTask.send(.data(data_)) { error in
if let error = error {
print("WebSocket sending error: \(error)")
}
}
}
最後に音声データの送信終了をサーバーに通知するために’e’コマンドパケットを送信します。’e’コマンドパケットは下記のテキスト形式で送信します。
e‘e’コマンドパケットの送信と応答パケットの受信は、’s’コマンドと同様にして、下記のように実装します。
func disconnect() {
// 'e'コマンド
let sendText = "e"
// 'e'コマンドパケットを送信
webSocketTask.send(.string(sendText)) { error in
if let error = error {
print("WebSocket sending error: \(error)")
}
}
}
func classify(text: String) { print("text: ", text)
var command = text
var body = ""
// 受信したテキストをコマンドとボディに分ける
if let targetIdx = text.firstIndex(of: " ") {
command = String(text[text.startIndex..<targetIdx])
body = String(text[text.index(targetIdx, offsetBy: 1)..<text.endIndex])
}
switch command { // コマンドが's' case "s": ・ ・ // コマンドが'p' case "p": ・ ・ // コマンドが'e' case "e":
if body != "" {
print("e error: ",body)
} break default: break } }
以上でコマンドパケットとその応答パケットの実装が終わりました。最後にイベントパケットを受信する部分を実装していきたいと思います。
イベントパケットには、
- 発話区間の検出
- 音声認識の処理
の状況を表す2つの状態が用意されています。今回は音声認識の結果を表示させることのみが目的ですので、音声認識の処理状況に関連するイベントパケットに焦点を当てて実装していきます。ですので、認識処理が完了し結果が受容された際にサーバーから受信する’A’イベントパケットから音声認識結果を取得して、Watchの画面上に表示させていきます。
‘A’イベントパケットは下記のような形式のJSONとして受信します。
A <result>
※ <result>の例
{ "results":[ {"tokens":[ {"written":"www", "confidence":1.00, "starttime":16020, "endtime":16916, "spoken":"\u3068\u308a\u3077\u308b\u3060\u3076\u308b" } ], "confidence":0.997, "starttime":15700, "endtime":17188, "tags":[], "rulename":"", "text":"www" } ], "utteranceid":"20191127/ja_ja-amivoicecloud-16k-user@016ead249db00a3011a68536-1127_225504", "text":"www", "code":"", "message":"" }
このjson内では、’text’キー(認識結果のテキスト)と’code’キー(認識結果の可否,
値が空文字なら認識成功、それ以外なら失敗)に着目します。’A’イベントパケットの処理はWebSocketのreceive(block:)のブロック内に実装します。
func classify(text: String) {
print("text: ", text)
var command = text
var body = ""
// 受信したテキストをコマンドとボディに分ける
if let targetIdx =
text.firstIndex(of: " ") {
command = String(text[text.startIndex..<targetIdx])
body = String(text[text.index(targetIdx, offsetBy: 1)..<text.endIndex])
}
switch command {
// コマンドが's'
case "s":
・
・
// コマンドが'p'
case "p":
・
・
// コマンドが'e'
case "e":
・
・
// コマンドが'A'
case "A":
print("-> A")
let data = body.data(using: .utf8)!
do {
// jsonをDictionary型に変換
let dic = try JSONSerialization.jsonObject(with: data, options: []) as? [String: Any]
// codeキーの値で認識成功の可否を判断する
let code = dic!["code"] as! String
if (code != "") {
print("Error: ", code)
return
}
// 認識結果を取得する
let res = dic!["text"] as! String
// 前回の認識結果に加算する
self.resultText += res + "\n"
// ラベルに加算した認識結果を代入する
self.resultLabel.setText(resultText)
} catch {
print(error.localizedDescription)
}
break
default:
break
}
}
以上で実装が完了しましたので、実際にシミュレータで音声認識できるかを確認してみましょう。
最後に
今回は「WebSocket + AVAudioEngineを駆使してApple Watchでリアルタイム音声認識」に挑戦してみました。ACPって素晴らしいサービスですね!!!iOSアプリでも実装が簡単ですので、皆さんもぜひお使いください!
今回のソースコード
import WatchKit
import Foundation
import AVFoundation
class InterfaceController: WKInterfaceController {
@IBOutlet weak var recordButton: WKInterfaceButton!
@IBOutlet weak var resultLabel: WKInterfaceLabel!
var engine: AVAudioEngine!
var webSocketTask: URLSessionWebSocketTask!
// マイクボタンのフラグ
var isStart = true
// 認識結果
var resultText = ""
override func awake(withContext context: Any?) {
// Configure interface objects here.
setup()
}
//
// MARK: - BUTTON
// マイクボタンタップで呼ばれる
@IBAction func tapRecord() {
if isStart {
resume()
start()
} else {
stop()
}
isStart = isStart ? false : true
}
// start record
func start() {
self.engine.prepare()
do {
try engine.start()
} catch {
return
}
}
// stop record
func stop() {
self.engine.stop()
}
//
// MARK: - AVAudioEngine
//
func setup() {
//
self.engine = AVAudioEngine()
// Convert AVAudioPCMBuffer to Data
//
func toData(buffer: AVAudioPCMBuffer) -> Data {
let channelCount = 1 // Given PCMBuffer channel count is 1
let channels = UnsafeBufferPointer(start: buffer.int16ChannelData, count: channelCount)
let ch0Data = NSData(bytes: channels[0], length: Int(buffer.frameCapacity * buffer.format.streamDescription.pointee.mBytesPerFrame)) as Data
return ch0Data
}
// 出力フォーマット
guard let outputFormat = AVAudioFormat(commonFormat: .pcmFormatInt16, sampleRate: 16000, channels: AVAudioChannelCount(1), interleaved: true) else {
return
}
// 入力フォーマット
let inputFormat = self.engine.inputNode.outputFormat(forBus: 0)
// 変換器
let converter = AVAudioConverter(from: inputFormat, to: outputFormat)
//
self.engine.inputNode.installTap(onBus: AVAudioNodeBus(0), bufferSize: AVAudioFrameCount(3200), format: inputFormat) { (pcmBuffer, time) in
//
let inputBlock: AVAudioConverterInputBlock = { inNumPackets, onStatus in
onStatus.pointee = .haveData
return pcmBuffer
}
let sampleRateRatio = 16000/inputFormat.sampleRate
let outputFrameCapacity = AVAudioFrameCount(Double(pcmBuffer.frameCapacity) * sampleRateRatio)
guard let outputBuffer = AVAudioPCMBuffer(pcmFormat: outputFormat, frameCapacity: outputFrameCapacity) else {
return
}
var error: NSError? = nil
// convert input format to output format
converter?.convert(to: outputBuffer, error: &error, withInputFrom: inputBlock)
// サーバーにデータを送信する
send(data: toData(buffer: outputBuffer))
}
}
//
//
//
func disconnect() {
// 'e'コマンド
let sendText = "e"
// 'e'コマンドパケットを送信
webSocketTask.send(.string(sendText)) { error in
if let error = error {
print("WebSocket sending error: \(error)")
}
}
}
func send(data: Data) {
// 端末のマイク入力から取得した音声データ
var data_ = data
// 先頭にpのアスキーコードを挿入
data_.insert(0x70, at:0)// p
// データ型で送信
webSocketTask.send(.data(data_)) { error in
if let error = error {
print("WebSocket sending error: \(error)")
}
}
}
func resume() {
let session = URLSession(configuration: .default, delegate: self, delegateQueue: OperationQueue.main)
guard let url = URL(string: "wss://acp-api.amivoice.com/v1/") else { return }
webSocketTask = session.webSocketTask(with: url)
webSocketTask.resume()
// 's'コマンド
let sendText = "s LSB16K -a-general authorization=(AppKey)"
// 's'コマンドの送信
webSocketTask.send(.string(sendText)) { error in
if let error = error {
print("WebSocket sending error: \(error)")
}
}
receiveWebSocket()
}
func receiveWebSocket() { // 送信したデータに対してのレスポンスを受ける
webSocketTask.receive { [self] result in
switch result {
case .failure(let error):
print("Failed to receive message: \(error)")
case .success(let message):
switch message {
case .string(let text):
classify(text: text)
@unknown default:
fatalError()
}
// .receiveは一度しか呼ばれないため、再起的に呼び出す必要がある
self.receiveWebSocket()
}
}
}
func classify(text: String) {
print("text: ", text)
var command = text
var body = ""
// 受信したテキストをコマンドとボディに分ける
if let targetIdx = text.firstIndex(of: " ") {
command = String(text[text.startIndex..<targetIdx])
body = String(text[text.index(targetIdx, offsetBy: 1)..<text.endIndex])
}
switch command {
// コマンドが's'
case "s":
if body != "" {
print("s error: ", body)
}
break
// コマンドが'p'
case "p":
if body != "" {
print("p error: ", body)
}
break
// コマンドが'e'
case "e":
if body != "" {
print("e error: ", body)
}
break
// コマンドが'A'
case "A":
print("-> A")
let data = body.data(using: .utf8)!
do {
// jsonをDictionary型に変換
let dic = try JSONSerialization.jsonObject(with: data, options: []) as? [String: Any]
// codeキーの値で認識成功の可否を判断する
let code = dic!["code"] as! String
if (code != "") {
print("Error: ", code)
return
}
// 認識結果を取得する
let res = dic!["text"] as! String
// 前回の認識結果に加算する
self.resultText += res + "\n"
// ラベルに加算した認識結果を代入する
self.resultLabel.setText(resultText)
} catch {
print(error.localizedDescription)
}
break
default:
break
}
}
}
参考
ACPについて
AVAudioEngine関連
Building Modern Audio Apps with AVAudioEngine
WebSocket関連
How to use the URLSessionWebSocketTask in Swift. Post WWDC deep-dive review.
この記事を書いた人
-
林政樹
Swiftを使ってiOS/WatchOSアプリの開発をしています
よく見られている記事



新着記事
-
AmiVoice APIアップデート解説 End-to-End対応の「単語強調」機能

-
動画に字幕を簡単合成!音声認識APIで作る字幕ワークフロー

-
AmiVoiceの単語登録APIで音声認識をもっと自由に!

カテゴリ一覧
アーカイブ
